- Задачи классификации и регрессии. Технологии обработки данных

Содержание
- 2. Технологии обработки данных Knowledge Discovery in Databases (KDD) – процесс получения из данных знаний в виде
- 3. Методы DM Классификация – установление зависимости дискретной выходной переменной от входных. Кластеризация – группировка объектов на
- 4. Решение задач классификации Логистическая регрессия Метод опорных векторов Деревья решений Байесовские алгоритмы
- 5. Задача классификации данных Задача классификации формулируется следующим образом. Имеется множество объектов Каждый объект характеризуется набором свойств
- 6. Метод опорных векторов Рассмотрим задачу бинарной классификации. Имеющийся набор данных содержит два класса Требуется построить поверхность,
- 7. Уравнение разделительной гиперплоскости в пространстве переменных представим в виде а линейный пороговый классификатор Коэффициенты подбираются в
- 8. На рис. представлены два класса в двумерном пространстве. Класс черные точки светлые точки. Видно, что прямая
- 9. Коэффициенты можно пронормировать таким образом, чтобы в точках, ближайших к разделяющей классы полосе. В остальных точках
- 11. Если в данных присутствует существенная нелинейность, то решение задачи не приводит к правильной классификации. На рисунке
- 12. Выражение для классификатора Практически используются следующие функции ядра: .
- 13. Для примера на рис. представлена выборка из 190 точек. Нелинейное разделение с радиальным ядром Опорные вектора
- 14. Байесовские классификаторы
- 22. Последовательность действий
- 31. ,
- 33. Метод классификации, основанный на деревьях решений Деревья решений - это способ представления правил в иерархической, последовательной
- 34. - вероятность принадлежности классу k по атрибуту i и q-му пороговому значению - вероятность попадания в
- 35. 0 if X[1] >= 0.36 AND X[0] >= 1.64 then Y= 1 1 if X[0] >=
- 36. 0 if X[1] >= 1.39 then Y= 0 1 if X[1] = -1.52 AND X[0] >=
- 38. Скачать презентацию

Технологии обработки данных
Knowledge Discovery in Databases (KDD) – процесс получения из
Технологии обработки данных
Knowledge Discovery in Databases (KDD) – процесс получения из

Методы DM
Классификация – установление зависимости дискретной выходной переменной от входных.
Кластеризация –
Методы DM
Классификация – установление зависимости дискретной выходной переменной от входных.
Кластеризация –

Решение задач классификации
Логистическая регрессия
Метод опорных векторов
Деревья решений
Байесовские алгоритмы
Решение задач классификации
Логистическая регрессия
Метод опорных векторов
Деревья решений
Байесовские алгоритмы

Задача классификации данных
Задача классификации формулируется следующим образом.
Имеется множество объектов
Каждый
Задача классификации данных
Задача классификации формулируется следующим образом.
Имеется множество объектов
Каждый

Метод опорных векторов
Рассмотрим задачу бинарной классификации. Имеющийся набор данных
содержит
Метод опорных векторов
Рассмотрим задачу бинарной классификации. Имеющийся набор данных
содержит

Уравнение разделительной гиперплоскости в пространстве переменных
представим в виде
а линейный
Уравнение разделительной гиперплоскости в пространстве переменных
представим в виде
а линейный
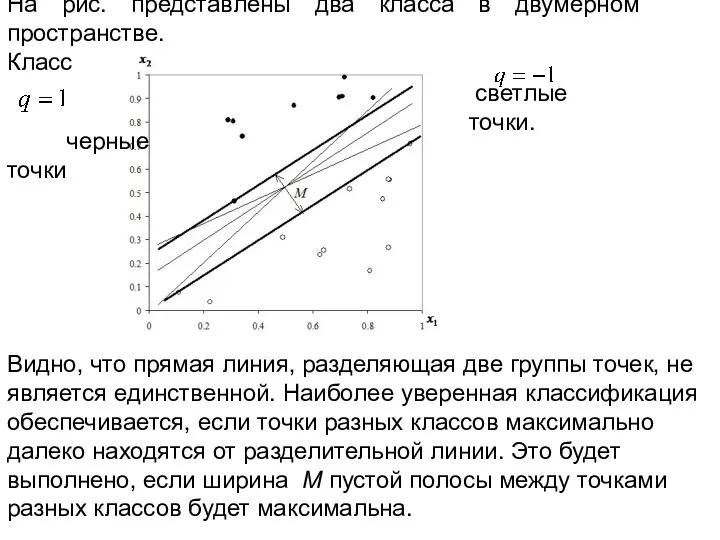
На рис. представлены два класса в двумерном пространстве.
Класс
черные
На рис. представлены два класса в двумерном пространстве.
Класс
черные

