- Программирование на Java. Система ввода-вывода Java. (Лекция 8)

Содержание
- 2. Понятие потоков ввода/вывода Потоком ввода/вывода (I/O Stream) называется произвольный источник или приемник, который способен генерировать либо
- 3. Системы ввода/вывода Java Основная система ввода/вывода Java представлена пакетом java.io Пакет java.nio содержит API для работы
- 4. Виды потоков ввода/вывода Всего существует 2 вида потоков ввода/вывода: - байтовые - символьные Байтовые потоки -
- 5. Суперклассы java.io API Все потоки ядра Java (стандартного API) – это потомки 4-х суперклассов, которые являются
- 6. Парные потоки Предназначение каждого класса-потока заключается в том, чтобы передать или принять последовательность символов или байт.
- 9. Класс InputStream Абстрактный класс InputStream предоставляет минимальный набор методов для работы с входным потоком байтов: int
- 10. Потомки класса InputStream ObjectInputStream - поток объектов. Создается при сохранении объектов системными средствами SequenceInputStream - последовательное
- 11. Классы надстройки Классы FilterInputStream, FilterOutputStream; FilterReader, FilterWriter являются, соответственно, классами надстройками над классами InputStream, OutputStream; Reader
- 12. Классы надстройки Основное предназначение надстроек - наделение существующего потока новыми свойствами. Комбинируя исходный поток и классы
- 13. Надстраивание (декорация) В отличие от наследования надстраивание не ведет к появлению большого числа библиотечных классов. Так
- 14. Класс DataInputStream Класс DataInputStream наследует класс надстройку FilterInputStream и позволяет читать данные из входного байтового потока
- 15. Буферизация Для ускорения файловых операций чтения/записи следует использовать буферизированные классы: BufferedInputStream и BufferedReader. BufferedReader in1 =
- 16. Класс BufferedInputStream Класс BufferedInputStream наследует класс надстройку FiltertInputStream. Объект этого класса надстраивает входной байтовый поток и
- 17. Класс PushbackInputStream Класс PushbackInputStream надстраивает входной байтовый поток и позволяет кроме чтения осуществлять запись прочтенных байт
- 18. Поле in класса System Статическое поле in класса System имеет тип InputStream и связано по умолчанию
- 19. Класс OutputStream Абстрактный класс OutputStream предоставляет минимальный набор методов для работы с выходным потоком байтов void
- 20. Потомки класса OutputStream ObjectOutputStream - поток двоичных представлений объектов. Создается при сериализации ByteArrayOutputStream - использует массив
- 21. Надстройки для OutputStream Надстройками для OuptupStream являются наследники абстрактного класса FilterOutputStream PrintStream – добавляет возможность преобразования
- 22. Буферизированный ввод/вывод public class FileCopy { public static void main(String[] args) { try { BufferedInputStream bis
- 23. Символьные потоки Для работы с символьными потоками в Java существуют два базовых класса – Reader и
- 24. Некоторые потомки класса Writer BufferedWriter - буферизированный выводной поток. Размер буфера можно менять, хотя размер, принятый
- 25. Потомки класса Reader BufferedReader - буферизированный вводной поток символов CharArrayReader - позволяет читать символы из массива
- 26. Пример программы Вводить строки с клавиатуры и записывать их в файл на диске. try { //
- 27. Класс OutputStreamWriter Класс OutputStreamWriter наследуется от класса Writer, и преобразует выходной символьный поток в выходной байтовый
- 28. Кодировка по умолчанию При запуске программы кодировку по умолчанию устанавливает JVM в зависимости от операционной системы
- 29. Указание кодировки при компиляции Для правильного отображения строковых литералов, записанных в программе, следует обеспечить правильное конвертирование
- 30. Перекодировка вывода Все строковые литералы в байт коде классов содержаться в формате Unicode. При выводе таких
- 31. Перекодировка вывода PrintWriter out = new PrintWriter(new OutputStreamWriter(System.out, "Cp866"), true); out.println(s); // вывод на экран строки
- 32. Поле out класса System Статическое поле out класса System имеет тип java.io.PrintStream, который представляет собой надстройку
- 33. Класс RandomAccessFile RandomAccessFile применяется для работы с файлами произвольного доступа Для перемещения по файлу в RandomAccessFile
- 34. Пример работы с RandomAccessFile Создать файл прямого доступа, выполнить запись в файл и чтение из файла
- 35. Класс File Класс File предназначен для работы с элементами файловой системы – каталогами и файлами Каждый
- 36. Конструкторы класса File File(String filePath), где filePath – имя файла на диске File(String dirPath, String filePath),
