- Регрессионный анализ. МНК. Мультиколлинеарность

Содержание
- 2. Регрессионный анализ 2 Построение функциональной зависимости результирующей переменной y от объясняющих переменных x(1),…,x(n). Этимология (Фрэнсис Гальтон):
- 3. Линейная регрессия: матричная форма 3 – ковариационная матрица остатков. Если в дополнение к перечисленным 3 свойствам
- 4. Оценивание параметров. Метод наименьших квадратов 4 Принцип: Прогнозные значения должны мини-мально отличаться от наблюдаемых. Минимальность понимается
- 5. Метод наименьших квадратов. Случай парной регрессии 5 Формулы МНК для парной регрессии y = θ0 +
- 6. Численный пример 6 = ЛИНЕЙН (у1,…,yn; ; 1; 1). 3 × (p+1) ⇒ формула ⇒ Ctrl-Shift-Enter
- 7. Свойства оценок 7 На разных выборках за счет случайного характера остатков будут получены различные оценки! 1.
- 8. Свойства оценок 8 2. Несмещенность: при любом объеме выборки. Усреднение полученных оценок по всем выборкам данного
- 9. Свойства оценок КЛММР 9 Несмещенная оценка ошибки прогноза: Ковариационная матрица оценок параметров: Наиболее важными являются диагональные
- 10. Значимость регрессоров 10 – распределена по закону Стьюдента. Проверка гипотезы о значимости регрессоров: Н0: θj =
- 11. Построение доверительного интервала 11 При уровне значимости 1% (tкрит = 2,80) незначимой становится цена, при 0,1%
- 12. Проверка гипотезы о значимости модели 12 Проверка гипотезы о значимости модели: Н0: R2 = 0 1.
- 13. Ошибки спецификации модели: исключение значащих переменных 13 Неправомерное исключение значащих объясняющих переменных Смещены оценки коэффициентов регрессии;
- 14. Сопоставление моделей 14 Старая модель: Новая модель: Можно учесть влияние предпраздничного месяца: Есть риск введения в
- 15. Мультиколлинеарность 15 Полная мультиколлинеарность – линейная функциональная связь меж-ду объясняющими переменными, одна из них линейно выражается
- 16. Эвристические рекомендации для выявления частичной мультиколлинеарности 16 5. Анализ экономической сущности модели. ## Некоторые оценки коэффициентов
- 17. Переход к смещенным методам оценивания 17 значения оценок на разных выборках Смещенная оценка может быть более
- 18. Отбор наиболее существенных объясняющих переменных 18 1. Версия всех возможных регрессий. Для заданного k = 1,…,p
- 19. Метод главных компонент 19 3. Переход к новым переменным Z = XL – новые переменные, «главные
- 20. Геометрическая интерпретация метода главных компонент 20 Рис.1. Умеренный разброс точек вдоль z(2) Рис.2. Вырожденный случай: отсутствие
- 21. Проблема интерпретации метода главных компонент 21 Матрица нагрузок главных компонент на исходные переменные: ## Наблюдения –
- 23. Скачать презентацию

Регрессионный анализ
2
Построение функциональной зависимости результирующей переменной y от объясняющих переменных x(1),…,x(n).
Этимология
Регрессионный анализ
2
Построение функциональной зависимости результирующей переменной y от объясняющих переменных x(1),…,x(n).
Этимология

Линейная регрессия:
матричная форма
3
– ковариационная
матрица остатков.
Если в дополнение к перечисленным 3
Линейная регрессия:
матричная форма
3
– ковариационная
матрица остатков.
Если в дополнение к перечисленным 3
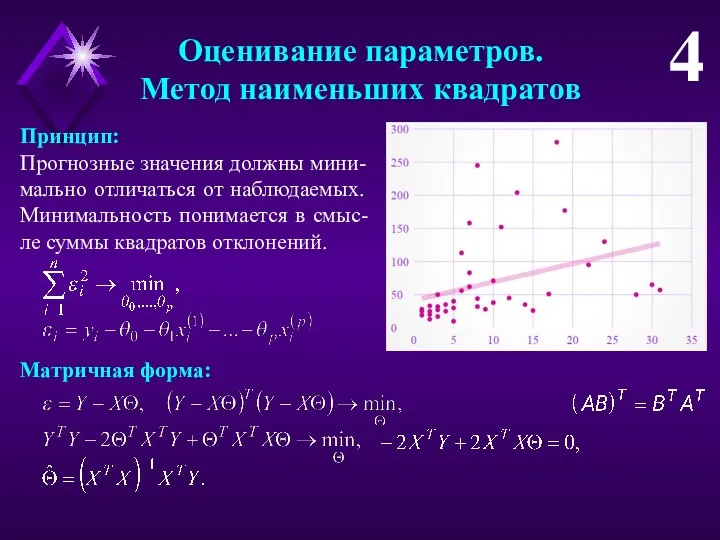
Оценивание параметров.
Метод наименьших квадратов
4
Принцип:
Прогнозные значения должны мини-мально отличаться от наблюдаемых.
Оценивание параметров.
Метод наименьших квадратов
4
Принцип:
Прогнозные значения должны мини-мально отличаться от наблюдаемых.

