- Предварительная обработка экспериментальных данных

Содержание
- 2. Общие положения Объект исследования – это объект любого характера, который изучается экспериментальным путем. Эксперимент – это
- 3. Основным «рабочим инструментом» эксперимента и обработки экспериментальных данных является численное значение факторов воздействия и откликов объекта
- 4. Содержание предварительной обработки в основном состоит в отсеивании грубых погрешностей измерения или погрешностей, неизбежно имеющих место
- 5. Генеральная совокупность и выборка. Генеральной называют совокупность всех мыслимых наблюдений, которые могли бы быть сделаны при
- 6. Понятие бесконечной генеральной совокупности – математическая абстракция, как и представление о том, что измерить случайную величину
- 7. Выборка – любое конечное подмножество генеральной совокупности, предназначенное для непосредственных исследований, Объем – количество единиц в
- 8. Характеристики теоретических распределений можно рассматривать как характеристики, существующие в генеральной совокупности, а характеристики эмпирических распределений –
- 9. Исходными данными при оценивании, как и при проверке любых предположений (статистических гипотез), касающихся неизвестного распределения случайной
- 10. Оценивание – определение приближенного значения неизвестного параметра генеральной совокупности по результатам наблюдений. К оценкам предъявляются требования
- 11. Вычисление характеристик эмпирических распределений (выборочных характеристик). Здесь и в дальнейшем речь идет только о непрерывно распределенных
- 12. Величину называют дисперсией или вторым центральным моментом эмпирического распределения S2 = m2. В случае одномерного эмпирического
- 13. _ Несмещенную оценку для S 2 (или σ2 - дисперсия теоретического распределения) можно найти по формуле
- 14. Из других моментов чаще всего используют моменты третьего и четвертого порядка: Выборочное значение коэффициента вариации V,
- 15. Выборочные значения характеристик распределения имеет смысл вычислять только в случае, если выборка является случайной. Обычно на
- 16. Отсев грубых погрешностей. Можно встретить большое количество различных рекомендаций для проведения отсева грубых погрешностей наблюдения (аномальных
- 17. Таким образом, для выделения аномального значения вычисляют τ, которое затем сравнивают с табличным значением τ1-α. Если
- 18. Полигон и гистограмма частот распределения. Если полученные экспериментальные данные разделить на классы, то можно построить полигон
- 19. Затем устанавливают границы интервалов и подсчитывают число попаданий случайной величины в каждый из выбранных интервалов (абсолютные
- 20. Гистограмма и полигон распределений являются графическим отображением частот, которые, в свою очередь, представляют собой оценки плотностей
- 21. Нормальное распределение обладает и другими важными свойствами, которые позволяют считать это распределение основой математической статистики. Рассмотрим
- 22. Из формулы (16) следует, что нормальное распределение полностью определяется величинами μ и σ (π = 3,141593...
- 23. Примерно 2/3 всех наблюдений лежит в площади, отсекаемой перпендикулярами к оси Ох (μ ± σ). При
- 24. Медианой выборки является среднее значение из всего упорядоченного набора значений. Модой выборки называется значение, которое встречается
- 25. Проверка гипотезы нормальности распределения. Среднее абсолютное отклонение. Для небольших выборок (n Для этого необходимо вычислить среднее
- 26. Пользуясь САО, можно также с 95%-й доверительной вероятностью оценить µ (среднее значение теоретического распределения) по :
- 27. Размах варьирования R. Быструю проверку гипотезы нормальности распределения для сравнительно широкого класса выборок 3 Подсчитываем отношение
- 28. Показатели асимметрии и эксцесса. Некоторое представление о близости эмпирического распределения к нормальному может дать анализ показателей
- 29. Несмещенные оценки для показателей асимметрии G1 и эксцесса G2 определяют соответственно по формулам: Для проверки гипотезы
