- Ekonometria- wykład 2, 3. Estymacja i weryfikacja modelu

Содержание
- 2. Model regresji liniowej W przypadku, gdy funkcja f z powyższej zależności jest funkcją liniową, model przyjmuje
- 3. ROWNOWAŻNE POJĘCIA EKONOMETRYCZNE • Zmienna Y nazywana jest : – Zmienną zależną – Zmienną objaśnianą –
- 4. Interpretacja: Jeżeli zmienna egzogeniczna xt1 wzrośnie o 1 jednostkę, a pozostałe zmienne objaśniające nie ulegną zmianie,
- 6. Estymacja modelu - MNK Oszacować (estymować) model oznacza znaleźć oceny parametrów strukturalnych na podstawie konkretnej próby
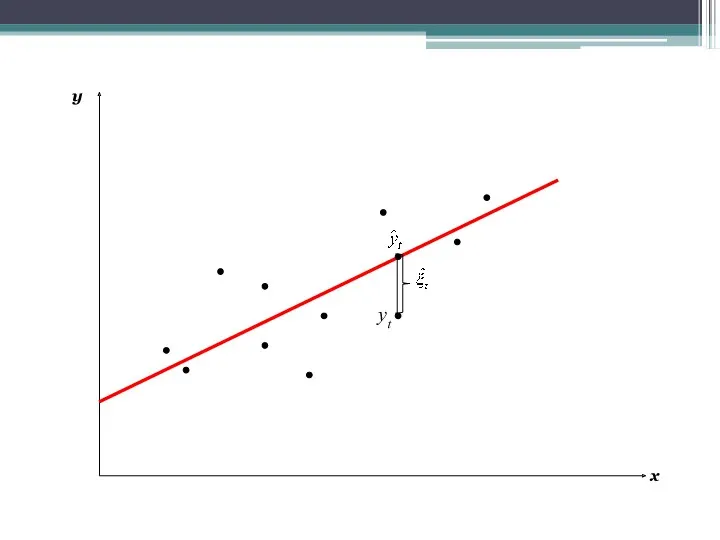
- 7. x y yt
- 8. Metody szacowania parametrów strukturalnych: - Metoda Najmniejszych Kwadratów (MNK) Metoda Momentów (MM), Metoda Największej Wiarygodności (MNW),
- 9. Założenia modelu regresji liniowej (założenia Gaussa-Markowa) Postać funkcji regresji jest liniowa i stała, tzn. relacja między
- 10. Składnik losowy ma rozkład normalny o średniej równej 0 i stałym odchyleniu standardowym, nie występuje autokorelacja
- 11. Metoda Najmniejszych Kwadratów (MNK) Im mniejsza jest odległość wartości rzeczywistych od teoretycznych tym lepszy model estymatory
- 12. Własności estymatorów MNK - Nieobciążoność - Efektywność - Zgodność
- 13. Weryfikacja jednorównaniowego liniowego modelu ekonometrycznego ocena merytoryczna (stwierdzenie, czy otrzymane wyniki estymacji zgodne są z pewnymi
- 14. Weryfikacja merytoryczna 1. określenie poprawności znaków przy parametrach; 2. interpretacja wartości oszacowanych parametrów (inaczej interpretuje się
- 15. Weryfikacja statystyczna Ocena stopnia dopasowania modelu – (parametry struktury stochastycznej modelu) współczynnik determinacji R2. Jest to
- 16. Współczynnik determinacji: określa, jaka część zmienności cechy zależnej jest wyjaśniona zmiennością cech niezależnych. Pewna część zmienności
- 17. - wariancja resztowa Miarą przeciętnej wielkości błędu dopasowania jest wariancja resztowa, która jest oceną wariancji składnika
- 18. przeciętny błąd szacunku parametru S(aj). Przedział ufności dla parametru gdzie 1-alfa jest współczynnikiem ufności, a talfa
- 19. Ocena istotności Sprawdzianem jest statystyka: Statystyka ma rozkład t-Studenta o n-k-1 stopniach swobody.
- 20. 1. Jeżeli |t(aj)| > tkryt wówczas (przy przyjętym z góry poziomie istotności) odrzucamy H0 na korzysc
- 22. Modele nieliniowe Model potęgowy Ogólny zapis statycznego modelu potęgowego
- 23. Parametry strukturalne w modelu potęgowym są elastycznościami cząstkowymi. Jest to model o stałych elastycznościach. Interpretacja: Jeżeli
- 24. Linearyzacja modelu potęgowego
- 26. Funkcja potęgowa to często wykorzystywany model: -ekonometryczna funkcja produkcji Cobba-Douglasa - ekonometryczna funkcja popytu
- 27. Model produkcji Funkcja produkcji wyraża zależność między nakładami czynników produkcji (kapitału i pracy) a wielkością (wartością)
- 28. Funkcja Cobba-Douglasa Jest to potęgowa postać funkcji produkcji. Dla dwóch czynników produkcji K i L mamy
- 29. Modele popytu Funkcja popytu wyraża zależność poziomu popytu od czynników ekonomicznych i pozaekonomicznych. Główne czynniki ekonomiczne:
- 30. Elastyczności (E) Elastyczność dochodowa popytu jest zwykle dodatnia, elastyczność cenowa (względem ceny badanego produktu) jest zazwyczaj
- 31. makro- i mikroekonomiczne funkcje popytu Makroekonomiczne funkcje popytu mierzą popyt dla ludności na większym obszarze (regionu,
- 32. Mikroekonomiczne funkcje popytu wyrażają zależność popytu na określony produkt dla pojedynczych konsumentów lub gospodarstw w zależności
- 33. Model liniowy y – popyt (konsumpcja), x – dochód Funkcja potęgowa Model hiperboliczny Funkcja wykładnicza z