- 37. Каталоги Каталог – это особый файл, который содержит в себе список других файлов и каталогов Для
- 38. Фильтры (интерфейс FileFilter) Интерфейс FileFilter применяется для проверки, подпадает ли объект File под некоторое условие Метод
- 39. Пример работы с фильтрами Выбрать из текущего каталога лишь те файлы, которые содержат в своем последнем
- 40. Новый ввод/вывод Ее цель – увеличение производительности и обеспечения безопасности при одновременном конкурентном доступе к данным
- 41. Буфер Буфер представляет собой контейнер для данных простых типов, таких как byte, int, float и др.
- 42. Методы класса Buffer clear() – подготавливает буфер для операции записи в него данныx Он устанавливает лимит
- 43. Байтовый буфер (ByteBuffer) Байтовый буфер предназначен для работы с байтовыми данными Создать буфер тремя способами: На
- 44. Прямые и непрямые буферы ByteBuffer может быть прямым и непрямым При работе с прямым (direct) буфером
- 45. Чтение-запись данных в буфер Для относительного получения байта данных из буфера используется метод get(), для абсолютного
- 46. Буферы-представления При необходимости работать с однотипными данными лучше использовать классы-представления CharBuffer DoubleBuffer FloatBuffer IntBuffer LongBuffer ShortBuffer
- 47. Пример работы с буфером-представлением public class IntBufferDemo { private static final int BSIZE = 1024; public
- 48. Файловый канал Канал представляет собой открытое соединение к некоторой сущности, такой как, например, аппаратное устройство, файл,
- 49. Работа с FileChannel Файловый канал имеет свою позицию, которая устанавливается методом position(long) Методы read(ByteBuffer) и read(ByteBuffer,
- 50. Пример работы с FileChannel public class GetChannel { private static final int BSIZE = 1024; public
- 51. Копирование файлов с использованием FileChannel public class ChannelCopy { private static final int BSIZE = 1024;
- 52. Более эффективный способ копирования файлов public class TransferTo { public static void main(String[] args) throws Exception
- 53. Блокировка файлов Блокировка файлов осуществляется с помощью методов FileLock lock(…) FileLock tryLock(…) Метод tryLock() не приостанавливает
- 54. Пример блокировки файла Механизм блокировки Java напрямую связан со средствами операционной системы public class FileLocking {
- 55. Файлы, отображаемые в памяти Механизм отображения файлов в память позволяет вам создавать и изменять файлы, размер
- 56. Диаграмма отношений пакета nio
- 57. Сериализация Сериализация позволяет превратить объект в поток байтов, чтобы, когда понадобится, полностью восстановить объект из потока
- 58. Интерфейс Serializable Чтобы обладать способностью к сериализации, класс должен: Реализовать интерфейс-метку Serializable Интерфейс Serializable не содержит
- 59. Запись-чтение объектов Сериализованные объекты можно записывать и считывать при помощи классов ObjectOutputStream и ObjectInputStream. Они таже
- 60. Пример сериализации объектов public class Point implements java.io.Serializable { private int x=0, y = 0; public
- 61. Сериализация наследников несериализуемого класса Если необходимо, чтобы подкласс несериализумого класса мог быть сериализуем, то: Сохранение и
- 62. Пример Если суперкласс сериализуем: public class Point implements Serializable{ public int x = 0; public int
- 63. Пример 2 Если суперкласс несериализуем: public class Point { public int x = 0; public int
- 64. Управление процессом сериализации Для выполнения специальной обработки при сериализации и десериализации класс должен реализовать следующие методы:
- 65. Пример public class PointXYZ extends Point implements Serializable{ private int z = 0; … private void
- 66. Архивирование Библиотека ввода/вывода Java содержит классы, поддерживающие чтение и запись потоков в компрессированном формате Эти классы
- 67. Классы для работы с архивами DeflaterOutputStream – базовый класс для классов компрессии InflaterInputStream – базовый класс
- 68. Работа с ZipOutputSream ZipOutputStream out = new ZipOutputStream(new FileOutputStream(“archive.zip”)); pack("111.txt", out); pack(“222.txt", out); out.close(); // Упаковывает
- 69. Работа с ZipInputStream ZipInputStream in = new ZipInputStream(new BufferedInputStream( new FileInputStream("111.zip"))); ZipEntry entry; while ((entry =
- 70. Логирование Логирование — это механизм протоколирования различной информации о событиях, происходящих в процессе выполнения программы. Логирование
- 71. Пакет java.util.logging Пакет java.util.logging предоставляет классы и интерфейсы JavaTM 2 для реализации логирования. Ключевые элементы этого
- 72. Библиотека log4j Библиотека логирования log4j — это проект корпорации Apache Software Foundation. Основные компоненты библиотеки: Logger
- 74. Скачать презентацию