Коэффициенты
можно пронормировать таким образом, чтобы
в точках, ближайших к
Коэффициенты
можно пронормировать таким образом, чтобы
в точках, ближайших к


Если в данных присутствует существенная нелинейность,
то решение задачи не приводит
Если в данных присутствует существенная нелинейность,
то решение задачи не приводит

Выражение для классификатора
Практически используются следующие функции ядра:
.
Выражение для классификатора
Практически используются следующие функции ядра:
.

Для примера на рис. представлена выборка из 190 точек.
Нелинейное разделение
Для примера на рис. представлена выборка из 190 точек.
Нелинейное разделение

Байесовские классификаторы
Байесовские классификаторы



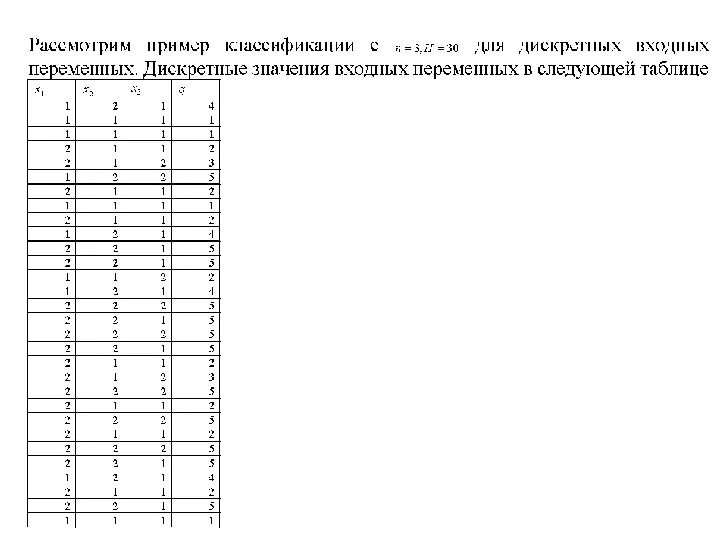

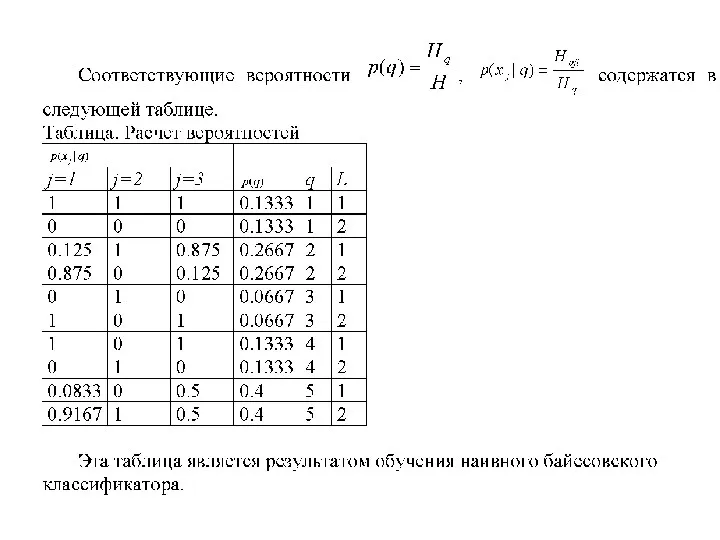
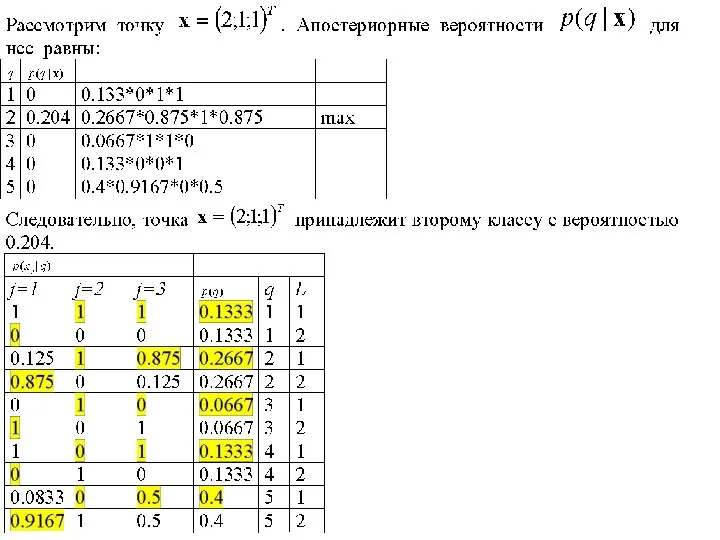