- 34. Weryfikacja stochastyczna- Własności składnika losowego brak autokorelacji składników losowych. stałość wariancji składników losowych. normalność rozkładu składnika
- 35. Własności składnika losowego Złamanie założeń o własnościach składnika losowego może mieć postać: autokorelacji, czyli korelacji między
- 36. Autokorelacja autokorelacja składnika losowego to korelacja między składnikami losowymi modelu autokorelacja między εt a εt-k określana
- 37. Autokorelacja: przyczyny natura procesów gospodarczych: skutki decyzji i zdarzeń ekonomicznych często rozciągają się na wiele miesięcy
- 38. jeżeli spełnione są założenia KMNK, w szczególności założenie o normalności rozkładu składnika losowego, reszty powinny być
- 39. A) Autokorelacja składników losowych Autokorelacja w modelu może być autokorelacją dodatnią: Wtedy, gdy obok siebie występować
- 40. A) Autokorelacja składników losowych Autokorelacja w modelu może być autokorelacją ujemną: Wtedy, gdy obok siebie występują
- 41. dodatnia autokorelacja jest znacznie częściej występującą formą autokorelacji, niż autokorelacja ujemna. Jest ona powszechnym zjawiskiem w
- 42. Autokorelacja: test Durbina-Watsona (DW) bardzo prosty test autokorelacji obciążony licznymi wadami: można go zastosować wyłącznie do
- 43. Autokorelacja: test DW – cd. H0: ρ =0 H1: ρ >0, lub ρ statystyka empiryczna: z
- 44. Autokorelacja: test mnożnika Lagrange’a (LM) bardzo ogólny test; nie dotyczą go ograniczenia testu DW procedura dwustopniowa;
- 45. Autokorelacja: co dalej? dodanie zmiennych objaśniających zmiana postaci analitycznej modelu zmiana metody estymacji – Uogólniona Metoda
- 46. D) Stałość wariancji składników losowych Homoskedastyczność – składniki losowe w modelu mają stałą wariancję. Heteroskedastyczność –
- 47. Heteroskedastyczność skutki heteroskedastyczności składnika losowego dla estymatorów MNK: estymatory są nieefektywne statystyki oparte na wariancjach (a
- 48. Heteroskedastyczność: przyczyny wśród podmiotów zróżnicowanych między sobą można się spodziewać dużej zmienności zachowań, co może znaleźć
- 49. Heteroskedastyczność: test White’a procedura dwustopniowa: wymaga oszacowania modelu pomocniczego statystyka testowa (postaci T⋅R2, gdzie R2 jest
- 50. Heteroskedastyczność: test Goldfelda-Quandta test dla modeli z 1 zmienną objaśniającą x wymaga arbitralnego podziału zbioru obserwacji
- 51. Heteroskedastyczność: co dalej? zmiana metody estymacji: Uogólniona Metoda Najmniejszych Kwadratów (UMNK), albo jej równoważnik ważona MNK:
- 52. C) Normalność rozkładu składnika losowego Stosując wszystkie powyższe testy zakładaliśmy, że badana zmienna, a zatem składnik
- 54. Do wszystkich testów statystycznych Prawdopodobieństwo empiryczne – p-value, wartość-p Jest to prawdopodobieństwo przyjęcia przez statystykę wartości
- 55. www. kufel.torun.pl
- 56. Funkcja tendencji rozwojowej (trendu) należy do szczególnej klasy modeli, w których w roli zmiennej objaśniającej występuje
- 57. Składowe szeregów czasowych Wyróżnia się cztery składowe mające wpływ na zmienność zjawiska w ujęciu dynamicznym: trend
- 58. Najczęściej stosowaną metodą wyodrębniania trendów jest metoda analityczna. funkcja matematyczna, w której zmienną zależną jest poziom
- 59. Najczęściej spotykaną w praktyce funkcją tendencji rozwojowej jest funkcja liniowa. Model szeregu czasowego ma wówczas postać:
- 60. Aby wykonac prognoze na podstawie jednorównaniowego modelu opisowego, musi on charakteryzowac sie dobrymi własnosciami. Jego jakosc
- 61. Same prognozy moga miec charakter punktowy (wynikiem jest konkretna wartosc liczbowa) lub przedziałowy (otrzymujemy przedział, który
- 63. Скачать презентацию

