- Big Date (Большие данные)

Содержание
- 2. Большие данные — совокупность подходов, инструментов и методов обработки структурированных и неструктурированных данных огромных объёмов и
- 3. NoSQL NoSQL в информатике — термин, обозначающий ряд подходов, направленных на реализацию хранилищ баз данных, имеющих
- 4. Введение термина «большие данные» относят к Клиффорду Линчу, редактору журнала Nature, 3 сентября 2008 года
- 5. В 2011 году Gartner (исследовательская и консалтинговая компания, специализирующаяся на рынках информационных технологий. ) отмечает большие
- 6. Существуют разные определения больших данных, но большинство из них базируется на концепции «трех V» больших данных:
- 7. В большинстве случаев работа с большими данными подразумевает стандартный рабочий процесс: от сбора необработанных данных и
- 8. Принципы работы с большими данными 1. Горизонтальная масштабируемость 2.Отказоустойчивость 3.Локальность данных Все современные средства работы с
- 9. MapReduce предполагает, что данные организованы в виде некоторых записей. Обработка данных происходит в 3 стадии: Стадия
- 10. Примеры задач, эффективно решаемых при помощи MapReduce
- 11. Word Count Имеется большой корпус документов. Задача – для каждого слова, хотя бы один раз встречающегося
- 13. Скачать презентацию

Большие данные — совокупность подходов, инструментов и методов обработки структурированных
Большие данные — совокупность подходов, инструментов и методов обработки структурированных

NoSQL
NoSQL в информатике — термин, обозначающий ряд подходов, направленных на
NoSQL
NoSQL в информатике — термин, обозначающий ряд подходов, направленных на

Введение термина «большие данные» относят к Клиффорду Линчу, редактору журнала
Введение термина «большие данные» относят к Клиффорду Линчу, редактору журнала

В 2011 году Gartner (исследовательская и консалтинговая компания, специализирующаяся на
В 2011 году Gartner (исследовательская и консалтинговая компания, специализирующаяся на

Существуют разные определения больших данных, но большинство из них базируется
Существуют разные определения больших данных, но большинство из них базируется

В большинстве случаев работа с большими данными подразумевает стандартный рабочий процесс:
В большинстве случаев работа с большими данными подразумевает стандартный рабочий процесс:

Принципы работы с большими данными
1. Горизонтальная масштабируемость
2.Отказоустойчивость
3.Локальность данных
Все современные средства работы
Принципы работы с большими данными
1. Горизонтальная масштабируемость
2.Отказоустойчивость
3.Локальность данных
Все современные средства работы
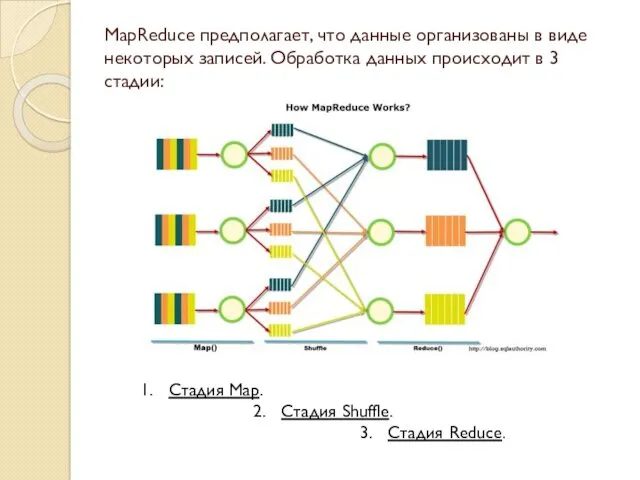
MapReduce предполагает, что данные организованы в виде некоторых записей. Обработка данных
MapReduce предполагает, что данные организованы в виде некоторых записей. Обработка данных

Примеры задач, эффективно решаемых при помощи MapReduce
Примеры задач, эффективно решаемых при помощи MapReduce

Word Count
Имеется большой корпус документов. Задача – для каждого слова,
Word Count
Имеется большой корпус документов. Задача – для каждого слова,
 Ветераны Великой Отечественной войны - сотрудники САФУ
Ветераны Великой Отечественной войны - сотрудники САФУ презентация к статье Использование технологии критического мышления на уроках чтения и окружающего мира.
презентация к статье Использование технологии критического мышления на уроках чтения и окружающего мира. Подготовка кадрового состава для организаций отдыха и оздоровления детей в условиях педагогического вуза
Подготовка кадрового состава для организаций отдыха и оздоровления детей в условиях педагогического вуза 6.4. Системы управления оборудованием ТЗА
6.4. Системы управления оборудованием ТЗА Художественная культура России в XVIII веке
Художественная культура России в XVIII веке Роль медицинской сестры в охране репродуктивного здоровья и планирования семьи
Роль медицинской сестры в охране репродуктивного здоровья и планирования семьи Отдел продаж Skoda. Итоги за март 2018 года
Отдел продаж Skoda. Итоги за март 2018 года Измерение влажности воздуха
Измерение влажности воздуха Тибетский тест личности
Тибетский тест личности Дербес компьютер. Компьютердің құрылысы
Дербес компьютер. Компьютердің құрылысы Закят: очищение имущества и залог процветания общества
Закят: очищение имущества и залог процветания общества День знаний для 2 класса.
День знаний для 2 класса. Компетенция в процессе обучения
Компетенция в процессе обучения Образование, наука, техника и технологии. Методы научного познания
Образование, наука, техника и технологии. Методы научного познания Строительные грузы и их транспортировка
Строительные грузы и их транспортировка Александр II Освободитель 1855-1881
Александр II Освободитель 1855-1881 Нобелевская премия
Нобелевская премия Пи́ттсбург Пи́нгвинз— профессиональный хоккейный клуб
Пи́ттсбург Пи́нгвинз— профессиональный хоккейный клуб Основные виды дефектов, причины и способы их устранения
Основные виды дефектов, причины и способы их устранения Что такое текст? 5 класс
Что такое текст? 5 класс Проектирование цифровых устройств на ПЛИС
Проектирование цифровых устройств на ПЛИС Основные положения и принципы клинической эпидемиологии, связь клинической эпидемиологии с биостатистикой
Основные положения и принципы клинической эпидемиологии, связь клинической эпидемиологии с биостатистикой Ингибиторы протонной помпы
Ингибиторы протонной помпы Использование русских народных и шумовых инструментов на праздниках и развлечениях в ДОУ.
Использование русских народных и шумовых инструментов на праздниках и развлечениях в ДОУ. Количество вещества, число Авогадро, молярная масса, молярный объём, уравнение связи
Количество вещества, число Авогадро, молярная масса, молярный объём, уравнение связи Погрузчики. Виды погрузчиков
Погрузчики. Виды погрузчиков Краудфандинг - народное финансирование
Краудфандинг - народное финансирование Грошове забезпечення у березні - квітні 2018 року
Грошове забезпечення у березні - квітні 2018 року