Понятие потоков ввода/вывода
Потоком ввода/вывода (I/O Stream) называется произвольный источник или приемник,
Понятие потоков ввода/вывода
Потоком ввода/вывода (I/O Stream) называется произвольный источник или приемник,

Системы ввода/вывода Java
Основная система ввода/вывода Java представлена пакетом java.io
Пакет java.nio содержит
Системы ввода/вывода Java
Основная система ввода/вывода Java представлена пакетом java.io
Пакет java.nio содержит

Виды потоков ввода/вывода
Всего существует 2 вида потоков ввода/вывода:
- байтовые
- символьные
Байтовые потоки
Виды потоков ввода/вывода
Всего существует 2 вида потоков ввода/вывода:
- байтовые
- символьные
Байтовые потоки

Суперклассы java.io API
Все потоки ядра Java (стандартного API) –
Все потоки ядра Java (стандартного API) –

Парные потоки
Предназначение каждого класса-потока заключается в том, чтобы передать или
Парные потоки
Предназначение каждого класса-потока заключается в том, чтобы передать или



Класс InputStream
Абстрактный класс InputStream предоставляет минимальный набор методов для работы с
Класс InputStream
Абстрактный класс InputStream предоставляет минимальный набор методов для работы с

Потомки класса InputStream
ObjectInputStream - поток объектов. Создается при сохранении объектов системными
Потомки класса InputStream
ObjectInputStream - поток объектов. Создается при сохранении объектов системными

Классы надстройки
Классы
FilterInputStream, FilterOutputStream;
FilterReader, FilterWriter
являются, соответственно, классами надстройками над классами
InputStream, OutputStream;
Reader
Классы надстройки
Классы
FilterInputStream, FilterOutputStream;
FilterReader, FilterWriter
являются, соответственно, классами надстройками над классами
InputStream, OutputStream;
Reader

Классы надстройки
Основное предназначение надстроек - наделение существующего потока новыми свойствами.
Комбинируя исходный
Основное предназначение надстроек - наделение существующего потока новыми свойствами.
Комбинируя исходный

Надстраивание (декорация)
В отличие от наследования надстраивание не ведет к появлению большого
Надстраивание (декорация)
В отличие от наследования надстраивание не ведет к появлению большого

Класс DataInputStream
Класс DataInputStream наследует класс надстройку FilterInputStream и позволяет читать
Класс DataInputStream
Класс DataInputStream наследует класс надстройку FilterInputStream и позволяет читать

Буферизация
Для ускорения файловых операций чтения/записи следует использовать буферизированные классы: BufferedInputStream и
Буферизация
Для ускорения файловых операций чтения/записи следует использовать буферизированные классы: BufferedInputStream и

