Проект повышения конкурентоспособности ведущих российских университетов среди ведущих мировых научно-образовательных центров презентация
- Проект повышения конкурентоспособности ведущих российских университетов среди ведущих мировых научно-образовательных центров

Содержание
- 2. Гергель В.П., Сысоев А.В. Кафедра МОСТ Лекция 02 Коллективные и парные взаимодействия Параллельное программирование для многопроцессорных
- 3. Содержание Коллективное взаимодействие Широковещательный обмен Операции редукции Пример: вычисление числа π Рассылка и сбор данных Пример:
- 4. КОЛЛЕКТИВНОЕ ВЗАИМОДЕЙСТВИЕ Широковещательный обмен Операции редукции Пример: вычисление числа π Рассылка и сбор данных Пример: вычисление
- 5. Коллективное взаимодействие… Широковещательный обмен Для эффективного широковещательного обмена данными следует использовать следующую функцию MPI: Функция MPI_Bcast()
- 6. Коллективное взаимодействие… Широковещательный обмен Функция MPI_Bcast() коллективная, ее вызов должен быть выполнен всеми процессами коммуникатора comm
- 7. Коллективное взаимодействие… Редукция данных Чтобы “редуцировать” данные со всех процессов в один выбранный, используется следующая функция
- 8. Коллективное взаимодействие… Редукция данных Базовые типы операций MPI для редукции данных Коллективные и парные взаимодействия Н.
- 9. Коллективное взаимодействие… Редукция данных Функция MPI_Reduce() коллективная, ее вызов должен быть выполнен всеми процессами коммуникатора comm.
- 10. Коллективное взаимодействие… Пример: вычисление числа π Значение π может быть вычислено через интеграл Для вычисления определенного
- 11. Коллективное взаимодействие… Пример: вычисление числа π Для распределения вычислений между процессами может использоваться циклическая схема Частичные
- 12. Коллективное взаимодействие… Пример: вычисление числа π #include "mpi.h" #include double f(double a){ return (4.0 / (1.0
- 13. Коллективное взаимодействие… Пример: вычисление числа π MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD); if (n > 0){ //
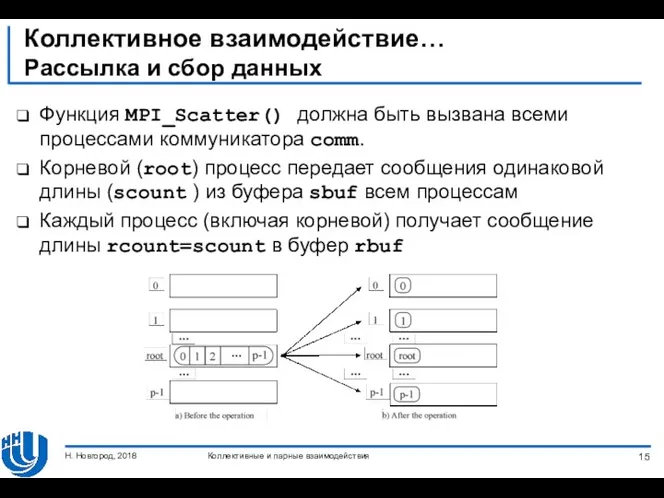
- 14. Коллективное взаимодействие… Рассылка и сбор данных Чтобы распределить (“scatter”) данные от выбранного процесса остальным, используется следующая
- 15. Коллективное взаимодействие… Рассылка и сбор данных Функция MPI_Scatter() должна быть вызвана всеми процессами коммуникатора comm. Корневой
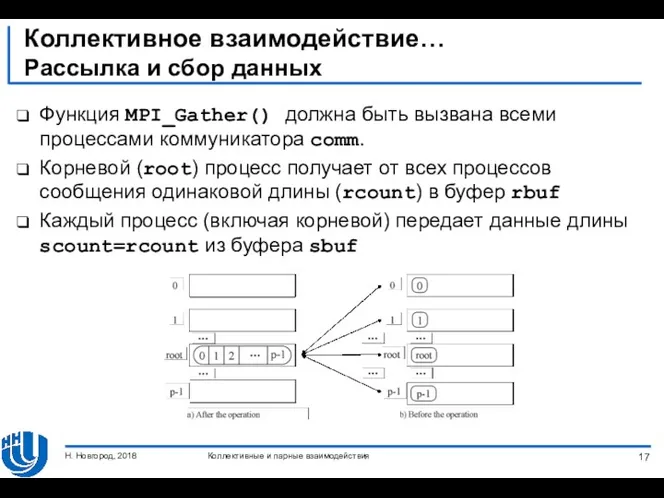
- 16. Коллективное взаимодействие… Рассылка и сбор данных Операция сбора данных от всех процессов в один противоположна рассылке.
- 17. Коллективное взаимодействие… Рассылка и сбор данных Функция MPI_Gather() должна быть вызвана всеми процессами коммуникатора comm. Корневой
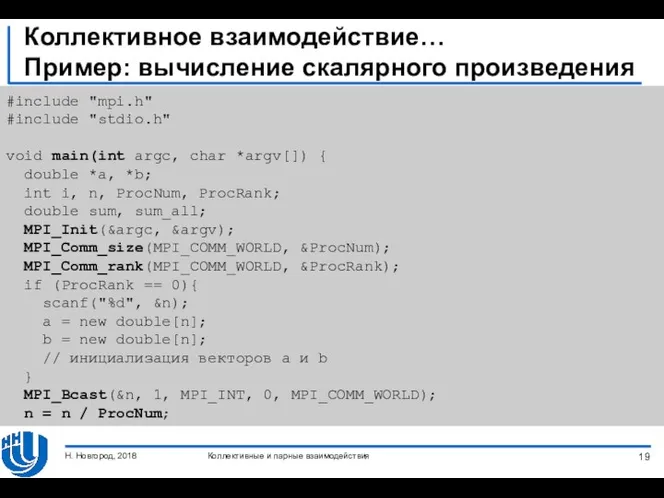
- 18. Коллективное взаимодействие… Пример: вычисление скалярного произведения Рассмотрим следующую задачу: Для разработки параллельной реализации необходимо: разбить векторы
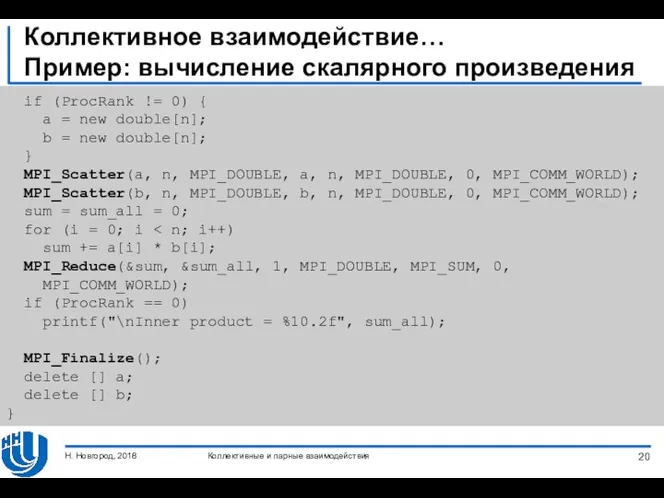
