- Grid Resource Management and Scheduling

Содержание
- 2. Security: Grid Security Infrastructure Resource Management: Grid Resource Allocation Management Information Services: Grid Resource Information Data
- 3. Grid systems Classification: (depends on the author) Computational grid: distributed supercomputing (parallel application execution on multiple
- 4. Taxonomy of Applications High-Performance Computing (HPC): large amounts of computing power for short periods of time;
- 5. Alternative classification independent tasks loosely-coupled tasks loosely coupled system is one in which each of its
- 6. Application Management Description Partitioning Mapping Allocation
- 7. Grid and HPC We all know what “the Grid” is… one of the many definitions: “Resource
- 8. Resource Management on HPC Resources HPC resources are usually parallel computers or large scale clusters The
- 9. HPC Management Architecture in General Compute Resources/ Processing Nodes Master Server Control Service Job Master Resource
- 10. Typical cluster resource management
- 11. Computational Job A job is a computational task that requires processing capabilities (e.g. 64 nodes) and
- 12. Example: PBS Job Description Simple job script: #!/bin/csh # resource limits: allocate needed nodes #PBS -l
- 13. Job Submission The user “submits” the job to the RMS e.g. issuing “qsub jobscript.pbs” The user
- 14. PBS Structure Job Submission Management Server Scheduler qsub jobscript
- 15. Execution Alternatives Time sharing: The local scheduler starts multiple processes per physical CPU with the goal
- 16. Job Classifications Batch Jobs vs interactive jobs batch jobs are queued until execution interactive jobs need
- 17. Preemption A job is preempted by interrupting its current execution the job might be on hold
- 18. Job Scheduling A job is assigned to resources through a scheduling process responsible for identifying available
- 19. Typical Scheduling Objectives Minimizing the Average Weighted Response Time Maximize machine utilization/minimize idle time conflicting objective
- 20. Job Steps Scheduler Schedule time local Job-Queue HPC Machine Grid- User Job Execution Management Node Job
- 21. Scheduling Algorithms: FCFS Well known and very simple: First-Come First-Serve Jobs are started in order of
- 22. FCFS Schedule Scheduler Schedule time Job-Queue Compute Resource Resources Procssing Nodes Time Queue
- 23. Scheduling Algorithms: Backfilling Improvement over FCFS A job can be started before an earlier submitted job
- 24. Backfill Scheduling Scheduler Schedule time Job-Queue Compute Resource Queue 1. 2. 3. 4… Job 3 is
- 25. Backfill Scheduling Scheduler Schedule time Job-Queue Compute Resource Resources Procssing Nodes Time However, if a job
- 26. Job Execution Manager After the scheduling process, the RMS is responsible for the job execution: sets
- 27. Scheduling Options Parallel job scheduling algorithms are well studied; performance is usually acceptable Real implementations may
- 28. Transition to Grid Resource Management and Scheduling Current state of the art
- 29. Transition to the Grid More resource types come into play: Resources are any kind of entity,
- 30. Implications to Grid Resource Management Several security-related issues have to be considered: authentication, authorization,accounting who has
- 31. Scope of Grids Cluster Grid Enterprise Grid Global Grid Source: Ian Foster
- 32. Domain 2 Domain 1 Grid Resource Management: Challenging Issues Ack.: globus.. Authentication (once) Specify simulation (code,
- 33. Resource Brokers Application RSL (RSL Specialization) Resource Management Architecture
- 34. Resource Management Layer Grid Resource Management System consists of : Local resource management system (Resource Layer)
- 35. Remote Execution Steps Choose Resource Transfer Input Files Set Environment Start Process Pass Arguments Monitor Progress
- 36. Grid Middleware Source: Ian Foster
- 37. Grid Middleware (2) Resource Broker Grid Middleware Higher-Level Services User/ Application Gatekeeper
- 38. Globus Grid Middleware Globus Toolkit common source for Grid middleware GT2 GT3 – Web/GridService-based GT4 –
- 39. Globus Job Execution Job is described in the resource specification language Discover a Job Service for
- 40. Globus GT2 Execution User/Application Resource Broker Resource Allocation MDS RSL Specialized RSL RSL
- 41. RSL Grid jobs are described in the resource specification language (RSL) RSL Version 1 is used
- 42. Job Description with RSL2 The version 2 of RSL is XML-based Two namespaces are used: rsl:
- 43. RSL2 Attributes (type = rsl:integerType) Number of processes to run (default is 1) (type = rsl:integerType)
- 44. Job Submission Tools GT 3 provides the Java class GramClient GT 2.x: command line programs for
- 45. Globus 2 Job Client Interface A multirequest specifies multiple resources for a job globus-job-run -dumprsl -:
- 46. Globus 2 Job Client Interface The full flexibility of RSL is available through the command line
- 47. Problem: Job Submission Descriptions differ The deliverables of the GGF Working Group JSDL: A specification for
- 48. JSDL Attribute Categories The job attribute categories will include: Job Identity Attributes ID, owner, group, project,
- 49. Grid Scheduling How to select resources in the Grid?
- 50. Different Level of Scheduling Resource-level scheduler low-level scheduler, local scheduler, local resource manager scheduler close to
- 51. Grid-Level Scheduler Discovers & selects the appropriate resource(s) for a job If selected resources are under
- 52. Grid Scheduling Scheduler Schedule time Job-Queue Machine 1 Scheduler Schedule time Job-Queue Machine 2 Scheduler Schedule
- 53. Activities of a Grid Scheduler GGF Document: “10 Actions of Super Scheduling (GFD-I.4)” Source: Jennifer Schopf
- 54. Grid Scheduling A Grid scheduler allows the user to specify the required resources and environment of
- 55. Select a Resource for Execution Most systems do not provide advance information about future job execution
- 56. Selection Criteria Distribute jobs in order to balance load across resources not suitable for large scale
- 57. Co-allocation It is often requested that several resources are used for a single job. that is,
- 58. Example Multi-Site Job Execution A job uses several resources at different sites in parallel. Network communication
- 59. Advanced Reservation Co-allocation and other applications require a priori information about the precise resource availability With
- 60. Example of Grid Scheduling Decision Making Scheduler Schedule time Job-Queue Machine 1 Scheduler Schedule time Job-Queue
- 61. Available Information from the Local Schedulers Decision making is difficult for the Grid scheduler limited information
- 62. Consequence Consider a workflow with 3 short steps (e.g. 1 minute each) that depend on each
- 63. Job A (4) Job A (3) Job A (2) Job A (1) resource pool for User-Level
- 64. Data and Network Scheduling Most new resource types can be included via individual lower-level resource management
- 65. Data Management Access to information about the location of data sets Information about transfer costs Scheduling
- 66. Example of a Scheduling Process Scheduling Service: receives job description queries Information Service for static resource
- 67. Re-Scheduling Reconsidering a schedule with already made agreements may be a good idea from time to
- 68. Computational Economy in Resource Management “Observe Grid characteristics and current resource management policies” Grid resources are
- 69. Computational Market Model for Grid Resource Management Grid User Application Grid Resource Broker Grid Resource/Control Domains
- 71. Conclusion Resource management and scheduling is a key service in an Next Generation Grid. In a
- 73. Скачать презентацию