Последовательность действий
Последовательность действий


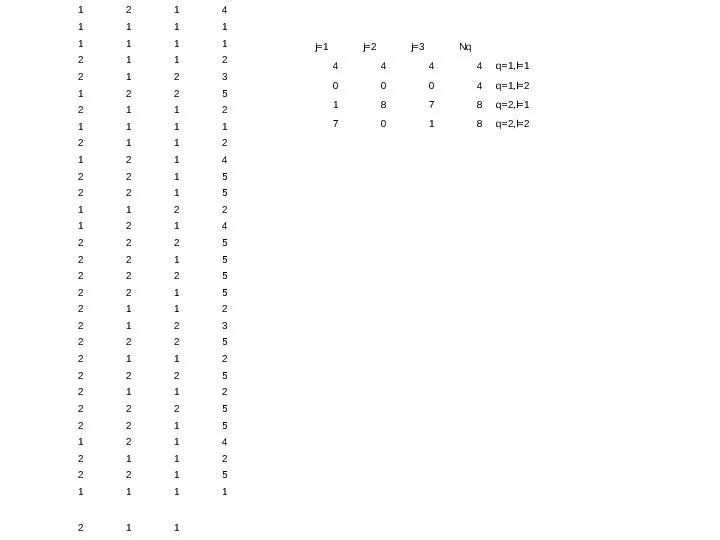
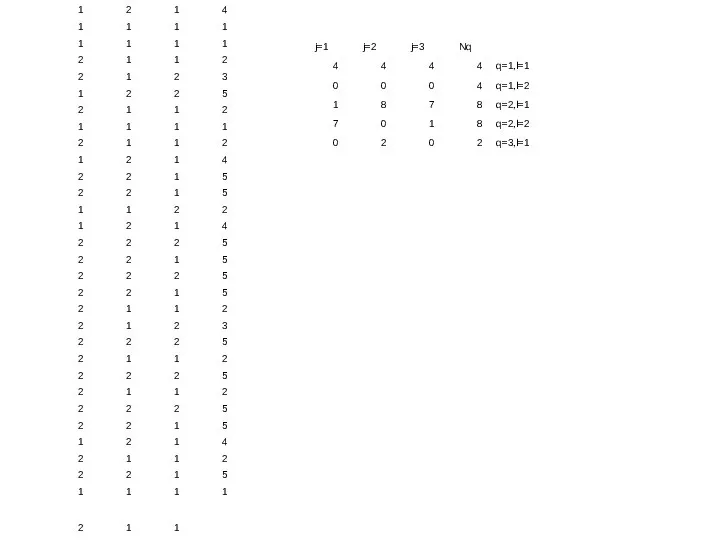
