Элементы оборудования информационно-вычислительных комплексов. Системные шины. (Лекция 3а) презентация
- Элементы оборудования информационно-вычислительных комплексов. Системные шины. (Лекция 3а)

Содержание
- 2. Шины Шины расширений ISA - Indastrial Standart Architecture, (1984), 5.5 MB/c, 16 разр. (данные), 6 уст.;
- 3. Интерфейсные шины Интерфейсы внешних запоминающих устройств ATA - Advanced Technology Attachment (Усовершенствованная технология соединения), ориентирован на
- 4. Интерфейсы устройств ввода-вывода 1. Параллельный ИФ. LPT-порт, Line PrintTer, еще называется SPP - Standart Parallel Port,
- 5. Интерфейсы устройств ввода-вывода 2. Последовательный ИФ. COM - порт, Communication, двунаправленный, до 4 портов, скорости обмена
- 6. Архитектура компьютера, построенная на мезонинной технологии Процессор Вторичный кэш Оперативная память Чип-сет AGP Устройства PCI Устройства
- 7. Системная микросхема (чипсет) 2 базовые микросхемы: северный и южный мост. Северный мост обеспечивает управление: шиной ОП,
- 8. 2.1.2. Специализированные системные шины. Особенности промышленных компьютеров. VME - bus, поддерживает 8/16/32/64 разрядные архитектуры, пропускная способность
- 9. 2.2. Архитектура современных процессоров Двумя основными архитектурами набора команд, используемыми компьютерной промышленностью на современном этапе развития
- 10. Основоположником CISC-архитектуры можно считать компанию IBM с ее базовой архитектурой /360, ядро которой используется с1964 года
- 11. Основой архитектуры современных рабочих станций и серверов является архитектура компьютера с сокращенным набором команд (RISC -
- 12. В 1980 году Д.Паттерсон со своими коллегами из Беркли начали свой проект и изготовили две машины,
- 13. Эти три машины имели много общего. Все они придерживались архитектуры, отделяющей команды обработки от команд работы
- 14. Отметим, что разработках компании Intel (имеется в виду Pentium P54C и процессор следующего поколения P6), а
- 15. Традиционная архитектура процессора Программа Блок целочисленной арифметики Блок памяти Блок плавающей арифметики Память данных К системной
- 16. Архитектура RISC - процессора Блок плавающей арифметик Блок обработки ветвлений Блок целочисленной арифметик Блок распределения команд
- 17. Cуперскалярные и суперконвейерные процессоры. Примеры реализации. Суперконвейерный подход: каждая команда процессора разбивается на возможно большее количество
- 19. Скачать презентацию

Шины
Шины расширений
ISA - Indastrial Standart Architecture, (1984), 5.5 MB/c, 16 разр.
Шины
Шины расширений
ISA - Indastrial Standart Architecture, (1984), 5.5 MB/c, 16 разр.

Интерфейсные шины
Интерфейсы внешних запоминающих устройств
ATA - Advanced Technology Attachment (Усовершенствованная технология
Интерфейсные шины
Интерфейсы внешних запоминающих устройств
ATA - Advanced Technology Attachment (Усовершенствованная технология

Интерфейсы устройств ввода-вывода
1. Параллельный ИФ.
LPT-порт, Line PrintTer, еще называется SPP
Интерфейсы устройств ввода-вывода
1. Параллельный ИФ.
LPT-порт, Line PrintTer, еще называется SPP