Security: Grid Security Infrastructure
Resource Management: Grid Resource Allocation Management
Information Services: Grid
Security: Grid Security Infrastructure
Resource Management: Grid Resource Allocation Management
Information Services: Grid

Grid systems
Classification: (depends on the author)
Computational grid:
distributed supercomputing (parallel application
Grid systems
Classification: (depends on the author)
Computational grid:
distributed supercomputing (parallel application

Taxonomy of Applications
High-Performance Computing (HPC): large amounts of computing power for
Taxonomy of Applications
High-Performance Computing (HPC): large amounts of computing power for

Alternative classification
independent tasks
loosely-coupled tasks
loosely coupled system is one in which each
Alternative classification
independent tasks
loosely-coupled tasks
loosely coupled system is one in which each
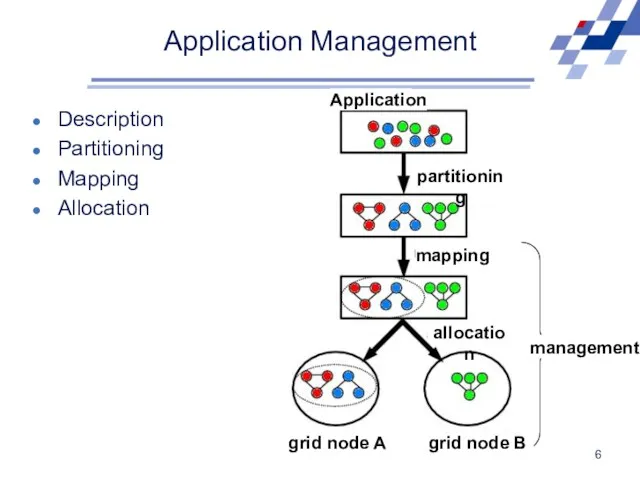
Application Management
Description
Partitioning
Mapping
Allocation
Application Management
Description
Partitioning
Mapping
Allocation

Grid and HPC
We all know what “the Grid” is…
one of the
Grid and HPC
We all know what “the Grid” is…
one of the

Resource Management
on HPC Resources
HPC resources are usually parallel computers or
Resource Management
on HPC Resources
HPC resources are usually parallel computers or
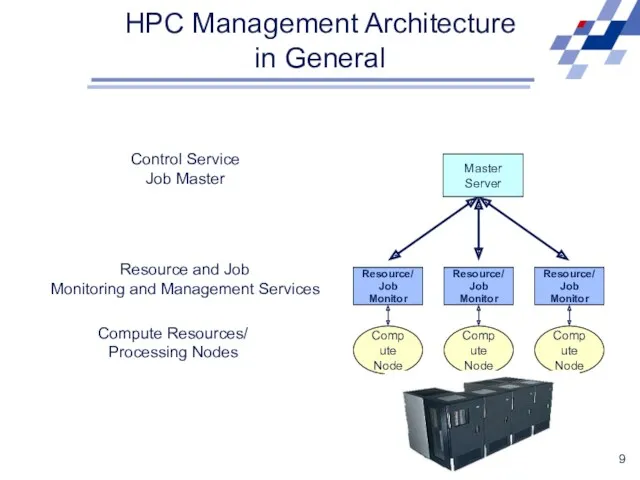
HPC Management Architecture
in General
Compute Resources/
Processing Nodes
Master
Server
Control Service
Job Master
Resource and Job
Monitoring
HPC Management Architecture
in General
Compute Resources/
Processing Nodes
Master
Server
Control Service
Job Master
Resource and Job Monitoring
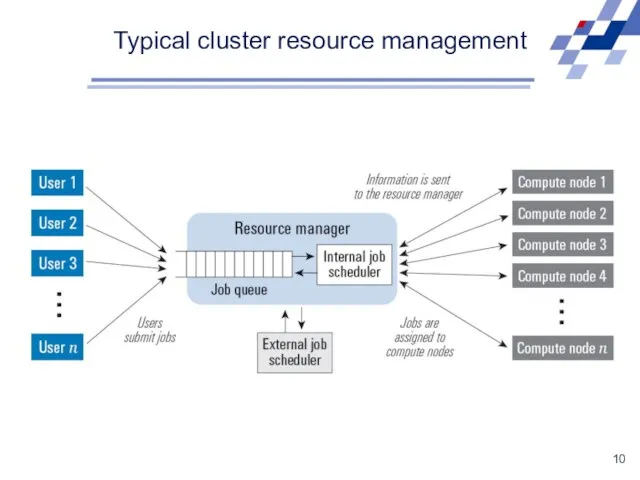
Typical cluster resource management
Typical cluster resource management