Model regresji liniowej
W przypadku, gdy funkcja f z powyższej zależności jest
Model regresji liniowej
W przypadku, gdy funkcja f z powyższej zależności jest

ROWNOWAŻNE POJĘCIA EKONOMETRYCZNE
• Zmienna Y nazywana jest :
– Zmienną zależną
– Zmienną
ROWNOWAŻNE POJĘCIA EKONOMETRYCZNE
• Zmienna Y nazywana jest :
– Zmienną zależną
– Zmienną

Interpretacja: Jeżeli zmienna egzogeniczna xt1 wzrośnie o 1 jednostkę, a pozostałe
Interpretacja: Jeżeli zmienna egzogeniczna xt1 wzrośnie o 1 jednostkę, a pozostałe


Estymacja modelu - MNK
Oszacować (estymować) model oznacza znaleźć oceny parametrów
Estymacja modelu - MNK
Oszacować (estymować) model oznacza znaleźć oceny parametrów
x
y
yt
x
y
yt

Metody szacowania parametrów strukturalnych:
- Metoda Najmniejszych Kwadratów (MNK)
Metoda Momentów (MM),
Metoda
Metody szacowania parametrów strukturalnych:
- Metoda Najmniejszych Kwadratów (MNK)
Metoda Momentów (MM),
Metoda

Założenia modelu regresji liniowej (założenia Gaussa-Markowa)
Postać funkcji regresji jest liniowa i
Założenia modelu regresji liniowej (założenia Gaussa-Markowa)
Postać funkcji regresji jest liniowa i

Składnik losowy ma rozkład normalny
o średniej równej 0 i stałym odchyleniu
Składnik losowy ma rozkład normalny
o średniej równej 0 i stałym odchyleniu

