- Creating and Tuning Indexes CQG Ukraine Internship Program 2010

Содержание
- 2. Индексы – Теоретические основы Кучи и Индексы Кластерный индекс Не кластерный индекс Составной ключ Уникальные индексы
- 3. Кучи и Индексы SELECT * FROM Customers WHERE CustomerID = “ROMEY” (table scan – сканирование таблицы)
- 4. Достоинства и недостатки индексов Функции увеличение скорости доступа к данным поддержка уникальности данных Недостатки занимают дополнительное
- 5. B-деревья (B-tree) … Where CustomerID = ‘ROMEY’ будут прочитаны только страницы 30, 22 и 10 в
- 6. Кластерный индекс leaf level этого индекса есть сами страницы таблицы с данными Может быть только один
- 7. Не кластерный индекс
- 8. Некластерный индекс поверх кластерного
- 9. Составной ключ Длина ключа индекса не должна превышать 900 байт 16 столбцов Уникальные индексы Unique constrain
- 10. Доступ к записям при наличии или отсутствии индексов Сканирование таблицы. Выборка данных по кластерному индексу Выборка
- 12. Создание индекса TSQL CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name ON (
- 13. Параметры ASC|DESC INCLUDE ( column [ ,... n ] ) – 1023 до 2 ГБ WITH
- 14. Информация об индексах sp_helpindex ‘Orders’ SELECT indid, name, first, root, dpages, rowcnt FROM sysindexes WHERE id=OBJECT_ID(‘Orders’)
- 15. Статистика и выбор индексов Что из себя представляет статистика dbcc show_statistics Выбор индексов Создание и обновление
- 16. Статистика DBCC SHOW_STATISTICS (N'Person', LastName)
- 18. Скачать презентацию

Индексы – Теоретические основы
Кучи и Индексы
Кластерный индекс
Не кластерный индекс
Составной ключ
Уникальные индексы
Доступ
Индексы – Теоретические основы
Кучи и Индексы
Кластерный индекс
Не кластерный индекс
Составной ключ
Уникальные индексы
Доступ
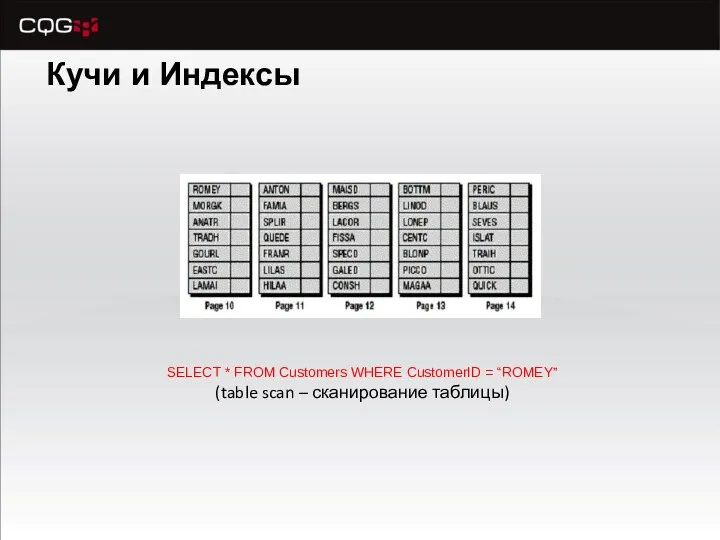
Кучи и Индексы
SELECT * FROM Customers WHERE CustomerID = “ROMEY”
(table scan
Кучи и Индексы
SELECT * FROM Customers WHERE CustomerID = “ROMEY”
(table scan

Достоинства и недостатки индексов
Функции
увеличение скорости доступа к данным
поддержка уникальности данных
Недостатки
занимают дополнительное
Достоинства и недостатки индексов
Функции
увеличение скорости доступа к данным
поддержка уникальности данных
Недостатки
занимают дополнительное