- 19. Коллективное взаимодействие… Пример: вычисление скалярного произведения #include "mpi.h" #include "stdio.h" void main(int argc, char *argv[]) {
- 20. Коллективное взаимодействие… Пример: вычисление скалярного произведения if (ProcRank != 0) { a = new double[n]; b
- 21. Коллективное взаимодействие… Взаимодействие «Каждый к каждому» Чтобы получить все собранные данные в каждом процессе коммуникатора, необходимо
- 22. Коллективное взаимодействие… Взаимодействие «Каждый к каждому» Обмен данными между процессами выполняется функцией В случае, если сообщения
- 23. Коллективное взаимодействие… Взаимодействие «Каждый к каждому» Функция MPI_Reduce() позволяет получить данные только в одном процессе Для
- 24. Коллективное взаимодействие… Синхронизация вычислений Синхронизация, т.е. одновременное достижение разными процессами параллельной программы одной точки, выполняется функцией
- 25. ВЗАИМОДЕЙСТВИЕ МЕЖДУ ДВУМЯ ПРОЦЕССАМИ Режимы взаимодействия Неблокирующее взаимодействие Совмещенные прием и передача сообщений Коллективные и парные
- 26. Взаимодействие между двумя процессами… Режимы взаимодействия Стандартный (Standard) режим: Предоставляется функцией MPI_Send() Отправляющий процесс блокируется на
- 27. Взаимодействие между двумя процессами… Режимы взаимодействия Синхронный (Synchronous) режим Функция передачи завершается лишь после подтверждения от
- 28. Взаимодействие между двумя процессами… Режимы взаимодействия Буферизированный (Buffered) режим Предполагает использование дополнительного буфера для копирования передаваемых
- 29. Взаимодействие между двумя процессами… Режимы взаимодействия Режим по готовности формально самый быстрый, но используется довольно редко,
- 30. Взаимодействие между двумя процессами… Неблокирующие взаимодействие Блокирующие функции блокируют выполнение до тех пор, пока вызываемая функция
- 31. Взаимодействие между двумя процессами… Неблокирующие взаимодействие Имена неблокирующих функций отличаются от соответствующих блокирующих префиксом I (Immediate,
- 32. Взаимодействие между двумя процессами… Неблокирующие взаимодействие Состояние выполнения неблокирующей функции может быть проверено вызовом следующей функции
- 33. Взаимодействие между двумя процессами… Неблокирующие взаимодействие Возможна следующая схема совмещения вычислений и неблокирующего взаимодействия Блокирующее ожидание
- 34. Взаимодействие между двумя процессами… Неблокирующие взаимодействие Дополнительные функции проверки и ожидания для неблокирующих операций обмена MPI_Testall
- 35. Взаимодействие между двумя процессами… Совмещенные прием и передача сообщении Эффективное одновременное выполнение приема и передачи данных
- 36. Резюме Рассмотрены операции коллективного взаимодействия Разобрано взаимодействие между двумя процессами Детально описаны режимы выполнения операций (стандартный,
- 37. Упражнения Разработать простую программу для демонстрации каждой коллективной операции, доступной в MPI. Разработать реализацию коллективных операций
- 39. Скачать презентацию