Интерфейсы устройств ввода-вывода
2. Последовательный ИФ.
COM - порт, Communication, двунаправленный, до 4
Интерфейсы устройств ввода-вывода
2. Последовательный ИФ.
COM - порт, Communication, двунаправленный, до 4
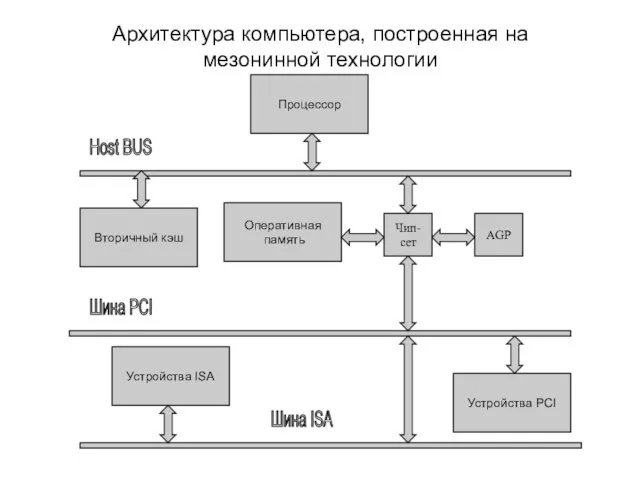
Архитектура компьютера, построенная на мезонинной технологии
Процессор
Вторичный кэш
Оперативная
память
Чип-сет
AGP
Устройства PCI
Устройства ISA
Host
Архитектура компьютера, построенная на мезонинной технологии
Процессор
Вторичный кэш
Оперативная
память
Чип-сет
AGP
Устройства PCI
Устройства ISA
Host

Системная микросхема (чипсет)
2 базовые микросхемы: северный и южный мост.
Северный мост обеспечивает
Системная микросхема (чипсет)
2 базовые микросхемы: северный и южный мост.
Северный мост обеспечивает

2.1.2. Специализированные системные шины. Особенности промышленных компьютеров.
VME - bus, поддерживает 8/16/32/64
2.1.2. Специализированные системные шины. Особенности промышленных компьютеров.
VME - bus, поддерживает 8/16/32/64

2.2. Архитектура современных процессоров
Двумя основными архитектурами набора команд, используемыми компьютерной промышленностью
2.2. Архитектура современных процессоров
Двумя основными архитектурами набора команд, используемыми компьютерной промышленностью

Основоположником CISC-архитектуры можно считать компанию IBM с ее базовой архитектурой /360,
Основоположником CISC-архитектуры можно считать компанию IBM с ее базовой архитектурой /360,

Основой архитектуры современных рабочих станций и серверов является архитектура компьютера с
Основой архитектуры современных рабочих станций и серверов является архитектура компьютера с

В 1980 году Д.Паттерсон со своими коллегами из Беркли начали свой
В 1980 году Д.Паттерсон со своими коллегами из Беркли начали свой

Эти три машины имели много общего. Все они придерживались
Эти три машины имели много общего. Все они придерживались

Отметим, что разработках компании Intel (имеется в виду Pentium P54C
Отметим, что разработках компании Intel (имеется в виду Pentium P54C
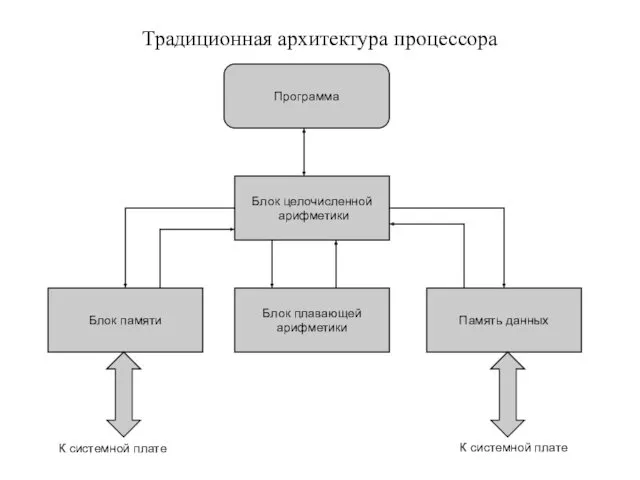
Традиционная архитектура процессора
Программа
Блок целочисленной
арифметики
Блок памяти
Блок плавающей
арифметики
Память данных
К системной
Традиционная архитектура процессора
Программа
Блок целочисленной
арифметики
Блок памяти
Блок плавающей
арифметики
Память данных
К системной
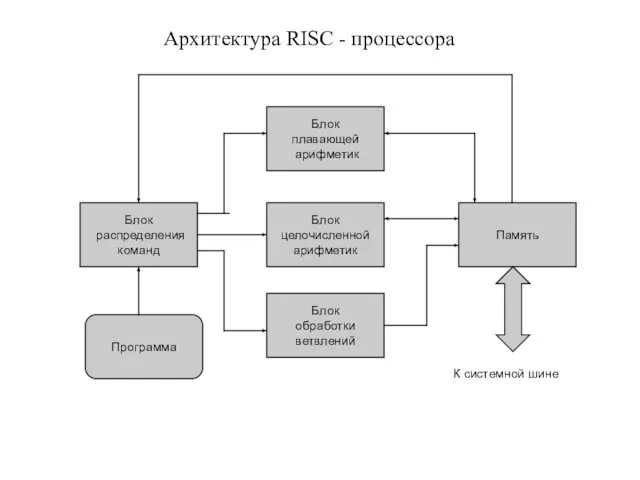
Архитектура RISC - процессора
Блок
плавающей
арифметик
Блок
обработки
ветвлений
Блок
целочисленной
арифметик
Блок
распределения
команд
Память
Программа
К системной шине
Архитектура RISC - процессора
Блок
плавающей
арифметик
Блок
обработки
ветвлений
Блок
целочисленной
арифметик
Блок
распределения
команд
Память
Программа
К системной шине