Metoda Najmniejszych Kwadratów (MNK)
Im mniejsza jest odległość wartości rzeczywistych od teoretycznych
Metoda Najmniejszych Kwadratów (MNK)
Im mniejsza jest odległość wartości rzeczywistych od teoretycznych

Własności estymatorów MNK
- Nieobciążoność
- Efektywność
- Zgodność
Własności estymatorów MNK
- Nieobciążoność
- Efektywność
- Zgodność

Weryfikacja jednorównaniowego liniowego modelu ekonometrycznego
ocena merytoryczna (stwierdzenie, czy otrzymane wyniki estymacji
Weryfikacja jednorównaniowego liniowego modelu ekonometrycznego
ocena merytoryczna (stwierdzenie, czy otrzymane wyniki estymacji

Weryfikacja merytoryczna
1. określenie poprawności znaków przy parametrach;
2. interpretacja wartości oszacowanych parametrów
(inaczej
Weryfikacja merytoryczna
1. określenie poprawności znaków przy parametrach;
2. interpretacja wartości oszacowanych parametrów
(inaczej

Weryfikacja statystyczna
Ocena stopnia dopasowania modelu – (parametry struktury stochastycznej modelu)
współczynnik determinacji
Weryfikacja statystyczna
Ocena stopnia dopasowania modelu – (parametry struktury stochastycznej modelu)
współczynnik determinacji

Współczynnik determinacji: określa, jaka część zmienności cechy zależnej jest wyjaśniona zmiennością
Współczynnik determinacji: określa, jaka część zmienności cechy zależnej jest wyjaśniona zmiennością

- wariancja resztowa
Miarą przeciętnej wielkości błędu dopasowania jest wariancja resztowa, która
- wariancja resztowa
Miarą przeciętnej wielkości błędu dopasowania jest wariancja resztowa, która

przeciętny błąd szacunku parametru S(aj).
Przedział ufności dla parametru
gdzie 1-alfa
przeciętny błąd szacunku parametru S(aj).
Przedział ufności dla parametru
gdzie 1-alfa

Ocena istotności
Sprawdzianem jest statystyka:
Statystyka ma rozkład t-Studenta o n-k-1 stopniach
Ocena istotności
Sprawdzianem jest statystyka:
Statystyka ma rozkład t-Studenta o n-k-1 stopniach

1. Jeżeli |t(aj)| > tkryt wówczas (przy przyjętym z góry poziomie
1. Jeżeli |t(aj)| > tkryt wówczas (przy przyjętym z góry poziomie


Modele nieliniowe
Model potęgowy
Ogólny zapis statycznego modelu potęgowego
Modele nieliniowe
Model potęgowy
Ogólny zapis statycznego modelu potęgowego

Parametry strukturalne w modelu potęgowym są elastycznościami cząstkowymi. Jest to model
Parametry strukturalne w modelu potęgowym są elastycznościami cząstkowymi. Jest to model

Linearyzacja modelu potęgowego
Linearyzacja modelu potęgowego


Funkcja potęgowa to często wykorzystywany model:
-ekonometryczna funkcja produkcji Cobba-Douglasa
- ekonometryczna
Funkcja potęgowa to często wykorzystywany model:
-ekonometryczna funkcja produkcji Cobba-Douglasa
- ekonometryczna

Model produkcji
Funkcja produkcji wyraża zależność między nakładami czynników produkcji (kapitału
Model produkcji
Funkcja produkcji wyraża zależność między nakładami czynników produkcji (kapitału

Funkcja Cobba-Douglasa
Jest to potęgowa postać funkcji produkcji. Dla dwóch czynników produkcji
Funkcja Cobba-Douglasa
Jest to potęgowa postać funkcji produkcji. Dla dwóch czynników produkcji

Modele popytu
Funkcja popytu wyraża zależność poziomu popytu od czynników ekonomicznych
Modele popytu
Funkcja popytu wyraża zależność poziomu popytu od czynników ekonomicznych