Computational Job
A job is a computational task
that requires processing capabilities
Computational Job
A job is a computational task
that requires processing capabilities
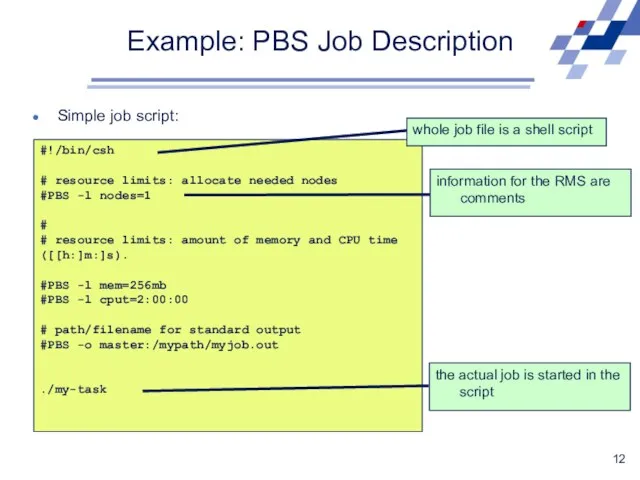
Example: PBS Job Description
Simple job script:
#!/bin/csh
# resource limits: allocate needed nodes
#PBS
Example: PBS Job Description
Simple job script:
#!/bin/csh
# resource limits: allocate needed nodes
#PBS

Job Submission
The user “submits” the job to the RMS
e.g. issuing “qsub
Job Submission
The user “submits” the job to the RMS e.g. issuing “qsub
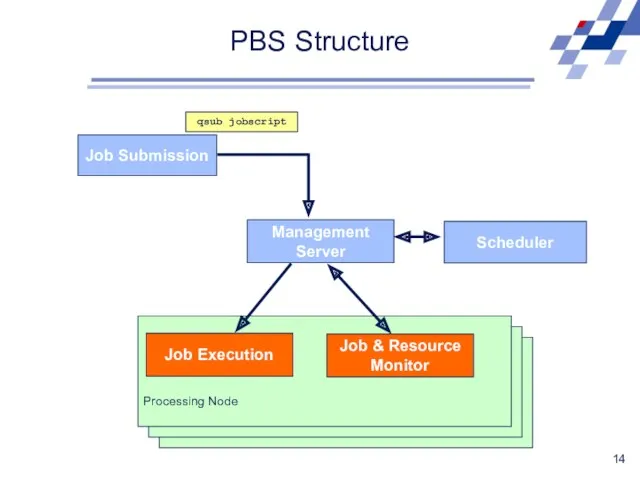
PBS Structure
Job Submission
Management
Server
Scheduler
qsub jobscript
PBS Structure
Job Submission
Management
Server
Scheduler
qsub jobscript

Execution Alternatives
Time sharing:
The local scheduler starts multiple processes per physical CPU
Execution Alternatives
Time sharing:
The local scheduler starts multiple processes per physical CPU

Job Classifications
Batch Jobs vs interactive jobs
batch jobs are queued until execution
interactive
Job Classifications
Batch Jobs vs interactive jobs
batch jobs are queued until execution
interactive

Preemption
A job is preempted by interrupting its current execution
the job might
Preemption
A job is preempted by interrupting its current execution
the job might

Job Scheduling
A job is assigned to resources through a scheduling process
responsible
Job Scheduling
A job is assigned to resources through a scheduling process
responsible

Typical Scheduling Objectives
Minimizing the Average Weighted Response Time
Maximize machine utilization/minimize idle
Typical Scheduling Objectives
Minimizing the Average Weighted Response Time
Maximize machine utilization/minimize idle
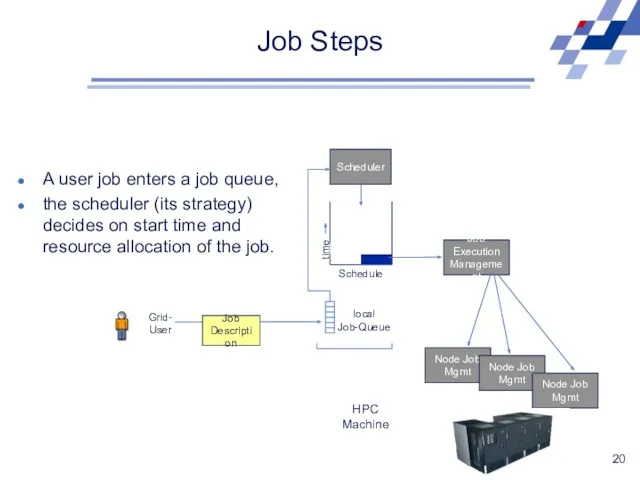
Job Steps
Scheduler
Schedule
time
local
Job-Queue
HPC Machine
Grid-
User
Job Execution
Management
Node Job
Mgmt
Node Job
Mgmt
Node Job
Mgmt
Job
Description
A
Job Steps
Scheduler
Schedule
time
local
Job-Queue
HPC Machine
Grid-
User
Job Execution
Management
Node Job
Mgmt
Node Job
Mgmt
Node Job
Mgmt
Job
Description
A