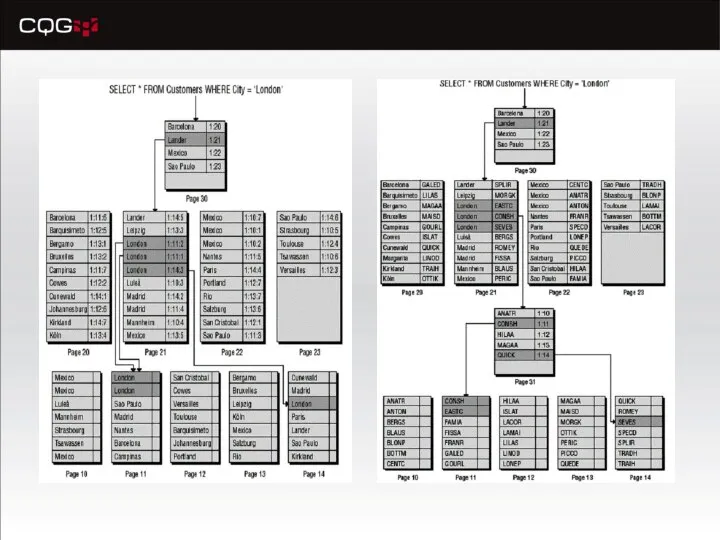
B-деревья (B-tree)
… Where CustomerID = ‘ROMEY’
будут прочитаны только страницы 30, 22
B-деревья (B-tree)
… Where CustomerID = ‘ROMEY’
будут прочитаны только страницы 30, 22
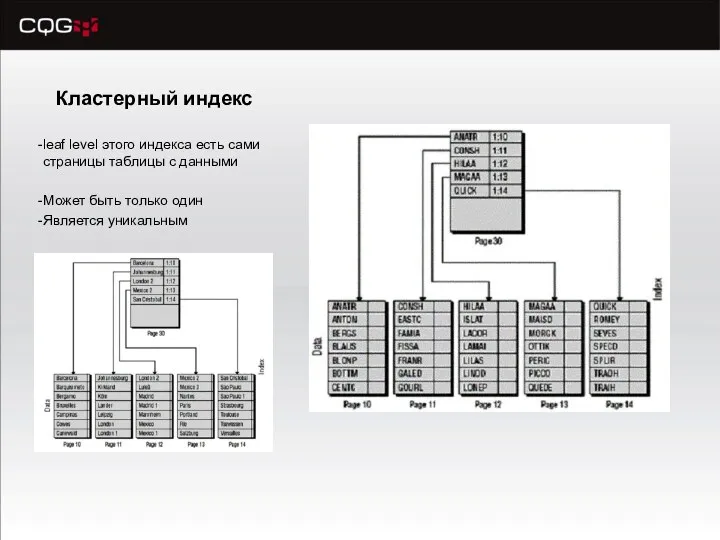
Кластерный индекс
leaf level этого индекса есть сами страницы таблицы с данными
Может
Кластерный индекс
leaf level этого индекса есть сами страницы таблицы с данными
Может
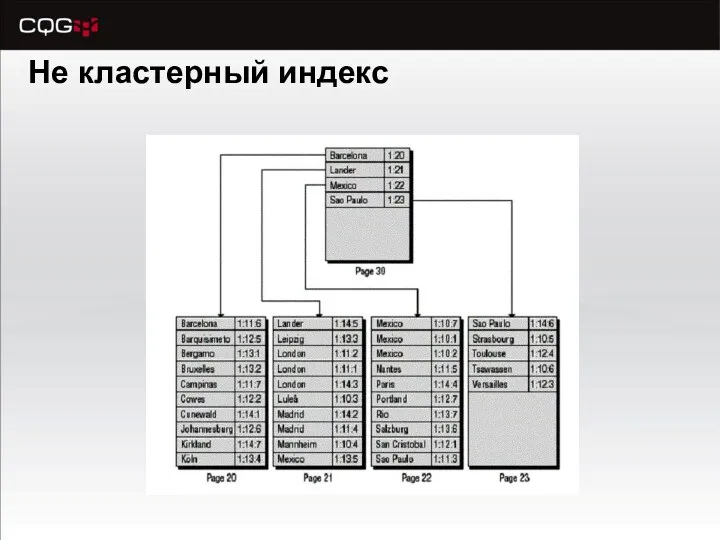
Не кластерный индекс
Не кластерный индекс
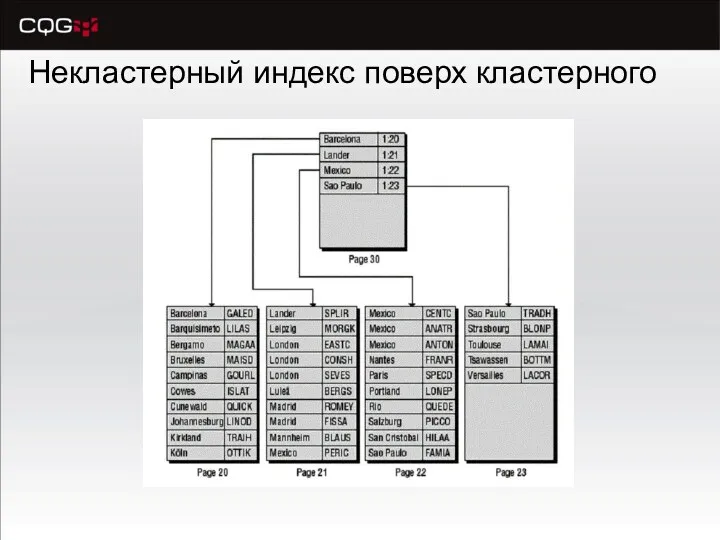
Некластерный индекс поверх кластерного
Некластерный индекс поверх кластерного