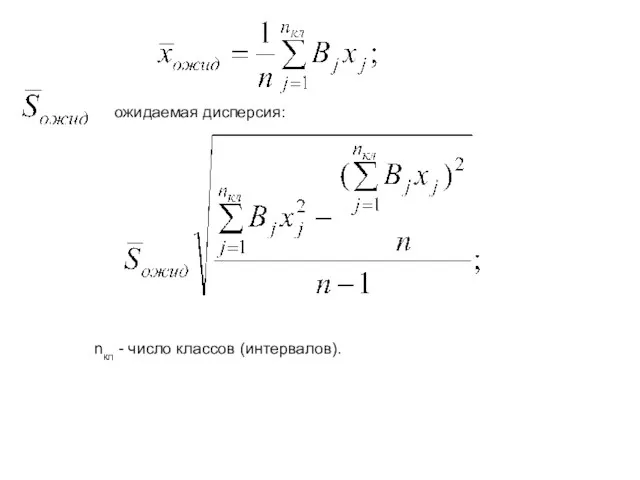
- 30. По критерию χ2 (хи-квадрат) Рассмотрим методику проверки гипотезы нормальности распределения по χ2 критерию. Применение критерия χ2
- 31. где f(zj) – уравнение кривой стандартного нормального распределения: zj – степень функции кривой нормального распределения: ожидаемое
- 32. ожидаемая дисперсия: nкл - число классов (интервалов).
- 33. Полученное значение χ2 сравнивают с табличным или критическим значением χ2 nкα,. Число степеней свободы v определяют
- 34. Методика проверки нормальности распределения по показателям асимметрии и эксцесса очень хорошо иллюстрирует использование моментов, а также
- 35. Особенности использования средств инструмента «Описательная статистика» в надстройке «Пакет анализа» MS Excel
- 36. В состав MS Excel входит надстройка «Пакет анализа», которая содержит 19 статистических процедур и около 50
- 37. Инструмент «Описательная статистика» (вместе с инструментом «Гистограмма», алгоритм использования которого будет описан далее) является наиболее часто
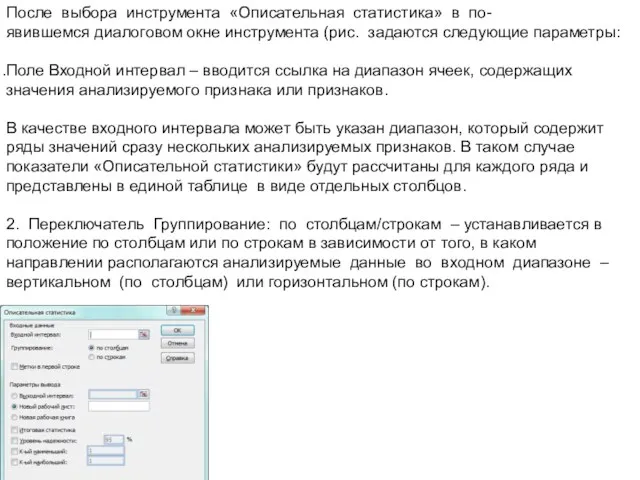
- 38. После выбора инструмента «Описательная статистика» в по- явившемся диалоговом окне инструмента (рис. задаются следующие параметры: Поле
- 39. Флажок Метки в первой строке – устанавливается в активное состояние, если первая строка во входном диапазоне
- 40. Флажок Уровень надежности – устанавливается в активное состояние, если в результативную таблицу необходимо включить строку для
- 41. Между терминологией инструмента «Описательная статистика» и терминами, принятыми в отечественной статистике, имеется ряд расхождений. Вычисленные значения
- 42. Появление в ячейке Мода индикатора ошибки #Н/Д указывает на то, что в анализируемых данных нет одинаковых
- 43. Особенности использования средств инструмента «Гистограмма» в надстройке «Пакет анализа» MS Excel В надстройке Excel «Пакет анализа»
- 44. определяет нижние границы интервалов; формирует интервальный вариационный ряд в соответствии с величинами k, h; рассчитывает частоты
- 45. статистическая интерпретация терминологии инструмента «Гистограмма» Термин инструмента «Гистограмма» Термин, принятый в статистике Карманы Интервалы вариационного ряда
- 46. Инструмент «Гистограмма» имеет два режима работы: режим автоматического формирования интервалов вариационного ряда, имеющих равную величину h;
- 47. Запуск инструмента «Гистограмма» осуществляется аналогично инструменту «Описательная статистика» надстройки «Пакет анализа». В появившемся диалоговом окне инструмента
- 48. 5. Переключатель Новый рабочий лист/Новая рабочая книга – открывает Новый рабочий лист/Новую рабочую книгу. Флажок Парето
- 49. Необходимо отметить, что инструменты «Пакет анализа» имеют определенные ограничения и иногда удобнее воспользоваться статистическими функциями или
- 50. пример выполнения Исходные данные демонстрационного примера: Данные наблюдения роста группы двадцатилетних юношей- студентов-третьекурсников (табл. 3). 1.
- 51. Определяем отсев грубых погрешностей. Для отсева погрешностей используем метод максимального относительного отклонения. Условие отсева Выбираем наибольший
- 52. Определяем другие статистические характеристики: коэффициент вариации по формуле коэффициент асимметрии по формуле Имеется также и небольшой
- 54. Полигон и гистограмма частот распределения Число классов k приблизительно можно вычислить по формуле Размах варьирования по
- 56. Выполняем проверку выборки на нормальность распределения по следующим критериям: – по среднему абсолютному отклонению САО условие
- 57. Коэффициент (0,71 ч 0,6) зависит от величины выборки n (в данном случае n = 15÷20) и
- 58. по коэффициентам асимметрии и эксцесса. Условия: где G1 - несмещенная оценка для показателя асимметрии G1 ≤
- 59. по критерию χ2 (свойства кривой нормального распределения) должно выполняться условие где Bj — абсолютная частота в
- 61. Скачать презентацию