Scheduling Algorithms:
FCFS
Well known and very simple: First-Come First-Serve
Jobs are started in
Scheduling Algorithms:
FCFS
Well known and very simple: First-Come First-Serve
Jobs are started in
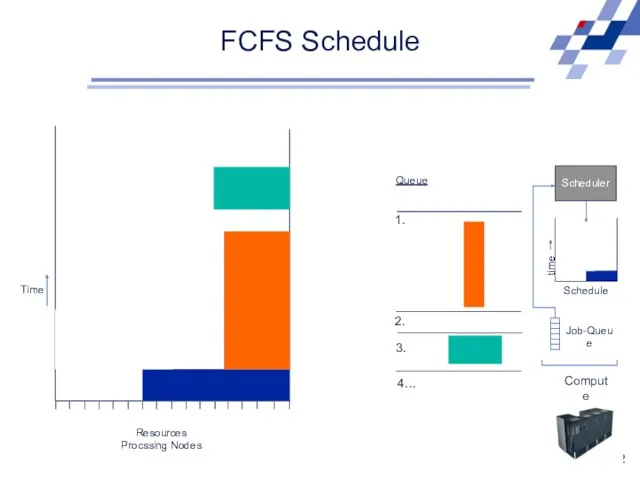
FCFS Schedule
Scheduler
Schedule
time
Job-Queue
Compute Resource
Resources
Procssing Nodes
Time
Queue
FCFS Schedule
Scheduler
Schedule
time
Job-Queue
Compute Resource
Resources
Procssing Nodes
Time
Queue

Scheduling Algorithms:
Backfilling
Improvement over FCFS
A job can be started before an earlier
Scheduling Algorithms:
Backfilling
Improvement over FCFS
A job can be started before an earlier
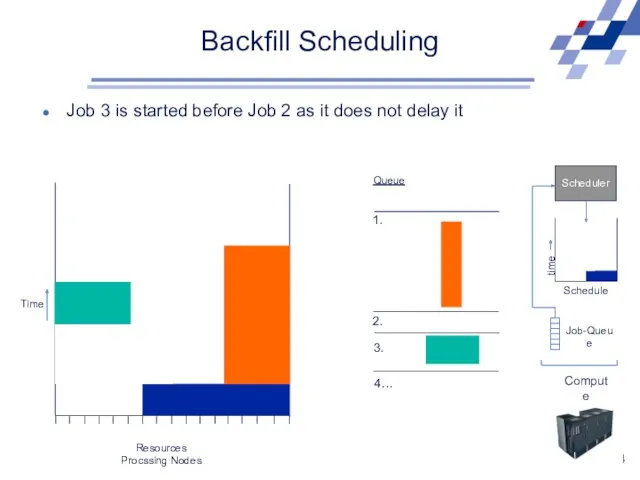
Backfill Scheduling
Scheduler
Schedule
time
Job-Queue
Compute Resource
Queue
1.
2.
3.
4…
Job 3 is started before Job 2 as it
Backfill Scheduling
Scheduler
Schedule
time
Job-Queue
Compute Resource
Queue
1.
2.
3.
4…
Job 3 is started before Job 2 as it
Backfill Scheduling
Scheduler
Schedule
time
Job-Queue
Compute Resource
Resources
Procssing Nodes
Time
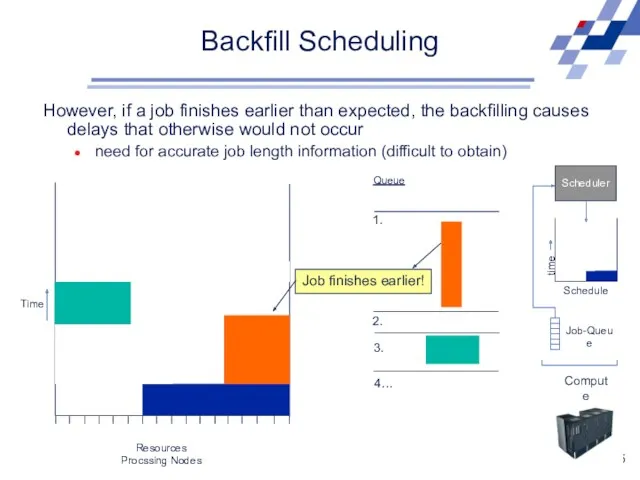
However, if a job finishes earlier than expected,
Backfill Scheduling
Scheduler
Schedule
time
Job-Queue
Compute Resource
Resources
Procssing Nodes
Time
However, if a job finishes earlier than expected,

Job Execution Manager
After the scheduling process,
the RMS is responsible for the
Job Execution Manager
After the scheduling process, the RMS is responsible for the

Scheduling Options
Parallel job scheduling algorithms are well studied; performance is usually
Scheduling Options
Parallel job scheduling algorithms are well studied; performance is usually

Transition to Grid Resource Management and Scheduling
Current state of the art
Transition to Grid Resource Management and Scheduling
Current state of the art

Transition to the Grid
More resource types come into play:
Resources are any
Transition to the Grid
More resource types come into play:
Resources are any