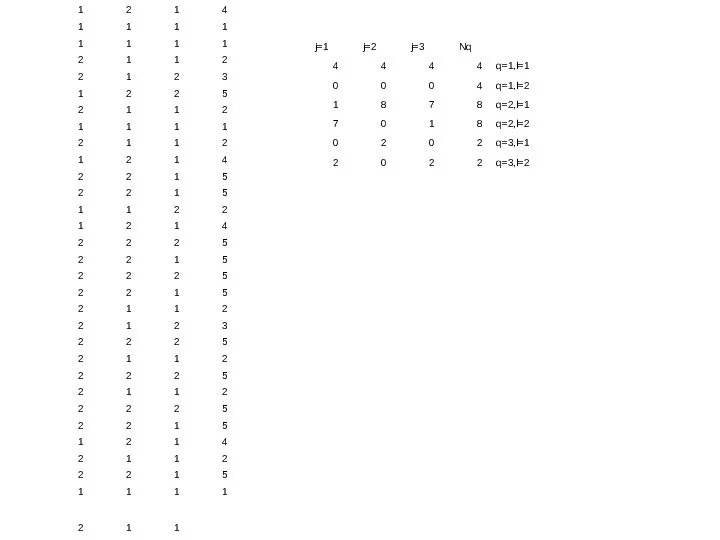
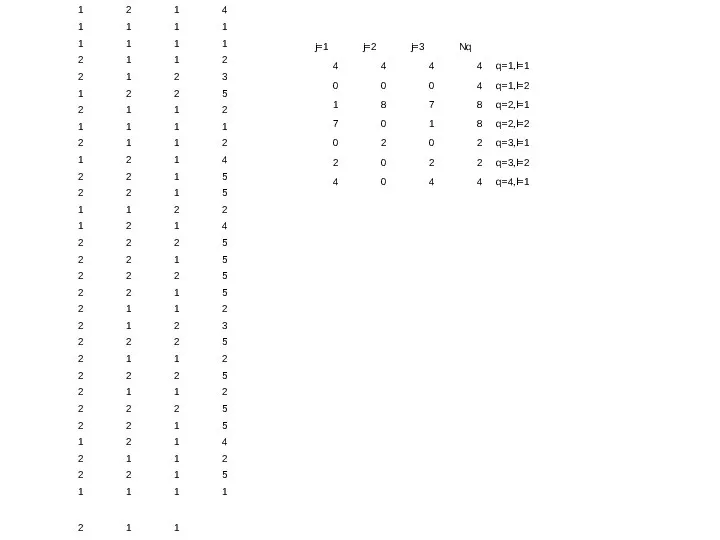
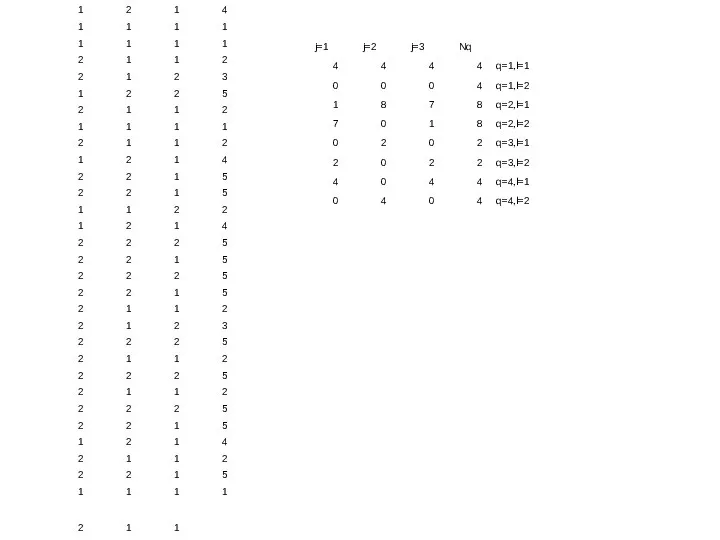
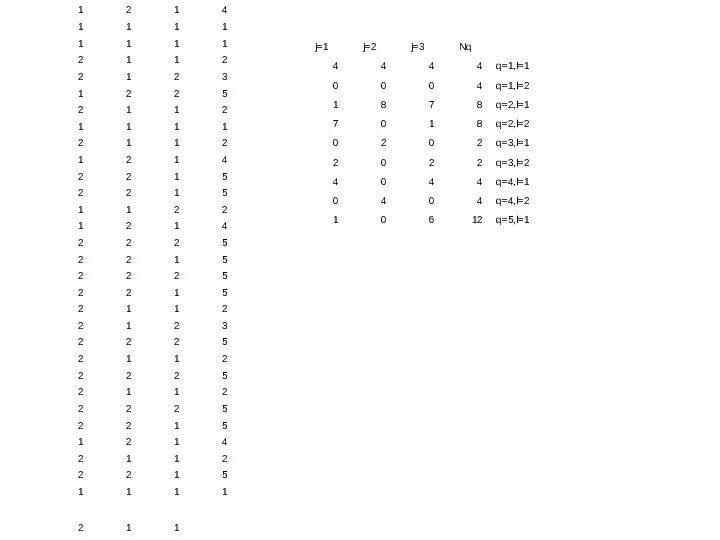