Общие положения
Объект исследования – это объект любого характера, который изучается
Общие положения
Объект исследования – это объект любого характера, который изучается

Основным «рабочим инструментом» эксперимента и обработки экспериментальных данных является численное значение
Основным «рабочим инструментом» эксперимента и обработки экспериментальных данных является численное значение

Содержание предварительной обработки в основном состоит в
отсеивании грубых погрешностей измерения
Содержание предварительной обработки в основном состоит в
отсеивании грубых погрешностей измерения

Генеральная совокупность и выборка.
Генеральной называют совокупность всех мыслимых наблюдений,
которые
Генеральная совокупность и выборка.
Генеральной называют совокупность всех мыслимых наблюдений,
которые

Понятие бесконечной генеральной совокупности – математическая абстракция, как и представление о
Понятие бесконечной генеральной совокупности – математическая абстракция, как и представление о

Выборка – любое конечное подмножество генеральной совокупности, предназначенное для непосредственных исследований,
Выборка – любое конечное подмножество генеральной совокупности, предназначенное для непосредственных исследований,

Характеристики теоретических распределений можно рассматривать как характеристики, существующие в генеральной совокупности,
Характеристики теоретических распределений можно рассматривать как характеристики, существующие в генеральной совокупности,

Исходными данными при оценивании, как и при проверке любых предположений (статистических
Исходными данными при оценивании, как и при проверке любых предположений (статистических

Оценивание – определение приближенного значения неизвестного
параметра генеральной совокупности по результатам
Оценивание – определение приближенного значения неизвестного
параметра генеральной совокупности по результатам

Вычисление характеристик эмпирических распределений (выборочных характеристик).
Здесь и в дальнейшем речь
Вычисление характеристик эмпирических распределений (выборочных характеристик).
Здесь и в дальнейшем речь

Величину
называют дисперсией или вторым центральным моментом эмпирического распределения S2 = m2.
Величину
называют дисперсией или вторым центральным моментом эмпирического распределения S2 = m2.

_
Несмещенную оценку для S 2 (или σ2 - дисперсия теоретического
_
Несмещенную оценку для S 2 (или σ2 - дисперсия теоретического

Из других моментов чаще всего используют моменты третьего и
четвертого порядка:
Из других моментов чаще всего используют моменты третьего и
четвертого порядка:

Выборочные значения характеристик распределения имеет
смысл вычислять только в случае, если
Выборочные значения характеристик распределения имеет
смысл вычислять только в случае, если

Отсев грубых погрешностей.
Можно встретить большое количество различных рекомендаций для проведения
Отсев грубых погрешностей.
Можно встретить большое количество различных рекомендаций для проведения

Таким образом, для выделения аномального значения вычисляют
τ, которое затем сравнивают
Таким образом, для выделения аномального значения вычисляют
τ, которое затем сравнивают

Полигон и гистограмма частот распределения.
Если полученные экспериментальные данные разделить на
Полигон и гистограмма частот распределения.
Если полученные экспериментальные данные разделить на

Затем устанавливают границы интервалов и подсчитывают число
попаданий случайной величины в
Затем устанавливают границы интервалов и подсчитывают число
попаданий случайной величины в

Гистограмма и полигон распределений являются графическим
отображением частот, которые, в свою
Гистограмма и полигон распределений являются графическим
отображением частот, которые, в свою