Implications to Grid Resource Management
Several security-related issues have to be considered:
Implications to Grid Resource Management
Several security-related issues have to be considered:
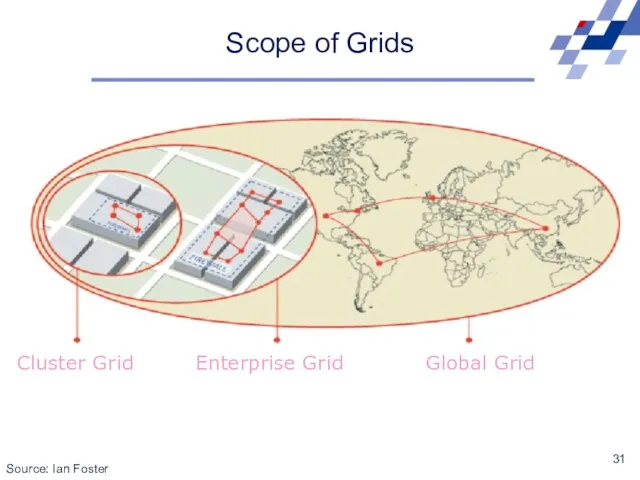
Scope of Grids
Cluster Grid Enterprise Grid Global Grid
Source: Ian Foster
Scope of Grids
Cluster Grid Enterprise Grid Global Grid
Source: Ian Foster
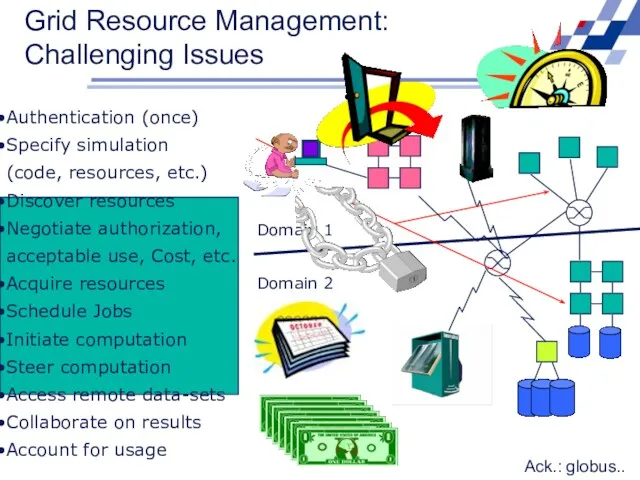
Domain 2
Domain 1
Grid Resource Management: Challenging Issues
Ack.: globus..
Authentication (once)
Specify simulation (code,
Domain 2
Domain 1
Grid Resource Management: Challenging Issues
Ack.: globus..
Authentication (once)
Specify simulation (code,
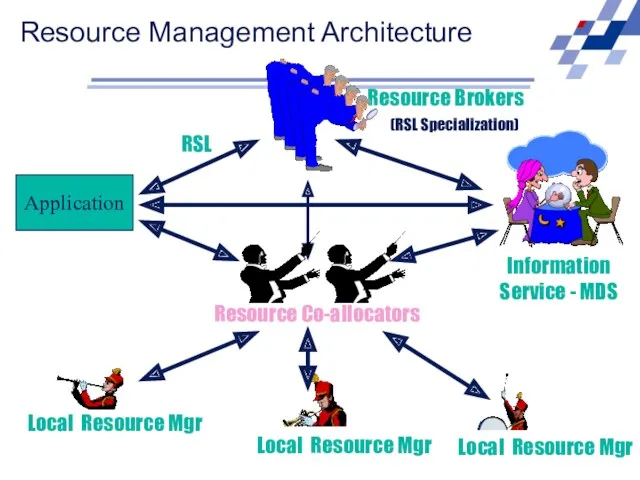
Resource Brokers
Application
RSL
(RSL Specialization)
Resource Management Architecture
Resource Brokers
Application
RSL
(RSL Specialization)
Resource Management Architecture

Resource Management Layer
Grid Resource Management System consists of :
Local resource management
Resource Management Layer
Grid Resource Management System consists of :
Local resource management
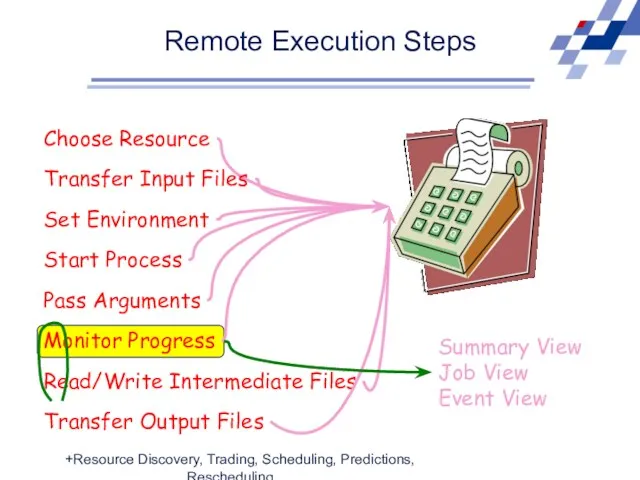
Remote Execution Steps
Choose Resource
Transfer Input Files
Set Environment
Start Process
Pass Arguments
Monitor Progress
Read/Write Intermediate
Remote Execution Steps
Choose Resource
Transfer Input Files
Set Environment
Start Process
Pass Arguments
Monitor Progress
Read/Write Intermediate
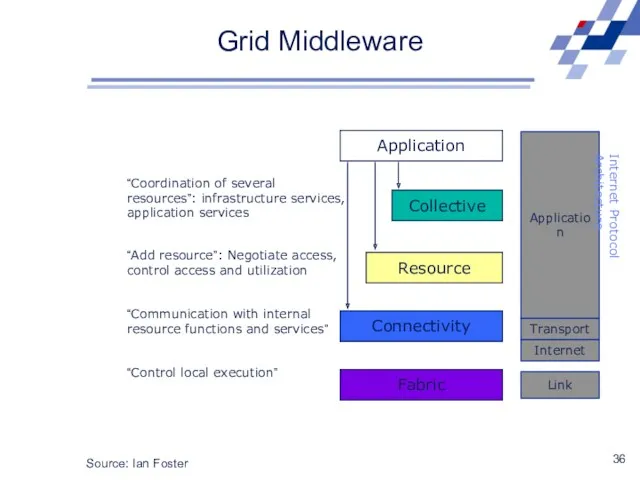
Grid Middleware
Source: Ian Foster
Grid Middleware
Source: Ian Foster
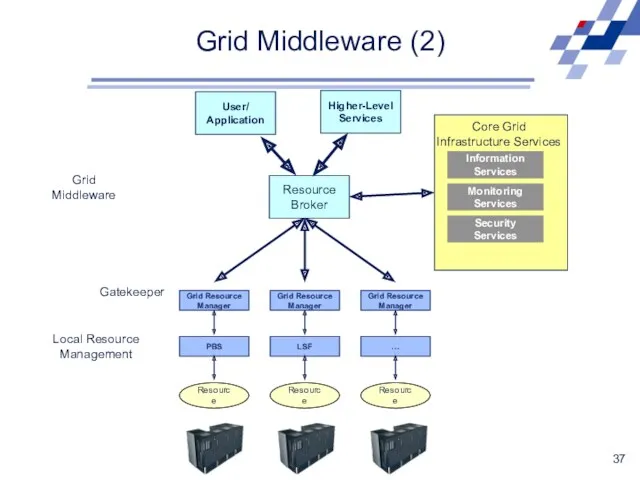
Grid Middleware (2)
Resource
Broker
Grid Middleware
Higher-Level
Services
User/
Application
Gatekeeper
Grid Middleware (2)
Resource
Broker
Grid Middleware
Higher-Level
Services
User/
Application
Gatekeeper