Гергель В.П., Сысоев А.В.
Кафедра МОСТ
Лекция 02
Коллективные и парные
взаимодействия
Параллельное программирование для
Гергель В.П., Сысоев А.В.
Кафедра МОСТ
Лекция 02
Коллективные и парные
взаимодействия
Параллельное программирование для

Содержание
Коллективное взаимодействие
Широковещательный обмен
Операции редукции
Пример: вычисление числа π
Рассылка и сбор данных
Пример: вычисление
Содержание
Коллективное взаимодействие
Широковещательный обмен
Операции редукции
Пример: вычисление числа π
Рассылка и сбор данных
Пример: вычисление

КОЛЛЕКТИВНОЕ ВЗАИМОДЕЙСТВИЕ
Широковещательный обмен
Операции редукции
Пример: вычисление числа π
Рассылка и сбор данных
Пример: вычисление
КОЛЛЕКТИВНОЕ ВЗАИМОДЕЙСТВИЕ
Широковещательный обмен
Операции редукции
Пример: вычисление числа π
Рассылка и сбор данных
Пример: вычисление

Коллективное взаимодействие…
Широковещательный обмен
Для эффективного широковещательного обмена данными следует использовать следующую функцию
Коллективное взаимодействие…
Широковещательный обмен
Для эффективного широковещательного обмена данными следует использовать следующую функцию

Коллективное взаимодействие…
Широковещательный обмен
Функция MPI_Bcast() коллективная, ее вызов должен быть выполнен всеми
Коллективное взаимодействие…
Широковещательный обмен
Функция MPI_Bcast() коллективная, ее вызов должен быть выполнен всеми

Коллективное взаимодействие…
Редукция данных
Чтобы “редуцировать” данные со всех процессов в один выбранный,
Коллективное взаимодействие…
Редукция данных
Чтобы “редуцировать” данные со всех процессов в один выбранный,

Коллективное взаимодействие…
Редукция данных
Базовые типы операций MPI для редукции данных
Коллективные и парные
Коллективное взаимодействие…
Редукция данных
Базовые типы операций MPI для редукции данных
Коллективные и парные