Нормальное распределение обладает и другими важными свойствами, которые позволяют считать это
Нормальное распределение обладает и другими важными свойствами, которые позволяют считать это

Из формулы (16) следует, что нормальное распределение полностью определяется величинами μ
Из формулы (16) следует, что нормальное распределение полностью определяется величинами μ

Примерно 2/3 всех наблюдений лежит в площади, отсекаемой перпендикулярами к оси
Примерно 2/3 всех наблюдений лежит в площади, отсекаемой перпендикулярами к оси

Медианой выборки является среднее значение из всего упорядоченного набора значений.
Модой
Медианой выборки является среднее значение из всего упорядоченного набора значений.
Модой

Проверка гипотезы нормальности распределения.
Среднее абсолютное отклонение.
Для небольших выборок (n
Проверка гипотезы нормальности распределения.
Среднее абсолютное отклонение.
Для небольших выборок (n

Пользуясь САО, можно также с 95%-й доверительной вероятностью оценить µ (среднее
Пользуясь САО, можно также с 95%-й доверительной вероятностью оценить µ (среднее

Размах варьирования R.
Быструю проверку гипотезы нормальности распределения для
сравнительно широкого
Размах варьирования R.
Быструю проверку гипотезы нормальности распределения для
сравнительно широкого

Показатели асимметрии и эксцесса.
Некоторое представление о близости эмпирического распределения к
Показатели асимметрии и эксцесса.
Некоторое представление о близости эмпирического распределения к

Несмещенные оценки для показателей асимметрии G1 и эксцесса G2 определяют соответственно
Несмещенные оценки для показателей асимметрии G1 и эксцесса G2 определяют соответственно

По критерию χ2 (хи-квадрат)
Рассмотрим методику проверки гипотезы нормальности распределения по
По критерию χ2 (хи-квадрат)
Рассмотрим методику проверки гипотезы нормальности распределения по

где f(zj) – уравнение кривой стандартного нормального распределения:
zj – степень
где f(zj) – уравнение кривой стандартного нормального распределения:
zj – степень
ожидаемая дисперсия:
nкл - число классов (интервалов).
ожидаемая дисперсия:
nкл - число классов (интервалов).

Полученное значение χ2 сравнивают с табличным или критическим значением χ2 nкα,.
Полученное значение χ2 сравнивают с табличным или критическим значением χ2 nкα,.

Методика проверки нормальности распределения по показателям
асимметрии и эксцесса очень хорошо
Методика проверки нормальности распределения по показателям
асимметрии и эксцесса очень хорошо

Особенности использования средств инструмента
«Описательная статистика» в надстройке
«Пакет анализа» MS
Особенности использования средств инструмента
«Описательная статистика» в надстройке
«Пакет анализа» MS

В состав MS Excel входит надстройка «Пакет анализа», которая
содержит 19
В состав MS Excel входит надстройка «Пакет анализа», которая
содержит 19
Инструмент «Описательная статистика» (вместе с инструментом «Гистограмма», алгоритм использования которого будет
Инструмент «Описательная статистика» (вместе с инструментом «Гистограмма», алгоритм использования которого будет
После выбора инструмента «Описательная статистика» в по-
явившемся диалоговом окне инструмента (рис.
После выбора инструмента «Описательная статистика» в по-
явившемся диалоговом окне инструмента (рис.

Флажок Метки в первой строке – устанавливается в активное состояние, если
Флажок Метки в первой строке – устанавливается в активное состояние, если

Флажок Уровень надежности – устанавливается в активное состояние, если в результативную
Флажок Уровень надежности – устанавливается в активное состояние, если в результативную

Между терминологией инструмента «Описательная статистика»
и терминами, принятыми в отечественной статистике,
Между терминологией инструмента «Описательная статистика»
и терминами, принятыми в отечественной статистике,
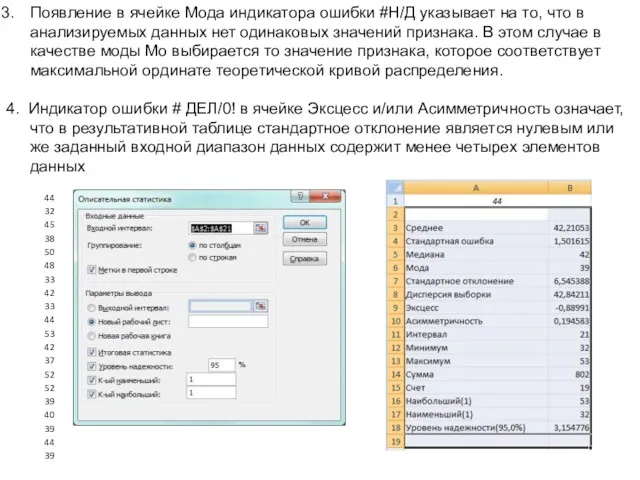
Появление в ячейке Мода индикатора ошибки #Н/Д указывает на то, что
Появление в ячейке Мода индикатора ошибки #Н/Д указывает на то, что