Cуперскалярные и суперконвейерные процессоры. Примеры реализации.
Суперконвейерный подход:
каждая команда процессора разбивается на
Cуперскалярные и суперконвейерные процессоры. Примеры реализации.
Суперконвейерный подход:
каждая команда процессора разбивается на
 Анализ назначения технологических машин
Анализ назначения технологических машин Презентация Год культуры, история Кубани в лицах
Презентация Год культуры, история Кубани в лицах Проектирование научно-исследовательской деятельности школьников
Проектирование научно-исследовательской деятельности школьников Отчет по программе Дети. Творчество. Родина за 2012-2013 учебный год
Отчет по программе Дети. Творчество. Родина за 2012-2013 учебный год Типы и виды экономических систем
Типы и виды экономических систем Анализ устойчивости линейных непрерывных систем
Анализ устойчивости линейных непрерывных систем Основы технологии возведения зданий и инженерных сооружений. Тема 1.2
Основы технологии возведения зданий и инженерных сооружений. Тема 1.2 Логопедическая викторина для детей старшего дошкольного возраста
Логопедическая викторина для детей старшего дошкольного возраста Индивидуализация в процессе обучения техническому творчеству в СПО
Индивидуализация в процессе обучения техническому творчеству в СПО Мотивации персонала магазина франчайзи
Мотивации персонала магазина франчайзи Электрические цепи переменного тока
Электрические цепи переменного тока Кирилл и Мефодий. Гимн и Величание
Кирилл и Мефодий. Гимн и Величание Цесарка - птица царская
Цесарка - птица царская Финикийские мореплаватели
Финикийские мореплаватели Глухие фундаментные болты
Глухие фундаментные болты Средства электронной таблицы для работы с базой данных
Средства электронной таблицы для работы с базой данных Системы булевых функций
Системы булевых функций Первообразная. Интеграл
Первообразная. Интеграл Сборка ПК для работы в 3D графикой за 160 000р
Сборка ПК для работы в 3D графикой за 160 000р Призентация Полимеры
Призентация Полимеры Витамины - эликсиры жизни
Витамины - эликсиры жизни Топографическая анатомия надплечья (suprabrachium)
Топографическая анатомия надплечья (suprabrachium) Türkçe 4
Türkçe 4 Общие вопросы тератологии
Общие вопросы тератологии Относительные мест
Относительные мест Заболевания эндокарда
Заболевания эндокарда Презентация к уроку Основные классы неорганических веществ.
Презентация к уроку Основные классы неорганических веществ. обучение детей иностранному языку
обучение детей иностранному языку