Класс BufferedInputStream
Класс BufferedInputStream наследует класс надстройку FiltertInputStream.
Объект этого класса надстраивает входной
Класс BufferedInputStream
Класс BufferedInputStream наследует класс надстройку FiltertInputStream.
Объект этого класса надстраивает входной

Класс PushbackInputStream
Класс PushbackInputStream надстраивает входной байтовый поток и позволяет кроме
Класс PushbackInputStream
Класс PushbackInputStream надстраивает входной байтовый поток и позволяет кроме

Поле in класса System
Статическое поле in класса System имеет тип InputStream
Поле in класса System
Статическое поле in класса System имеет тип InputStream

Класс OutputStream
Абстрактный класс OutputStream предоставляет минимальный набор методов для работы с
Класс OutputStream
Абстрактный класс OutputStream предоставляет минимальный набор методов для работы с

Потомки класса OutputStream
ObjectOutputStream - поток двоичных представлений объектов. Создается при сериализации
ByteArrayOutputStream
Потомки класса OutputStream
ObjectOutputStream - поток двоичных представлений объектов. Создается при сериализации
ByteArrayOutputStream

Надстройки для OutputStream
Надстройками для OuptupStream являются наследники абстрактного класса FilterOutputStream
PrintStream –
Надстройки для OutputStream
Надстройками для OuptupStream являются наследники абстрактного класса FilterOutputStream
PrintStream –
![Буферизированный ввод/вывод public class FileCopy { public static void main(String[]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/92171/slide-21.jpg)
Буферизированный ввод/вывод
public class FileCopy {
public static void main(String[] args) {
try
Буферизированный ввод/вывод
public class FileCopy {
public static void main(String[] args) {
try

Символьные потоки
Для работы с символьными потоками в Java существуют два базовых
Символьные потоки
Для работы с символьными потоками в Java существуют два базовых

Некоторые потомки класса Writer
BufferedWriter - буферизированный выводной поток. Размер буфера можно
Некоторые потомки класса Writer
BufferedWriter - буферизированный выводной поток. Размер буфера можно

Потомки класса Reader
BufferedReader - буферизированный вводной поток символов
CharArrayReader - позволяет читать
Потомки класса Reader
BufferedReader - буферизированный вводной поток символов
CharArrayReader - позволяет читать

Пример программы
Вводить строки с клавиатуры и записывать их в файл
Пример программы
Вводить строки с клавиатуры и записывать их в файл

Класс OutputStreamWriter
Класс OutputStreamWriter наследуется от класса Writer, и преобразует выходной символьный
Класс OutputStreamWriter
Класс OutputStreamWriter наследуется от класса Writer, и преобразует выходной символьный

Кодировка по умолчанию
При запуске программы кодировку по умолчанию устанавливает JVM
Кодировка по умолчанию
При запуске программы кодировку по умолчанию устанавливает JVM

Указание кодировки при компиляции
Для правильного отображения строковых литералов, записанных в программе,
Указание кодировки при компиляции
Для правильного отображения строковых литералов, записанных в программе,

Перекодировка вывода
Все строковые литералы в байт коде классов содержаться в
Перекодировка вывода
Все строковые литералы в байт коде классов содержаться в

Перекодировка вывода
PrintWriter out = new PrintWriter(new
OutputStreamWriter(System.out, "Cp866"), true);
out.println(s); // вывод на
Перекодировка вывода
PrintWriter out = new PrintWriter(new
OutputStreamWriter(System.out, "Cp866"), true);
out.println(s); // вывод на

Поле out класса System
Статическое поле out класса System имеет тип
Поле out класса System
Статическое поле out класса System имеет тип

Класс RandomAccessFile
RandomAccessFile применяется для работы с файлами произвольного доступа
Для перемещения по
Класс RandomAccessFile
RandomAccessFile применяется для работы с файлами произвольного доступа
Для перемещения по

Пример работы с RandomAccessFile
Создать файл прямого доступа, выполнить запись в файл
Пример работы с RandomAccessFile
Создать файл прямого доступа, выполнить запись в файл

Класс File
Класс File предназначен для работы с элементами файловой системы –
Класс File
Класс File предназначен для работы с элементами файловой системы –