Особенности использования средств инструмента
«Гистограмма» в надстройке «Пакет анализа» MS Excel
Особенности использования средств инструмента
«Гистограмма» в надстройке «Пакет анализа» MS Excel
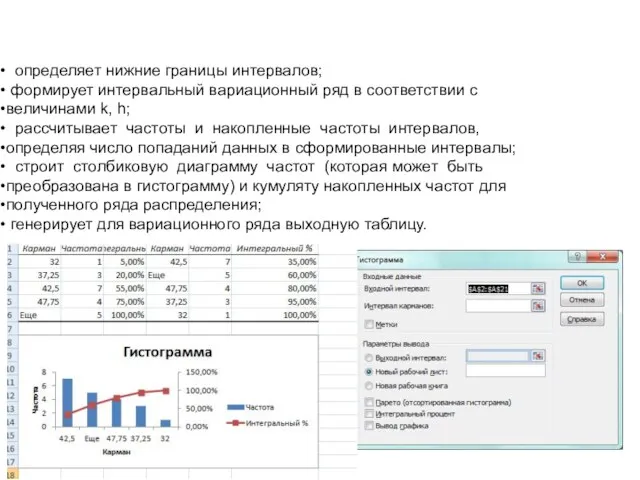
определяет нижние границы интервалов;
формирует интервальный вариационный ряд в соответствии
формирует интервальный вариационный ряд в соответствии

статистическая интерпретация терминологии инструмента «Гистограмма»
Термин инструмента «Гистограмма» Термин, принятый в статистике
Карманы Интервалы вариационного
статистическая интерпретация терминологии инструмента «Гистограмма»
Термин инструмента «Гистограмма» Термин, принятый в статистике
Карманы Интервалы вариационного

Инструмент «Гистограмма» имеет два режима работы:
режим автоматического формирования
Инструмент «Гистограмма» имеет два режима работы:
режим автоматического формирования
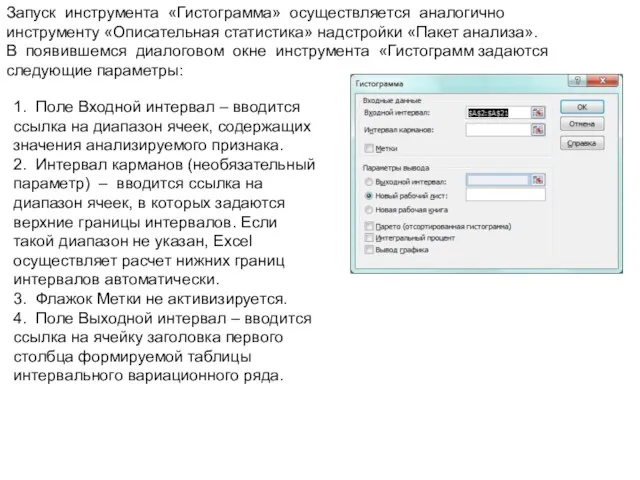
Запуск инструмента «Гистограмма» осуществляется аналогично
инструменту «Описательная статистика» надстройки «Пакет анализа».
Запуск инструмента «Гистограмма» осуществляется аналогично
инструменту «Описательная статистика» надстройки «Пакет анализа».
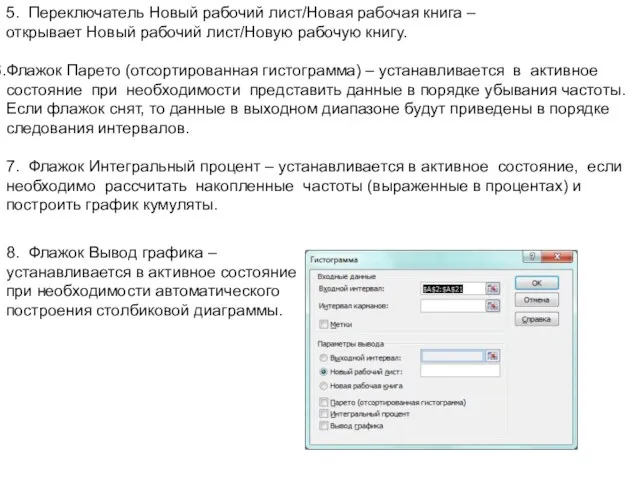
5. Переключатель Новый рабочий лист/Новая рабочая книга –
открывает Новый рабочий
5. Переключатель Новый рабочий лист/Новая рабочая книга –
открывает Новый рабочий