Globus Grid Middleware
Globus Toolkit
common source for Grid middleware
GT2
GT3 –
Globus Grid Middleware
Globus Toolkit
common source for Grid middleware
GT2
GT3 –

Globus Job Execution
Job is described in the resource specification language
Discover a
Globus Job Execution
Job is described in the resource specification language
Discover a
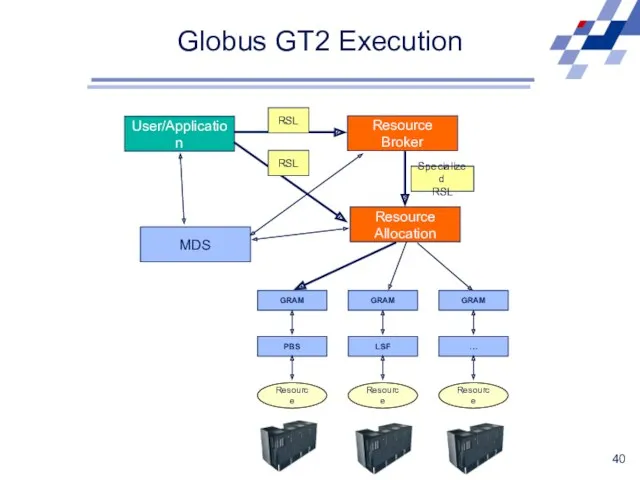
Globus GT2 Execution
User/Application
Resource Broker
Resource
Allocation
MDS
RSL
Specialized
RSL
RSL
Globus GT2 Execution
User/Application
Resource Broker
Resource
Allocation
MDS
RSL
Specialized
RSL
RSL

RSL
Grid jobs are described in the resource specification language (RSL)
RSL Version
RSL
Grid jobs are described in the resource specification language (RSL)
RSL Version

Job Description with RSL2
The version 2 of RSL is XML-based
Two namespaces
Job Description with RSL2
The version 2 of RSL is XML-based
Two namespaces

RSL2 Attributes
(type = rsl:integerType)
Number of processes to run (default is
RSL2 Attributes
Number of processes to run (default is

Job Submission Tools
GT 3 provides the Java class GramClient
GT 2.x: command
Job Submission Tools
GT 3 provides the Java class GramClient
GT 2.x: command

Globus 2 Job Client Interface
A multirequest specifies multiple resources for a
Globus 2 Job Client Interface
A multirequest specifies multiple resources for a

Globus 2 Job Client Interface
The full flexibility of RSL is available
Globus 2 Job Client Interface
The full flexibility of RSL is available

Problem: Job Submission Descriptions differ
The deliverables of the GGF Working Group
Problem: Job Submission Descriptions differ
The deliverables of the GGF Working Group

JSDL Attribute Categories
The job attribute categories will include:
Job Identity Attributes
ID, owner,
JSDL Attribute Categories
The job attribute categories will include:
Job Identity Attributes
ID, owner,

Grid Scheduling
How to select resources in the Grid?
Grid Scheduling
How to select resources in the Grid?

Different Level of Scheduling
Resource-level scheduler
low-level scheduler, local scheduler, local resource manager
scheduler
Different Level of Scheduling
Resource-level scheduler
low-level scheduler, local scheduler, local resource manager
scheduler