Коллективное взаимодействие…
Редукция данных
Функция MPI_Reduce() коллективная, ее вызов должен быть выполнен всеми
Коллективное взаимодействие…
Редукция данных
Функция MPI_Reduce() коллективная, ее вызов должен быть выполнен всеми
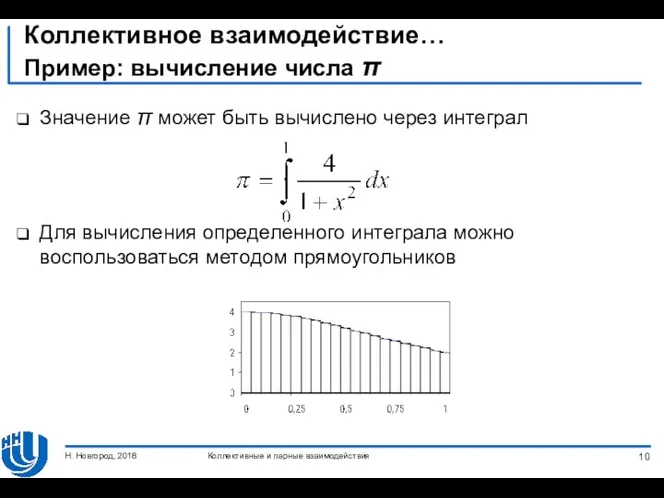
Коллективное взаимодействие…
Пример: вычисление числа π
Значение π может быть вычислено через интеграл
Для
Коллективное взаимодействие…
Пример: вычисление числа π
Значение π может быть вычислено через интеграл
Для
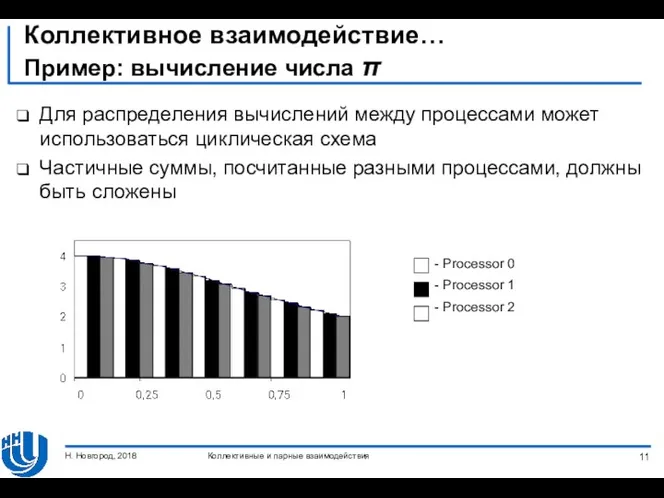
Коллективное взаимодействие…
Пример: вычисление числа π
Для распределения вычислений между процессами может использоваться
Коллективное взаимодействие…
Пример: вычисление числа π
Для распределения вычислений между процессами может использоваться
Коллективное взаимодействие…
Пример: вычисление числа π
#include "mpi.h"
#include
double f(double a){
Коллективное взаимодействие…
Пример: вычисление числа π
#include "mpi.h"
#include
double f(double a){
Коллективное взаимодействие…
Пример: вычисление числа π
MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);
Коллективное взаимодействие…
Пример: вычисление числа π
MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);

Коллективное взаимодействие…
Рассылка и сбор данных
Чтобы распределить (“scatter”) данные от выбранного процесса
Коллективное взаимодействие…
Рассылка и сбор данных
Чтобы распределить (“scatter”) данные от выбранного процесса
Коллективное взаимодействие…
Рассылка и сбор данных
Функция MPI_Scatter() должна быть вызвана всеми процессами
Коллективное взаимодействие…
Рассылка и сбор данных
Функция MPI_Scatter() должна быть вызвана всеми процессами

Коллективное взаимодействие…
Рассылка и сбор данных
Операция сбора данных от всех процессов в
Коллективное взаимодействие…
Рассылка и сбор данных
Операция сбора данных от всех процессов в
Коллективное взаимодействие…
Рассылка и сбор данных
Функция MPI_Gather() должна быть вызвана всеми процессами
Коллективное взаимодействие…
Рассылка и сбор данных
Функция MPI_Gather() должна быть вызвана всеми процессами

Коллективное взаимодействие…
Пример: вычисление скалярного произведения
Рассмотрим следующую задачу:
Для разработки параллельной реализации необходимо:
разбить
Коллективное взаимодействие…
Пример: вычисление скалярного произведения
Рассмотрим следующую задачу:
Для разработки параллельной реализации необходимо:
разбить
Коллективное взаимодействие…
Пример: вычисление скалярного произведения
#include "mpi.h"
#include "stdio.h"
void main(int argc, char *argv[])
Коллективное взаимодействие…
Пример: вычисление скалярного произведения
#include "mpi.h"
#include "stdio.h"
void main(int argc, char *argv[])
Коллективное взаимодействие…
Пример: вычисление скалярного произведения
if (ProcRank != 0) {
a
Коллективное взаимодействие…
Пример: вычисление скалярного произведения
if (ProcRank != 0) {
a