Метод наименьших квадратов.
Случай парной регрессии
5
Формулы МНК для парной регрессии y
Метод наименьших квадратов.
Случай парной регрессии
5
Формулы МНК для парной регрессии y
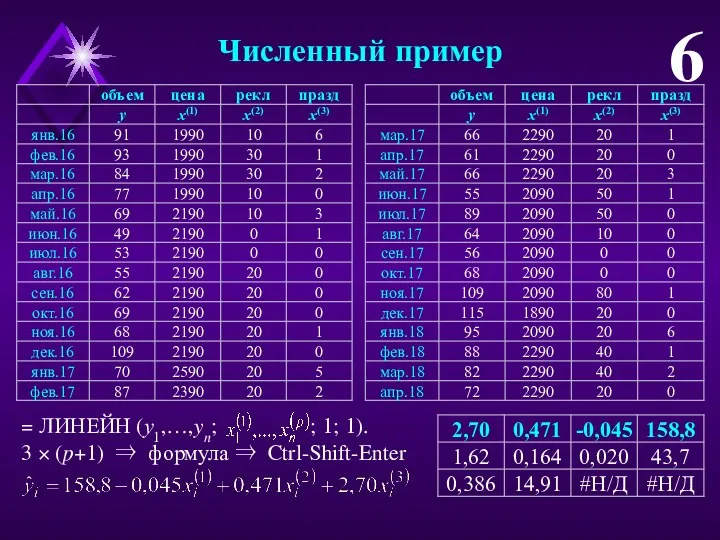
Численный пример
6
= ЛИНЕЙН (у1,…,yn; ; 1; 1).
3 × (p+1) ⇒ формула
Численный пример
6
= ЛИНЕЙН (у1,…,yn; ; 1; 1).
3 × (p+1) ⇒ формула

Свойства оценок
7
На разных выборках за счет случайного характера остатков будут получены
Свойства оценок
7
На разных выборках за счет случайного характера остатков будут получены

Свойства оценок
8
2. Несмещенность: при любом объеме выборки.
Усреднение полученных оценок по всем
Свойства оценок
8
2. Несмещенность: при любом объеме выборки.
Усреднение полученных оценок по всем

Свойства оценок КЛММР
9
Несмещенная оценка ошибки прогноза:
Ковариационная матрица оценок параметров:
Наиболее важными являются
Свойства оценок КЛММР
9
Несмещенная оценка ошибки прогноза:
Ковариационная матрица оценок параметров:
Наиболее важными являются

Значимость регрессоров
10
– распределена по закону Стьюдента.
Проверка гипотезы о значимости регрессоров: Н0:
Значимость регрессоров
10
– распределена по закону Стьюдента.
Проверка гипотезы о значимости регрессоров: Н0:

Построение
доверительного интервала
11
При уровне значимости 1% (tкрит = 2,80) незначимой становится цена,
Построение
доверительного интервала
11
При уровне значимости 1% (tкрит = 2,80) незначимой становится цена,

Проверка гипотезы
о значимости модели
12
Проверка гипотезы о значимости модели: Н0: R2 =
Проверка гипотезы
о значимости модели
12
Проверка гипотезы о значимости модели: Н0: R2 =

Ошибки спецификации модели:
исключение значащих переменных
13
Неправомерное исключение значащих объясняющих переменных
Смещены оценки коэффициентов
Ошибки спецификации модели:
исключение значащих переменных
13
Неправомерное исключение значащих объясняющих переменных
Смещены оценки коэффициентов

Сопоставление моделей
14
Старая модель:
Новая модель:
Можно учесть влияние предпраздничного месяца:
Есть риск введения в
Сопоставление моделей
14
Старая модель:
Новая модель:
Можно учесть влияние предпраздничного месяца:
Есть риск введения в

Мультиколлинеарность
15
Полная мультиколлинеарность – линейная функциональная связь меж-ду объясняющими переменными, одна из
Мультиколлинеарность
15
Полная мультиколлинеарность – линейная функциональная связь меж-ду объясняющими переменными, одна из

Эвристические рекомендации
для выявления частичной мультиколлинеарности
16
5. Анализ экономической сущности модели.
## Некоторые оценки
Эвристические рекомендации
для выявления частичной мультиколлинеарности
16
5. Анализ экономической сущности модели.
## Некоторые оценки