Elastyczności (E)
Elastyczność dochodowa popytu jest zwykle dodatnia,
elastyczność cenowa (względem
Elastyczności (E)
Elastyczność dochodowa popytu jest zwykle dodatnia,
elastyczność cenowa (względem

makro- i mikroekonomiczne funkcje popytu
Makroekonomiczne funkcje popytu
mierzą popyt dla ludności
makro- i mikroekonomiczne funkcje popytu
Makroekonomiczne funkcje popytu
mierzą popyt dla ludności

Mikroekonomiczne funkcje popytu
wyrażają zależność popytu na określony produkt dla pojedynczych
Mikroekonomiczne funkcje popytu
wyrażają zależność popytu na określony produkt dla pojedynczych

Model liniowy
y – popyt (konsumpcja), x – dochód
Funkcja potęgowa
Model hiperboliczny
Funkcja
Model liniowy
y – popyt (konsumpcja), x – dochód
Funkcja potęgowa
Model hiperboliczny
Funkcja

Weryfikacja stochastyczna- Własności składnika losowego
brak autokorelacji składników losowych.
stałość wariancji składników losowych.
normalność
Weryfikacja stochastyczna- Własności składnika losowego
brak autokorelacji składników losowych.
stałość wariancji składników losowych.
normalność

Własności składnika losowego
Złamanie założeń o własnościach składnika losowego może mieć postać:
autokorelacji,
Własności składnika losowego
Złamanie założeń o własnościach składnika losowego może mieć postać:
autokorelacji,

Autokorelacja
autokorelacja składnika losowego to korelacja między składnikami losowymi modelu
autokorelacja między εt
Autokorelacja
autokorelacja składnika losowego to korelacja między składnikami losowymi modelu
autokorelacja między εt

Autokorelacja: przyczyny
natura procesów gospodarczych: skutki decyzji i zdarzeń ekonomicznych często rozciągają
Autokorelacja: przyczyny
natura procesów gospodarczych: skutki decyzji i zdarzeń ekonomicznych często rozciągają

jeżeli spełnione są założenia KMNK, w szczególności założenie o normalności rozkładu
jeżeli spełnione są założenia KMNK, w szczególności założenie o normalności rozkładu

A) Autokorelacja składników losowych
Autokorelacja w modelu może być autokorelacją dodatnią:
Wtedy, gdy
A) Autokorelacja składników losowych
Autokorelacja w modelu może być autokorelacją dodatnią:
Wtedy, gdy

A) Autokorelacja składników losowych
Autokorelacja w modelu może być autokorelacją ujemną:
Wtedy, gdy
A) Autokorelacja składników losowych
Autokorelacja w modelu może być autokorelacją ujemną:
Wtedy, gdy

dodatnia autokorelacja jest znacznie częściej występującą formą autokorelacji, niż autokorelacja ujemna.
dodatnia autokorelacja jest znacznie częściej występującą formą autokorelacji, niż autokorelacja ujemna.

Autokorelacja:
test Durbina-Watsona (DW)
bardzo prosty test autokorelacji
obciążony licznymi wadami:
można go zastosować
Autokorelacja:
test Durbina-Watsona (DW)
bardzo prosty test autokorelacji
obciążony licznymi wadami:
można go zastosować

Autokorelacja: test DW – cd.
H0: ρ =0 H1: ρ >0, lub
Autokorelacja: test DW – cd.
H0: ρ =0 H1: ρ >0, lub

Autokorelacja: test mnożnika Lagrange’a (LM)
bardzo ogólny test; nie dotyczą go ograniczenia
Autokorelacja: test mnożnika Lagrange’a (LM)
bardzo ogólny test; nie dotyczą go ograniczenia