Коллективное взаимодействие…
Взаимодействие «Каждый к каждому»
Чтобы получить все собранные данные в каждом
Коллективное взаимодействие…
Взаимодействие «Каждый к каждому»
Чтобы получить все собранные данные в каждом

Коллективное взаимодействие…
Взаимодействие «Каждый к каждому»
Обмен данными между процессами выполняется функцией
В случае,
Коллективное взаимодействие…
Взаимодействие «Каждый к каждому»
Обмен данными между процессами выполняется функцией
В случае,

Коллективное взаимодействие…
Взаимодействие «Каждый к каждому»
Функция MPI_Reduce() позволяет получить данные только в
Коллективное взаимодействие…
Взаимодействие «Каждый к каждому»
Функция MPI_Reduce() позволяет получить данные только в

Коллективное взаимодействие…
Синхронизация вычислений
Синхронизация, т.е. одновременное достижение разными процессами параллельной программы одной
Коллективное взаимодействие…
Синхронизация вычислений
Синхронизация, т.е. одновременное достижение разными процессами параллельной программы одной

ВЗАИМОДЕЙСТВИЕ МЕЖДУ ДВУМЯ ПРОЦЕССАМИ
Режимы взаимодействия
Неблокирующее взаимодействие
Совмещенные прием и передача сообщений
Коллективные и
ВЗАИМОДЕЙСТВИЕ МЕЖДУ ДВУМЯ ПРОЦЕССАМИ
Режимы взаимодействия
Неблокирующее взаимодействие
Совмещенные прием и передача сообщений
Коллективные и

Взаимодействие между двумя процессами…
Режимы взаимодействия
Стандартный (Standard) режим:
Предоставляется функцией MPI_Send()
Отправляющий процесс
Взаимодействие между двумя процессами…
Режимы взаимодействия
Стандартный (Standard) режим:
Предоставляется функцией MPI_Send()
Отправляющий процесс

Взаимодействие между двумя процессами…
Режимы взаимодействия
Синхронный (Synchronous) режим
Функция передачи завершается лишь
Взаимодействие между двумя процессами…
Режимы взаимодействия
Синхронный (Synchronous) режим
Функция передачи завершается лишь

Взаимодействие между двумя процессами…
Режимы взаимодействия
Буферизированный (Buffered) режим
Предполагает использование дополнительного буфера
Взаимодействие между двумя процессами…
Режимы взаимодействия
Буферизированный (Buffered) режим
Предполагает использование дополнительного буфера

Взаимодействие между двумя процессами…
Режимы взаимодействия
Режим по готовности формально самый быстрый,
Взаимодействие между двумя процессами…
Режимы взаимодействия
Режим по готовности формально самый быстрый,

Взаимодействие между двумя процессами…
Неблокирующие взаимодействие
Блокирующие функции блокируют выполнение до тех пор,
Взаимодействие между двумя процессами…
Неблокирующие взаимодействие
Блокирующие функции блокируют выполнение до тех пор,

Взаимодействие между двумя процессами…
Неблокирующие взаимодействие
Имена неблокирующих функций отличаются от соответствующих блокирующих
Взаимодействие между двумя процессами…
Неблокирующие взаимодействие
Имена неблокирующих функций отличаются от соответствующих блокирующих

Взаимодействие между двумя процессами…
Неблокирующие взаимодействие
Состояние выполнения неблокирующей функции может быть проверено
Взаимодействие между двумя процессами…
Неблокирующие взаимодействие
Состояние выполнения неблокирующей функции может быть проверено

Взаимодействие между двумя процессами…
Неблокирующие взаимодействие
Возможна следующая схема совмещения вычислений и неблокирующего
Взаимодействие между двумя процессами…
Неблокирующие взаимодействие
Возможна следующая схема совмещения вычислений и неблокирующего

Взаимодействие между двумя процессами…
Неблокирующие взаимодействие
Дополнительные функции проверки и ожидания для неблокирующих
Взаимодействие между двумя процессами…
Неблокирующие взаимодействие
Дополнительные функции проверки и ожидания для неблокирующих

Взаимодействие между двумя процессами…
Совмещенные прием и передача сообщении
Эффективное одновременное выполнение приема
Взаимодействие между двумя процессами…
Совмещенные прием и передача сообщении
Эффективное одновременное выполнение приема