Конструкторы класса File
File(String filePath), где filePath – имя файла на диске
File(String
Конструкторы класса File
File(String filePath), где filePath – имя файла на диске
File(String

Каталоги
Каталог – это особый файл, который содержит в себе список других
Каталоги
Каталог – это особый файл, который содержит в себе список других

Фильтры (интерфейс FileFilter)
Интерфейс FileFilter применяется для проверки, подпадает ли объект File
Фильтры (интерфейс FileFilter)
Интерфейс FileFilter применяется для проверки, подпадает ли объект File

Пример работы с фильтрами
Выбрать из текущего каталога лишь те файлы, которые
Пример работы с фильтрами
Выбрать из текущего каталога лишь те файлы, которые

Новый ввод/вывод
Ее цель – увеличение производительности и обеспечения безопасности при одновременном
Новый ввод/вывод
Ее цель – увеличение производительности и обеспечения безопасности при одновременном

Буфер
Буфер представляет собой контейнер для данных простых типов, таких как byte,
Буфер
Буфер представляет собой контейнер для данных простых типов, таких как byte,

Методы класса Buffer
clear() – подготавливает буфер для операции записи в него
Методы класса Buffer
clear() – подготавливает буфер для операции записи в него

Байтовый буфер (ByteBuffer)
Байтовый буфер предназначен для работы с байтовыми данными
Создать буфер
Байтовый буфер (ByteBuffer)
Байтовый буфер предназначен для работы с байтовыми данными
Создать буфер

Прямые и непрямые буферы
ByteBuffer может быть прямым и непрямым
При работе с
Прямые и непрямые буферы
ByteBuffer может быть прямым и непрямым
При работе с

Чтение-запись данных в буфер
Для относительного получения байта данных из буфера используется
Чтение-запись данных в буфер
Для относительного получения байта данных из буфера используется

Буферы-представления
При необходимости работать с однотипными данными лучше использовать классы-представления
CharBuffer
DoubleBuffer
FloatBuffer
IntBuffer
LongBuffer
ShortBuffer
Для создания этиx
Буферы-представления
При необходимости работать с однотипными данными лучше использовать классы-представления
CharBuffer
DoubleBuffer
FloatBuffer
IntBuffer
LongBuffer
ShortBuffer
Для создания этиx

Пример работы с буфером-представлением
public class IntBufferDemo {
private static final
Пример работы с буфером-представлением
public class IntBufferDemo {
private static final

Файловый канал
Канал представляет собой открытое соединение к некоторой сущности, такой как,
Файловый канал
Канал представляет собой открытое соединение к некоторой сущности, такой как,

Работа с FileChannel
Файловый канал имеет свою позицию, которая устанавливается методом position(long)
Методы
Работа с FileChannel
Файловый канал имеет свою позицию, которая устанавливается методом position(long)
Методы

Пример работы с FileChannel
public class GetChannel {
private static final int
Пример работы с FileChannel
public class GetChannel {
private static final int

Копирование файлов
с использованием FileChannel
public class ChannelCopy {
private static final
Копирование файлов
с использованием FileChannel
public class ChannelCopy {
private static final

Более эффективный
способ копирования файлов
public class TransferTo {
public static void
Более эффективный
способ копирования файлов
public class TransferTo {
public static void

Блокировка файлов
Блокировка файлов осуществляется с помощью методов
FileLock lock(…)
FileLock tryLock(…)
Метод tryLock()
Блокировка файлов
Блокировка файлов осуществляется с помощью методов
FileLock lock(…)
FileLock tryLock(…)
Метод tryLock()

Пример блокировки файла
Механизм блокировки Java напрямую связан со средствами операционной системы
public
Пример блокировки файла
Механизм блокировки Java напрямую связан со средствами операционной системы
public