Autokorelacja: co dalej?
dodanie zmiennych objaśniających
zmiana postaci analitycznej modelu
zmiana metody estymacji –
Autokorelacja: co dalej?
dodanie zmiennych objaśniających
zmiana postaci analitycznej modelu
zmiana metody estymacji –
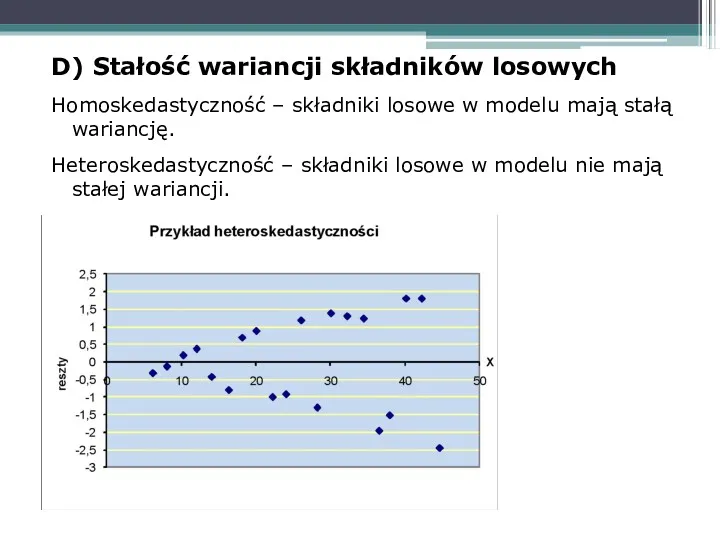
D) Stałość wariancji składników losowych
Homoskedastyczność – składniki losowe w modelu mają
D) Stałość wariancji składników losowych
Homoskedastyczność – składniki losowe w modelu mają

Heteroskedastyczność
skutki heteroskedastyczności składnika losowego dla estymatorów MNK:
estymatory są nieefektywne
statystyki oparte na
Heteroskedastyczność
skutki heteroskedastyczności składnika losowego dla estymatorów MNK:
estymatory są nieefektywne
statystyki oparte na

Heteroskedastyczność: przyczyny
wśród podmiotów zróżnicowanych między sobą można się spodziewać dużej zmienności
Heteroskedastyczność: przyczyny
wśród podmiotów zróżnicowanych między sobą można się spodziewać dużej zmienności

Heteroskedastyczność: test White’a
procedura dwustopniowa: wymaga oszacowania modelu pomocniczego
statystyka testowa (postaci
Heteroskedastyczność: test White’a
procedura dwustopniowa: wymaga oszacowania modelu pomocniczego
statystyka testowa (postaci

Heteroskedastyczność: test Goldfelda-Quandta
test dla modeli z 1 zmienną objaśniającą x
wymaga arbitralnego
Heteroskedastyczność: test Goldfelda-Quandta
test dla modeli z 1 zmienną objaśniającą x
wymaga arbitralnego

Heteroskedastyczność: co dalej?
zmiana metody estymacji:
Uogólniona Metoda Najmniejszych Kwadratów (UMNK), albo jej
Heteroskedastyczność: co dalej?
zmiana metody estymacji:
Uogólniona Metoda Najmniejszych Kwadratów (UMNK), albo jej

C) Normalność rozkładu składnika losowego
Stosując wszystkie powyższe testy zakładaliśmy, że badana
C) Normalność rozkładu składnika losowego
Stosując wszystkie powyższe testy zakładaliśmy, że badana


Do wszystkich testów statystycznych
Prawdopodobieństwo empiryczne – p-value, wartość-p
Jest to prawdopodobieństwo przyjęcia
Do wszystkich testów statystycznych
Prawdopodobieństwo empiryczne – p-value, wartość-p
Jest to prawdopodobieństwo przyjęcia
www. kufel.torun.pl
www. kufel.torun.pl

Funkcja tendencji rozwojowej (trendu) należy do szczególnej klasy modeli, w których
Funkcja tendencji rozwojowej (trendu) należy do szczególnej klasy modeli, w których