Составной ключ
Длина ключа индекса не должна превышать 900 байт
16 столбцов
Уникальные индексы
Unique
Составной ключ
Длина ключа индекса не должна превышать 900 байт
16 столбцов
Уникальные индексы
Unique

Доступ к записям при наличии или отсутствии индексов
Сканирование таблицы.
Выборка данных по
Доступ к записям при наличии или отсутствии индексов
Сканирование таблицы.
Выборка данных по
![Создание индекса TSQL CREATE [ UNIQUE ] [ CLUSTERED |](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/311990/slide-11.jpg)
Создание индекса TSQL
CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ]
Создание индекса TSQL
CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ]
![Параметры ASC|DESC INCLUDE ( column [ ,... n ] )](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/311990/slide-12.jpg)
Параметры
ASC|DESC
INCLUDE ( column [ ,... n ] ) – 1023 до
Параметры
ASC|DESC
INCLUDE ( column [ ,... n ] ) – 1023 до

Информация об индексах
sp_helpindex ‘Orders’
SELECT indid, name, first, root, dpages, rowcnt FROM
Информация об индексах
sp_helpindex ‘Orders’
SELECT indid, name, first, root, dpages, rowcnt FROM

Статистика и выбор индексов
Что из себя представляет статистика
dbcc show_statistics
Выбор индексов
Создание и
Статистика и выбор индексов
Что из себя представляет статистика
dbcc show_statistics
Выбор индексов
Создание и

Статистика
DBCC SHOW_STATISTICS (N'Person', LastName)
Статистика
DBCC SHOW_STATISTICS (N'Person', LastName)
 Автоматическая обработка информации
Автоматическая обработка информации Искусственные нейронные сети
Искусственные нейронные сети Презентация Основные типы данных языка программирования Паскаль
Презентация Основные типы данных языка программирования Паскаль Фейк-ньюс и фактчекинг
Фейк-ньюс и фактчекинг Основы алгоритмизации и объектно-ориентированного программирования
Основы алгоритмизации и объектно-ориентированного программирования Программное обеспечение. Что такое программное обеспечение?
Программное обеспечение. Что такое программное обеспечение? Основні етапи розвитку обчислювальної техніки
Основні етапи розвитку обчислювальної техніки Курс С#. Программирование на языке высокого уровня
Курс С#. Программирование на языке высокого уровня Hyper Text Markup Language - Язык разметки гипертекста
Hyper Text Markup Language - Язык разметки гипертекста Технологии сбора информации и больших объемов данных (лекция 3)
Технологии сбора информации и больших объемов данных (лекция 3) ОУ Новоселецкая школа. Навигатор дополнительного образования Омской области
ОУ Новоселецкая школа. Навигатор дополнительного образования Омской области Основы логики и логические основы компьютера
Основы логики и логические основы компьютера Операционная система Windows
Операционная система Windows Текстовые редакторы
Текстовые редакторы PicasaWeb 3.0
PicasaWeb 3.0 Компоненты ЛВС. Сетевое оборудование
Компоненты ЛВС. Сетевое оборудование Ауқымды желі интернеттің жалпы сипаттамасы
Ауқымды желі интернеттің жалпы сипаттамасы Тест по информатике для учеников 8 класса по теме Клавиатура
Тест по информатике для учеников 8 класса по теме Клавиатура Составление программ на алгоритмическом языке, отладка, тестирование, анализ результатов. 2-3 урок
Составление программ на алгоритмическом языке, отладка, тестирование, анализ результатов. 2-3 урок МТС Касса
МТС Касса Физический уровень модели OSI. Лекция 3
Физический уровень модели OSI. Лекция 3 Активизация мыслительной деятельности воспитанников на уроках физики с использованием ИКТ
Активизация мыслительной деятельности воспитанников на уроках физики с использованием ИКТ Создание учебных курсов в системе Moodle
Создание учебных курсов в системе Moodle Программа Модуль Слежения 2.0 на платформе 1С:Предприятие 8.3
Программа Модуль Слежения 2.0 на платформе 1С:Предприятие 8.3 Информационные технологии в строительстве. Вычислительные комплексы в расчетах строительных конструкций
Информационные технологии в строительстве. Вычислительные комплексы в расчетах строительных конструкций Программирование (Python)
Программирование (Python) Adobe Photoshop. Рабочее окно и панель инструментов
Adobe Photoshop. Рабочее окно и панель инструментов Introduction to computer systems. Architecture of computer systems. Компьютерлік жүйелерге кіpicne
Introduction to computer systems. Architecture of computer systems. Компьютерлік жүйелерге кіpicne