Файлы, отображаемые в памяти
Механизм отображения файлов в память позволяет вам создавать
Файлы, отображаемые в памяти
Механизм отображения файлов в память позволяет вам создавать
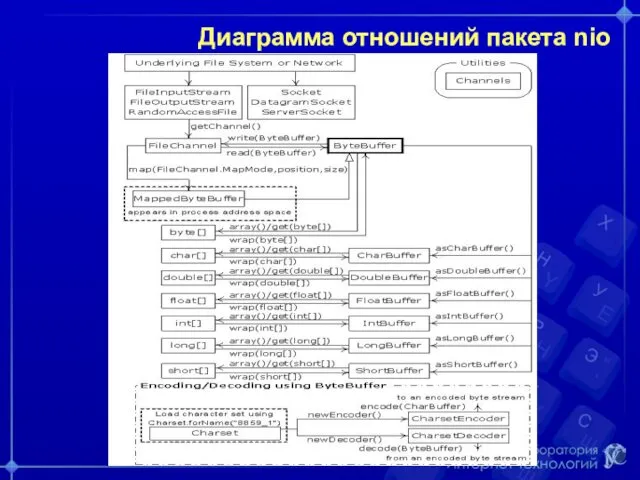
Диаграмма отношений пакета nio
Диаграмма отношений пакета nio

Сериализация
Сериализация позволяет превратить объект в поток байтов, чтобы, когда понадобится, полностью
Сериализация
Сериализация позволяет превратить объект в поток байтов, чтобы, когда понадобится, полностью

Интерфейс Serializable
Чтобы обладать способностью к сериализации, класс должен:
Реализовать интерфейс-метку Serializable
Интерфейс Serializable
Интерфейс Serializable
Чтобы обладать способностью к сериализации, класс должен:
Реализовать интерфейс-метку Serializable
Интерфейс Serializable

Запись-чтение объектов
Сериализованные объекты можно записывать и считывать при помощи классов ObjectOutputStream
Запись-чтение объектов
Сериализованные объекты можно записывать и считывать при помощи классов ObjectOutputStream

Пример сериализации объектов
public class Point implements java.io.Serializable {
private int x=0,
Пример сериализации объектов
public class Point implements java.io.Serializable {
private int x=0,

Сериализация наследников несериализуемого класса
Если необходимо, чтобы подкласс несериализумого класса мог быть
Сериализация наследников несериализуемого класса
Если необходимо, чтобы подкласс несериализумого класса мог быть

Пример
Если суперкласс сериализуем:
public class Point implements Serializable{
public int x =
Пример
Если суперкласс сериализуем:
public class Point implements Serializable{
public int x =

Пример 2
Если суперкласс несериализуем:
public class Point {
public int x =
Пример 2
Если суперкласс несериализуем:
public class Point {
public int x =

Управление процессом сериализации
Для выполнения специальной обработки при сериализации и десериализации класс
Управление процессом сериализации
Для выполнения специальной обработки при сериализации и десериализации класс

Пример
public class PointXYZ extends Point implements Serializable{
private int z = 0;
…
private
Пример
public class PointXYZ extends Point implements Serializable{
private int z = 0;
…
private

Архивирование
Библиотека ввода/вывода Java содержит классы, поддерживающие чтение и запись потоков в
Архивирование
Библиотека ввода/вывода Java содержит классы, поддерживающие чтение и запись потоков в

Классы для работы с архивами
DeflaterOutputStream – базовый класс для классов компрессии
InflaterInputStream
Классы для работы с архивами
DeflaterOutputStream – базовый класс для классов компрессии
InflaterInputStream

Работа с ZipOutputSream
ZipOutputStream out = new ZipOutputStream(new FileOutputStream(“archive.zip”));
pack("111.txt", out);
pack(“222.txt", out);
out.close();
//
Работа с ZipOutputSream
ZipOutputStream out = new ZipOutputStream(new FileOutputStream(“archive.zip”));
pack("111.txt", out);
pack(“222.txt", out);
out.close();
//

Работа с ZipInputStream
ZipInputStream in = new ZipInputStream(new BufferedInputStream(
new FileInputStream("111.zip")));
ZipEntry entry;
while
Работа с ZipInputStream
ZipInputStream in = new ZipInputStream(new BufferedInputStream(
new FileInputStream("111.zip")));
ZipEntry entry;
while