Необходимо отметить, что инструменты «Пакет анализа» имеют
определенные ограничения и иногда
Необходимо отметить, что инструменты «Пакет анализа» имеют
определенные ограничения и иногда
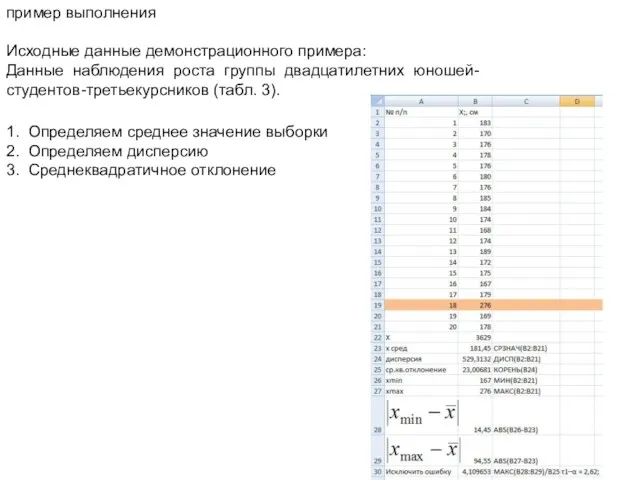
пример выполнения
Исходные данные демонстрационного примера:
Данные наблюдения роста группы двадцатилетних
пример выполнения
Исходные данные демонстрационного примера:
Данные наблюдения роста группы двадцатилетних
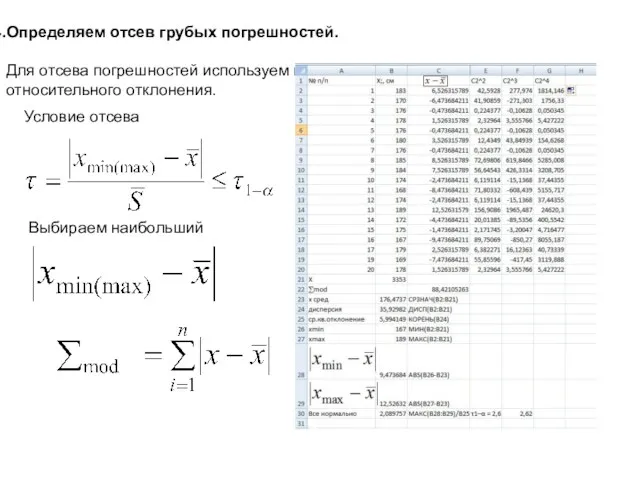
Определяем отсев грубых погрешностей.
Для отсева погрешностей используем метод максимального относительного
Для отсева погрешностей используем метод максимального относительного

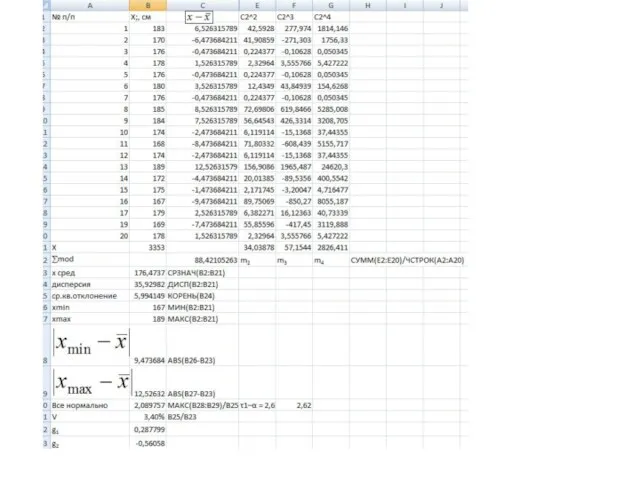
Определяем другие статистические характеристики:
коэффициент вариации по формуле
коэффициент асимметрии по
Определяем другие статистические характеристики:
коэффициент вариации по формуле
коэффициент асимметрии по