Grid-Level Scheduler
Discovers & selects the appropriate resource(s) for a job
If selected
Grid-Level Scheduler
Discovers & selects the appropriate resource(s) for a job
If selected
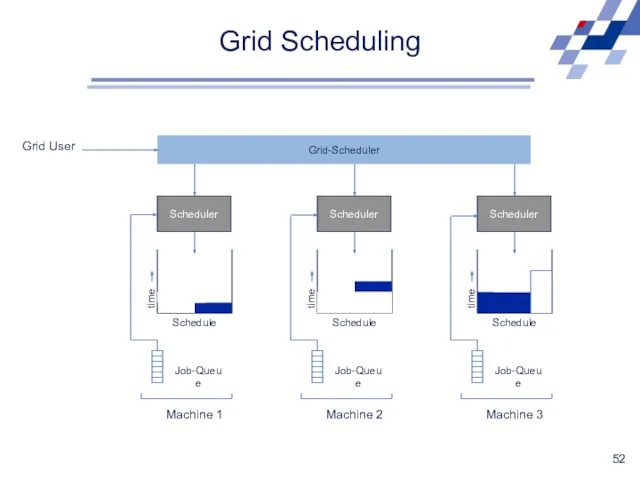
Grid Scheduling
Scheduler
Schedule
time
Job-Queue
Machine 1
Scheduler
Schedule
time
Job-Queue
Machine 2
Scheduler
Schedule
time
Job-Queue
Machine 3
Grid-Scheduler
Grid User
Grid Scheduling
Scheduler
Schedule
time
Job-Queue
Machine 1
Scheduler
Schedule
time
Job-Queue
Machine 2
Scheduler
Schedule
time
Job-Queue
Machine 3
Grid-Scheduler
Grid User
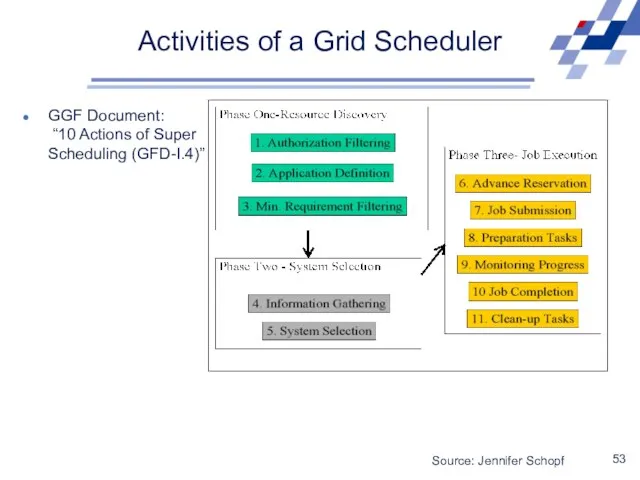
Activities of a Grid Scheduler
GGF Document:
“10 Actions of Super Scheduling
Activities of a Grid Scheduler
GGF Document: “10 Actions of Super Scheduling

Grid Scheduling
A Grid scheduler allows the user to specify the required
Grid Scheduling
A Grid scheduler allows the user to specify the required

Select a Resource for Execution
Most systems do not provide advance information
Select a Resource for Execution
Most systems do not provide advance information

Selection Criteria
Distribute jobs in order to balance load across resources
not suitable
Selection Criteria
Distribute jobs in order to balance load across resources
not suitable

Co-allocation
It is often requested that several resources are used for a
Co-allocation
It is often requested that several resources are used for a
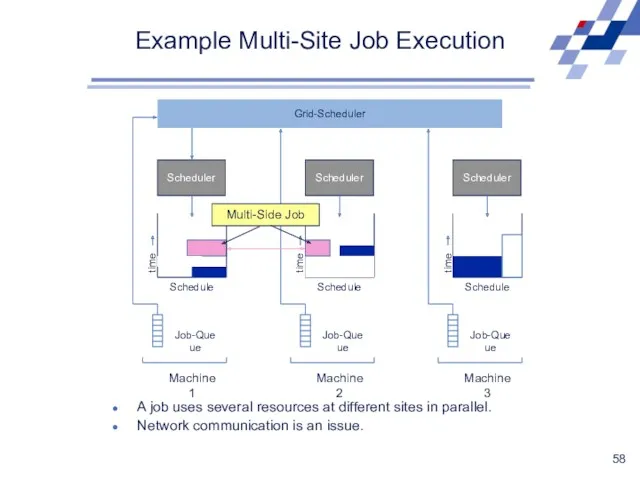
Example Multi-Site Job Execution
A job uses several resources at different sites
Example Multi-Site Job Execution
A job uses several resources at different sites

Advanced Reservation
Co-allocation and other applications require a priori information about the
Advanced Reservation
Co-allocation and other applications require a priori information about the
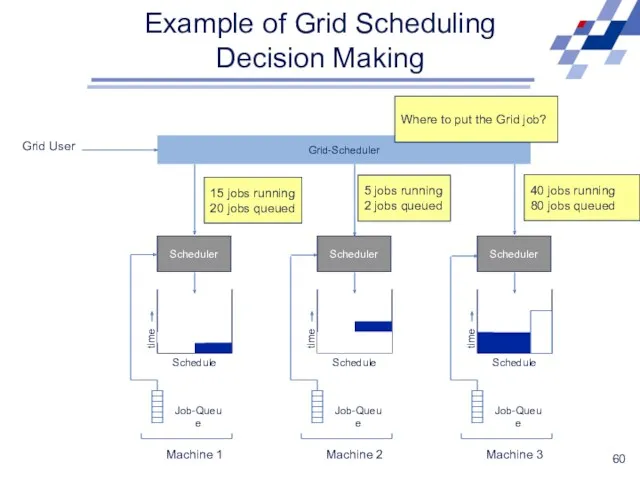
Example of Grid Scheduling Decision Making
Scheduler
Schedule
time
Job-Queue
Machine 1
Scheduler
Schedule
time
Job-Queue
Machine 2
Scheduler
Schedule
time
Job-Queue
Machine 3
Grid-Scheduler
Grid User
15 jobs
Example of Grid Scheduling Decision Making
Scheduler
Schedule
time
Job-Queue
Machine 1
Scheduler
Schedule
time
Job-Queue
Machine 2
Scheduler
Schedule
time
Job-Queue
Machine 3
Grid-Scheduler
Grid User
15 jobs

Available Information from the Local Schedulers
Decision making is difficult for the
Available Information from the Local Schedulers
Decision making is difficult for the