,
,

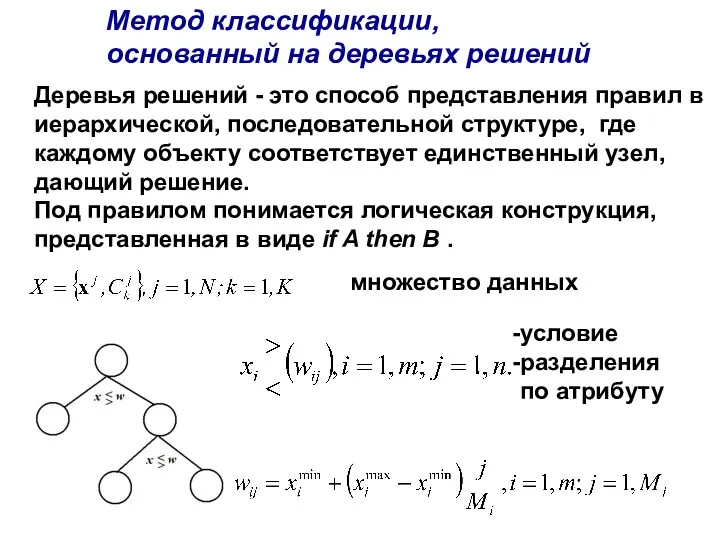
Метод классификации,
основанный на деревьях решений
Деревья решений - это способ представления
Метод классификации,
основанный на деревьях решений
Деревья решений - это способ представления

- вероятность принадлежности
классу k по атрибуту i
и q-му
- вероятность принадлежности
классу k по атрибуту i
и q-му
![0 if X[1] >= 0.36 AND X[0] >= 1.64 then](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/364300/slide-34.jpg)
0 if X[1] >= 0.36 AND X[0] >= 1.64 then Y=
0 if X[1] >= 0.36 AND X[0] >= 1.64 then Y=
![0 if X[1] >= 1.39 then Y= 0 1 if](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/364300/slide-35.jpg)
0 if X[1] >= 1.39 then Y= 0
1 if X[1] <
0 if X[1] >= 1.39 then Y= 0
1 if X[1] <
 The app is a notification and alert app with a basic points and reward database, and an analysis section to record app data
The app is a notification and alert app with a basic points and reward database, and an analysis section to record app data Опыт внедрения BDD в разработку
Опыт внедрения BDD в разработку Виды прерываний и методы обработки современных компьютерах
Виды прерываний и методы обработки современных компьютерах Задачи на скорость передачи информации. 8 класс
Задачи на скорость передачи информации. 8 класс Памятка пользователя Личного кабинета
Памятка пользователя Личного кабинета Условный оператор
Условный оператор Компьютерные технологии в науке и образовании
Компьютерные технологии в науке и образовании Базы данных Всероссийского института научной и технической информации ВИНИТИ РАН
Базы данных Всероссийского института научной и технической информации ВИНИТИ РАН Creating and Tuning Indexes CQG Ukraine Internship Program 2010
Creating and Tuning Indexes CQG Ukraine Internship Program 2010 Поколение ЭВМ
Поколение ЭВМ Основные сведения. Предпосылки появления баз данных
Основные сведения. Предпосылки появления баз данных Средства мультимедиа
Средства мультимедиа Програмне забезпечення для Peer-To-Peer Lending платформи
Програмне забезпечення для Peer-To-Peer Lending платформи Знакомство с Word
Знакомство с Word Инструкция по обновлению BIOS для win7
Инструкция по обновлению BIOS для win7 Функции в Excel
Функции в Excel МБУК Центральная библиотека МР Благоварский район
МБУК Центральная библиотека МР Благоварский район Компьютерная графика (Autodesk 3ds max). Лекция 9.1. Настройка освещения в сцене (Standard, VRay)
Компьютерная графика (Autodesk 3ds max). Лекция 9.1. Настройка освещения в сцене (Standard, VRay) Консолидация. Занятие 10
Консолидация. Занятие 10 Алгоритм. Свойства алгоритма
Алгоритм. Свойства алгоритма Статистическое кодирование сообщений
Статистическое кодирование сообщений Сборка ПК
Сборка ПК Управление показом презентации
Управление показом презентации Помехоустойчивое кодирование. Другие важные линейные и циклические коды
Помехоустойчивое кодирование. Другие важные линейные и циклические коды Программирование задач с использованием одномерных массивов
Программирование задач с использованием одномерных массивов Линейное и нелинейное программирование в задачах ЕГЭ
Линейное и нелинейное программирование в задачах ЕГЭ Разработка и реализация базы данных Телефонная станция
Разработка и реализация базы данных Телефонная станция Склеивание мешков цепочек
Склеивание мешков цепочек