Полигон и гистограмма частот распределения
Число классов k приблизительно можно вычислить по
Полигон и гистограмма частот распределения
Число классов k приблизительно можно вычислить по
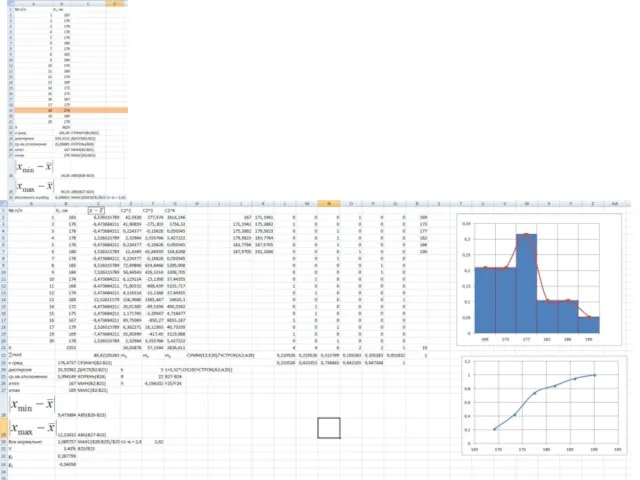

Выполняем проверку выборки на нормальность распределения по следующим критериям:
– по
Выполняем проверку выборки на нормальность распределения по следующим критериям:
– по

Коэффициент (0,71 ч 0,6) зависит от величины выборки n (в данном
Коэффициент (0,71 ч 0,6) зависит от величины выборки n (в данном

по коэффициентам асимметрии и эксцесса.
Условия:
где G1 - несмещенная
по коэффициентам асимметрии и эксцесса.
Условия:
где G1 - несмещенная

по критерию χ2 (свойства кривой нормального распределения) должно выполняться условие
где Bj
по критерию χ2 (свойства кривой нормального распределения) должно выполняться условие
где Bj
 Кусочно-заданные функции. 9 класс
Кусочно-заданные функции. 9 класс Виды углов. Измерение углов
Виды углов. Измерение углов Подобные треугольники
Подобные треугольники Решение задач на проценты
Решение задач на проценты Принцип Дирихле
Принцип Дирихле Площадь прямоугольника. 5 класс
Площадь прямоугольника. 5 класс Сложение и вычитание векторов
Сложение и вычитание векторов Радианная мера угла. Угол поворота
Радианная мера угла. Угол поворота Третий признак равенства треугольников
Третий признак равенства треугольников Прямоугольный параллелепипед
Прямоугольный параллелепипед Округление десятичных дробей. Урок математики в 5 классе
Округление десятичных дробей. Урок математики в 5 классе Описательная статистика
Описательная статистика Презентация к уроку математики:Экскурсия по Воронежу
Презентация к уроку математики:Экскурсия по Воронежу Квадрат. Свойства квадрата. Периметр квадрата
Квадрат. Свойства квадрата. Периметр квадрата Сбор и группировка статистических данных
Сбор и группировка статистических данных Проценты. 5 класс
Проценты. 5 класс Окружность. Центр окружности
Окружность. Центр окружности Золотое сечение в произведениях Леонардо Да Винчи
Золотое сечение в произведениях Леонардо Да Винчи Переместительный способ.
Переместительный способ. Организационная cтруктура метрологической службы. (Лекция 5)
Организационная cтруктура метрологической службы. (Лекция 5) Додавання і множення числових нерівностей. 9 клас
Додавання і множення числових нерівностей. 9 клас Логарифм и ОДЗ. Решения
Логарифм и ОДЗ. Решения Тест по математике
Тест по математике Технология развития чувства времени у детей старшего дошкольного возраста в игровой деятельности (презентация)
Технология развития чувства времени у детей старшего дошкольного возраста в игровой деятельности (презентация) Урок математики(1класс)
Урок математики(1класс) Деление многозначного на трёхзначное
Деление многозначного на трёхзначное Теория вероятностей
Теория вероятностей Вписанная окружность. 8 класс
Вписанная окружность. 8 класс