Consequence
Consider a workflow with 3 short steps (e.g. 1 minute each)
Consequence
Consider a workflow with 3 short steps (e.g. 1 minute each)
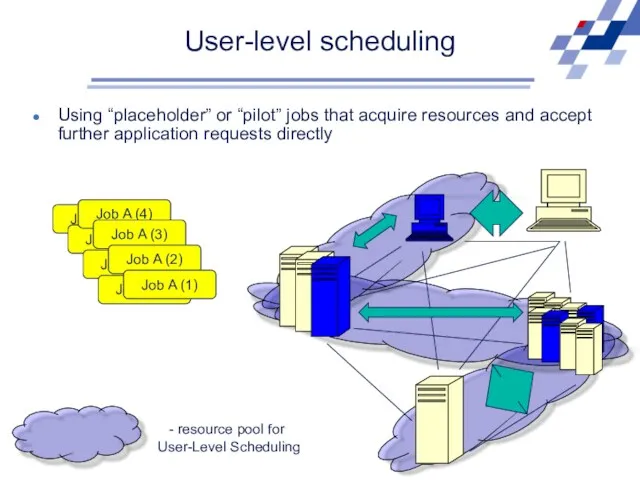
Job A (4)
Job A (3)
Job A (2)
Job A (1)
resource pool
Job A (4)
Job A (3)
Job A (2)
Job A (1)
resource pool

Data and Network Scheduling
Most new resource types can be included via
Data and Network Scheduling
Most new resource types can be included via

Data Management
Access to information about the location of data sets
Information about
Data Management
Access to information about the location of data sets
Information about

Example of a Scheduling Process
Scheduling Service:
receives job description
queries Information Service for
Example of a Scheduling Process
Scheduling Service:
receives job description
queries Information Service for

Re-Scheduling
Reconsidering a schedule with already made agreements may be a good
Re-Scheduling
Reconsidering a schedule with already made agreements may be a good

Computational Economy in Resource Management
“Observe Grid characteristics and current resource management
Computational Economy in Resource Management
“Observe Grid characteristics and current resource management
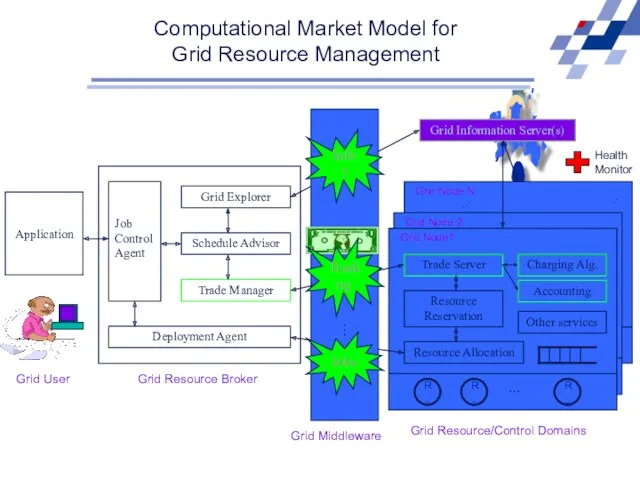
Computational Market Model for
Grid Resource Management
Grid User
Application
Grid Resource Broker
Grid Resource/Control
Computational Market Model for
Grid Resource Management
Grid User
Application
Grid Resource Broker
Grid Resource/Control

Conclusion
Resource management and scheduling is a key service in an Next
Conclusion
Resource management and scheduling is a key service in an Next
 Мотивация персонала вебинар 02 09 2016
Мотивация персонала вебинар 02 09 2016 Комплексная экспертиза конкурса Лидеры России
Комплексная экспертиза конкурса Лидеры России Комплекс услуг по агентированию судов. Управляющая компания Максима
Комплекс услуг по агентированию судов. Управляющая компания Максима Корпоративная аналитика для ресторанного бизнеса
Корпоративная аналитика для ресторанного бизнеса Статистические методы управления качеством
Статистические методы управления качеством Управление временем. 12 правил эффективного тайм-менеджмента
Управление временем. 12 правил эффективного тайм-менеджмента Теории мотивации. Содержательная и процессуальная теории мотивации
Теории мотивации. Содержательная и процессуальная теории мотивации Обеспечение транспортно-логистических терминалов. Эксплуатация и автоматизация работы портов. Опасные грузы. (Тема 3)
Обеспечение транспортно-логистических терминалов. Эксплуатация и автоматизация работы портов. Опасные грузы. (Тема 3) Теория принятия решений в условиях риска и неопределенности
Теория принятия решений в условиях риска и неопределенности Планирование деятельности организации
Планирование деятельности организации Функции управления. Тема 3
Функции управления. Тема 3 Специфичні послуги ресторанів
Специфичні послуги ресторанів Формирование механизмов управления трудовыми затратами предприятия промышленной группы Седин г. Краснодар
Формирование механизмов управления трудовыми затратами предприятия промышленной группы Седин г. Краснодар Методы исследований в менеджменте. Основные понятия
Методы исследований в менеджменте. Основные понятия Motivation. The process of motivation
Motivation. The process of motivation Менеджмент организации
Менеджмент организации Основная информация по VPO (колонна People)
Основная информация по VPO (колонна People) Прогнозирование при принятии УР
Прогнозирование при принятии УР Адаптация персонала в гостиницах
Адаптация персонала в гостиницах Мораль и нравы. Специфика национальных нравов и их роль в сфере управления
Мораль и нравы. Специфика национальных нравов и их роль в сфере управления Менеджмент операций
Менеджмент операций Управление рисками в организации
Управление рисками в организации Кроссворд по теме Методы менеджмента
Кроссворд по теме Методы менеджмента У Управление человеческими ресурсами проекта
У Управление человеческими ресурсами проекта Основы управления персоналом
Основы управления персоналом Ошибки главы компании General Motors
Ошибки главы компании General Motors Manager and Management
Manager and Management Совершенствование методов обучения персонала
Совершенствование методов обучения персонала