Składowe szeregów czasowych
Wyróżnia się cztery składowe mające wpływ na zmienność zjawiska
Składowe szeregów czasowych
Wyróżnia się cztery składowe mające wpływ na zmienność zjawiska

Najczęściej stosowaną metodą wyodrębniania trendów jest metoda analityczna.
funkcja matematyczna, w
Najczęściej stosowaną metodą wyodrębniania trendów jest metoda analityczna.
funkcja matematyczna, w

Najczęściej spotykaną w praktyce funkcją tendencji rozwojowej jest funkcja liniowa.
Model
Najczęściej spotykaną w praktyce funkcją tendencji rozwojowej jest funkcja liniowa.
Model

Aby wykonac prognoze na podstawie jednorównaniowego modelu opisowego, musi on charakteryzowac
sie
Aby wykonac prognoze na podstawie jednorównaniowego modelu opisowego, musi on charakteryzowac
sie

Same prognozy moga miec
charakter punktowy (wynikiem jest konkretna wartosc liczbowa) lub
Same prognozy moga miec
charakter punktowy (wynikiem jest konkretna wartosc liczbowa) lub
 Математическая викторина. Своя игра
Математическая викторина. Своя игра Многофакторный дисперсионный анализ. Основное различие многофакторного анализа от однофакторного. Эффекты взаимодействия
Многофакторный дисперсионный анализ. Основное различие многофакторного анализа от однофакторного. Эффекты взаимодействия Доказательство теоремы
Доказательство теоремы Вычитания с переходом через десяток
Вычитания с переходом через десяток Виды треугольников
Виды треугольников Математический аукцион. Задачи
Математический аукцион. Задачи Понятия теории графов
Понятия теории графов Статистическая проверка статистических гипотез
Статистическая проверка статистических гипотез Урок математики. Площадь (3 класс)
Урок математики. Площадь (3 класс) Решение задач с помощью уравнений
Решение задач с помощью уравнений Ох,уж эта математика! Команды Квадрат и Звезды
Ох,уж эта математика! Команды Квадрат и Звезды Развивающие игры-тренажеры из бросового материала для формирования математических способностей дошкольников
Развивающие игры-тренажеры из бросового материала для формирования математических способностей дошкольников Синтез оптимального керування для систем диференціальних рівнянь з інтегральним запізненням по аргументу та нефіксованим часом
Синтез оптимального керування для систем диференціальних рівнянь з інтегральним запізненням по аргументу та нефіксованим часом Математическая игра Колесо фортуны
Математическая игра Колесо фортуны Геодезия. Определение площадей
Геодезия. Определение площадей Додавання виду 45 + 3 (ознайомлення). Знаходження невідомого доданка. Аналіз умови задачі. Урок №116
Додавання виду 45 + 3 (ознайомлення). Знаходження невідомого доданка. Аналіз умови задачі. Урок №116 Вычеты. Основная теорема о вычетах
Вычеты. Основная теорема о вычетах Готовимся ЕГЭ. Тренажёр по теме Производная задание В8
Готовимся ЕГЭ. Тренажёр по теме Производная задание В8 Решение краевых задач для уравнений эллиптического вида, методом функций Грина
Решение краевых задач для уравнений эллиптического вида, методом функций Грина Трапеция. Виды трапеций
Трапеция. Виды трапеций Статистическая обработка данных. Повторение
Статистическая обработка данных. Повторение Признаки равенства прямоугольных треугольников. 7 класс
Признаки равенства прямоугольных треугольников. 7 класс Умножение разности двух выражений на их сумму
Умножение разности двух выражений на их сумму Четырехугольники 8 класс
Четырехугольники 8 класс Презентация Арифметические действия над числами
Презентация Арифметические действия над числами Координатная плоскость. 7 класс
Координатная плоскость. 7 класс Решение заданий В8 ЕГЭ по математике
Решение заданий В8 ЕГЭ по математике История происхождения дробей в разных странах
История происхождения дробей в разных странах