Логирование
Логирование — это механизм протоколирования различной информации о событиях, происходящих в
Логирование
Логирование — это механизм протоколирования различной информации о событиях, происходящих в

Пакет java.util.logging
Пакет java.util.logging предоставляет классы и интерфейсы JavaTM 2 для реализации
Пакет java.util.logging
Пакет java.util.logging предоставляет классы и интерфейсы JavaTM 2 для реализации

Библиотека log4j
Библиотека логирования log4j — это проект корпорации Apache Software Foundation.
Основные
Библиотека log4j
Библиотека логирования log4j — это проект корпорации Apache Software Foundation.
Основные
 Introduction To ArcCatalog
Introduction To ArcCatalog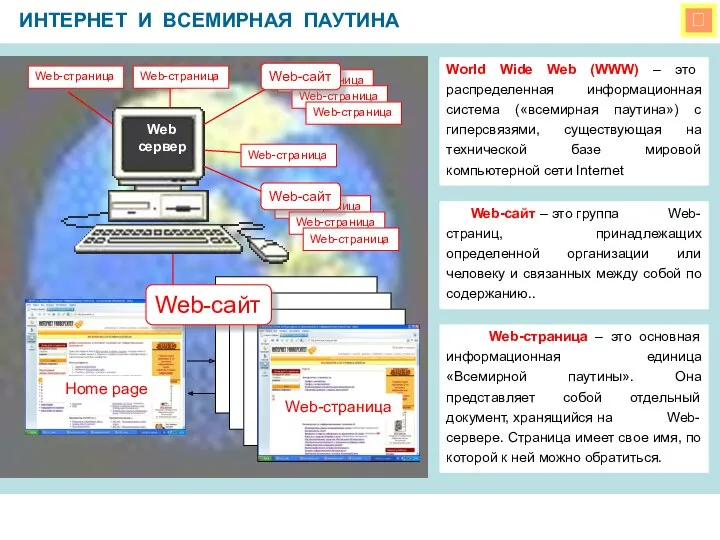 Всемирная паутина.
Всемирная паутина. Объекты и множества. Объекты изучения в информатике. Признаки объектов
Объекты и множества. Объекты изучения в информатике. Признаки объектов Работа с интерактивной доской StarBoard
Работа с интерактивной доской StarBoard Основні концепції реляційної бази даних
Основні концепції реляційної бази даних Урок ИКТ Системы счисления
Урок ИКТ Системы счисления Проектирование информационной образовательной среды
Проектирование информационной образовательной среды Эволюция операционных систем
Эволюция операционных систем Something about С++
Something about С++ Представление об организации баз данных и системах управления ими. Структура данных и система запросов
Представление об организации баз данных и системах управления ими. Структура данных и система запросов OOO Стандарт-групп. Автоматизация в сфере жилищно-коммунального хозяйства
OOO Стандарт-групп. Автоматизация в сфере жилищно-коммунального хозяйства Data Mining
Data Mining Арифметические и логические основы работы компьютера
Арифметические и логические основы работы компьютера Сетевой этикет
Сетевой этикет Кунделик. Единая образовательная сеть
Кунделик. Единая образовательная сеть Базы данных
Базы данных Сучасні веб-технології
Сучасні веб-технології Обработка информации
Обработка информации Архитектура ОС MS Windows 2000+. Реестр
Архитектура ОС MS Windows 2000+. Реестр Анализ современных подходов к разработке мобильных приложений на примере приложения: Дневник стрелка
Анализ современных подходов к разработке мобильных приложений на примере приложения: Дневник стрелка Programming language
Programming language Хранение информации 10 класс
Хранение информации 10 класс Организация разработки стратегии муниципального развития
Организация разработки стратегии муниципального развития База данных
База данных Устройство компьютера. Урок — КВН 8 класс
Устройство компьютера. Урок — КВН 8 класс Перспективное пользовательское программное обеспечение
Перспективное пользовательское программное обеспечение Платформа Ардуино
Платформа Ардуино Интерфейс Power Point 2010. Компонент Лента.
Интерфейс Power Point 2010. Компонент Лента.