Резюме
Рассмотрены операции коллективного взаимодействия
Разобрано взаимодействие между двумя процессами
Детально описаны режимы выполнения
Резюме
Рассмотрены операции коллективного взаимодействия
Разобрано взаимодействие между двумя процессами
Детально описаны режимы выполнения

Упражнения
Разработать простую программу для демонстрации каждой коллективной операции, доступной в MPI.
Разработать
Упражнения
Разработать простую программу для демонстрации каждой коллективной операции, доступной в MPI.
Разработать
 Введение. Siemens
Введение. Siemens Разработка интеграционного модуля выгрузки данных о продажах фотосепараторов на корпоративный сайт ООО Сисорт
Разработка интеграционного модуля выгрузки данных о продажах фотосепараторов на корпоративный сайт ООО Сисорт Be style
Be style Параллельное и распределенное программирование. Технология программирования гетерогенных систем
Параллельное и распределенное программирование. Технология программирования гетерогенных систем Введення в HTML
Введення в HTML Программное обеспечение ЭВМ. (Глава 3)
Программное обеспечение ЭВМ. (Глава 3) Типы, переменные, управляющие инструкции. (Тема 2.1)
Типы, переменные, управляющие инструкции. (Тема 2.1) Защита программного обеспечения от несанкционированного использования
Защита программного обеспечения от несанкционированного использования Сравнительный анализ 5 программных продуктов для моделирования бизнес-процессов организаций
Сравнительный анализ 5 программных продуктов для моделирования бизнес-процессов организаций Установка Microsoft Office
Установка Microsoft Office Методы системного анализа. Лекция 2
Методы системного анализа. Лекция 2 Телекоммуникациялық желілердегі коммутация әдістері
Телекоммуникациялық желілердегі коммутация әдістері LoRa™ Technology
LoRa™ Technology Программирование линейных алгоритмов. Начала программирования. Информатика и ИКТ. 8 класс
Программирование линейных алгоритмов. Начала программирования. Информатика и ИКТ. 8 класс Кодирование текстовой информации. Представление информации в компьютере
Кодирование текстовой информации. Представление информации в компьютере Презентация к уроку Моделирование в программе QCAD
Презентация к уроку Моделирование в программе QCAD Средства мультимедиа
Средства мультимедиа Файлы и файловая система
Файлы и файловая система Единый урок безопасности в сети Интернет
Единый урок безопасности в сети Интернет Space and Time Tradeoffs
Space and Time Tradeoffs ICT in the workplace
ICT in the workplace Стратегия продвижения в соц. сетях
Стратегия продвижения в соц. сетях Network & internet
Network & internet Вводная документация инженера. Beeline. Замена ФН (ФФД 1.05)
Вводная документация инженера. Beeline. Замена ФН (ФФД 1.05) Этапы создания сайта
Этапы создания сайта Диаграмма деятельности
Диаграмма деятельности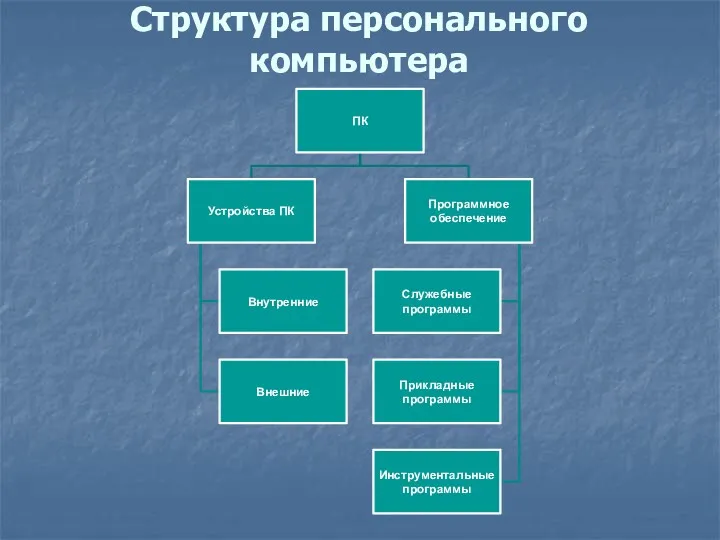 Структура персонального компьютера
Структура персонального компьютера Сервис Интернет. Лекция №3
Сервис Интернет. Лекция №3