Переход к смещенным
методам оценивания
17
значения оценок
на разных выборках
Смещенная оценка может быть более
Переход к смещенным
методам оценивания
17
значения оценок
на разных выборках
Смещенная оценка может быть более

Отбор наиболее существенных
объясняющих переменных
18
1. Версия всех возможных регрессий.
Для заданного k =
Отбор наиболее существенных
объясняющих переменных
18
1. Версия всех возможных регрессий.
Для заданного k =

Метод главных компонент
19
3. Переход к новым переменным Z = XL
–
Метод главных компонент
19
3. Переход к новым переменным Z = XL
–
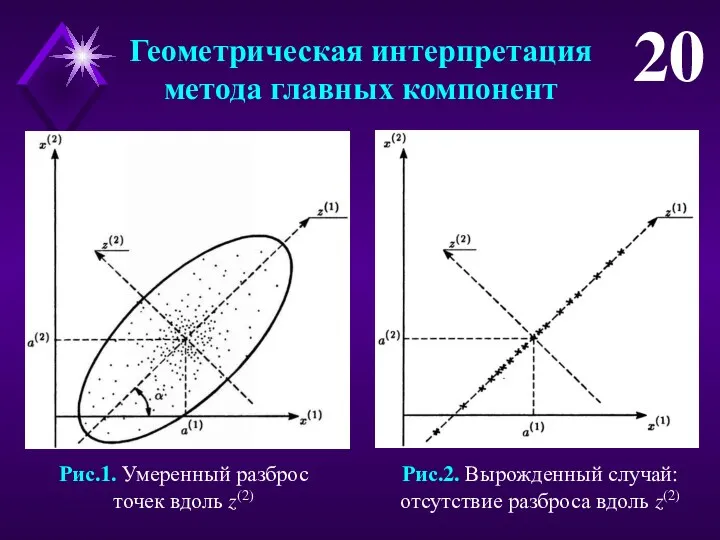
Геометрическая интерпретация
метода главных компонент
20
Рис.1. Умеренный разброс
точек вдоль z(2)
Рис.2. Вырожденный случай:
отсутствие разброса
Геометрическая интерпретация
метода главных компонент
20
Рис.1. Умеренный разброс
точек вдоль z(2)
Рис.2. Вырожденный случай:
отсутствие разброса

Проблема интерпретации
метода главных компонент
21
Матрица нагрузок главных компонент на исходные переменные:
## Наблюдения
Проблема интерпретации
метода главных компонент
21
Матрица нагрузок главных компонент на исходные переменные:
## Наблюдения
 Площадь. Формула площади прямоугольника
Площадь. Формула площади прямоугольника Графы. История возникновения графов
Графы. История возникновения графов Презентация по теме Сложение и вычитание числа 1
Презентация по теме Сложение и вычитание числа 1 Кому нужна математика
Кому нужна математика Статистические методы анализа данных параметров транспортного процесса
Статистические методы анализа данных параметров транспортного процесса Применение формулы Пика
Применение формулы Пика Правильные многогранники
Правильные многогранники Презентация Система заданий по формированию регулятивных УУД на уроках математики в 1 классе, комментарий к слайдам
Презентация Система заданий по формированию регулятивных УУД на уроках математики в 1 классе, комментарий к слайдам По тропинкам математики. Игра
По тропинкам математики. Игра Прямоугольные треугольники и их свойства. Решение задач по готовым чертежам
Прямоугольные треугольники и их свойства. Решение задач по готовым чертежам Замечательные кривые
Замечательные кривые Делители и кратные
Делители и кратные Третий признак равенства треугольников
Третий признак равенства треугольников Решение неравенств второй степени с одной переменной. 9 класс
Решение неравенств второй степени с одной переменной. 9 класс Решение задач по теме Признаки параллельности прямых
Решение задач по теме Признаки параллельности прямых Презентации к урокам математики
Презентации к урокам математики Решение квадратных уравнений
Решение квадратных уравнений Неполные квадратные уравнения
Неполные квадратные уравнения Таблица сложения с переходом через десяток
Таблица сложения с переходом через десяток Случаи сложения вида +8, +9
Случаи сложения вида +8, +9 Игровой тренажер Страна смешариков
Игровой тренажер Страна смешариков ДЕМО вариант 2016
ДЕМО вариант 2016 Классификация погрешностей
Классификация погрешностей Системная подготовка к ЕГЭ на уроках математики
Системная подготовка к ЕГЭ на уроках математики КВН по математике 4 класс
КВН по математике 4 класс Устные и письменные приемы вычисления вида 32-5, 51-27
Устные и письменные приемы вычисления вида 32-5, 51-27 Симметрия в природе
Симметрия в природе Научиться решать задачи второй части ОГЭ под номером 22.
Научиться решать задачи второй части ОГЭ под номером 22.