- Распределённые вычисления. Многопотоковое программирование MPI

Содержание
- 2. for (i = 0; i for (i = 0; i C[i:i+3] означает вектор из 4 элементов
- 3. 1997 – MMX (Pentium MMX) 8 байт, целочисленные операции 1998 – 3DNow! (K6-2) 8 байт, float
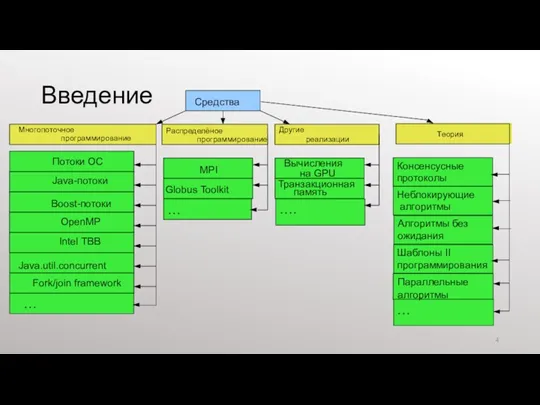
- 4. …. Введение Fork/join framework Теория Консенсусные протоколы Неблокирующие алгоритмы Алгоритмы без ожидания Шаблоны II программирования …
- 5. CUDA (Compute Unified Device Architecture) OpenCL (Open Computing Language) OpenGL(графика) OpenAL (звук) GPU — Graphical Processing
- 6. Программная модель CUDA Модель SIMD вычислений. Потоки объединяются в блоки потоков (thread block) — одно-, двух-
- 7. Транзакционная память (transactional memory) для многопоточного программирования в ней реализован механизм управления параллельными процессами для обеспечения
- 8. Транзакционная память (transactional memory -TM) Транзакция (Atomicity, Consistency, Isolation, Durability –принципы ASID): Неделимость — транзакция представляет
- 9. Консенсусные протоколы Консенсус – совместное однократное принятие общего решения N потоками из предложенных. Есть сеть: с
- 10. Блокчейн (blockchain) — это распределенная база данных, которая содержит информацию обо всех транзакциях, проведенных участниками системы.
- 11. Транзакционная память (transactional memory -TM) Основа – два сложно реализуемых механизма: управление версиями данных (data versioning)
- 12. Неблокирующие алгоритмы Формальное определение lock-free объекта звучит так: разделяемый объект называется lock-free объектом (неблокируемым, non-blocking объектом),
- 13. Неблокирующие алгоритмы Неблокирующая синхронизация — подход в параллельном программировании, в котором отходят от традиционных примитивов блокировки,
- 14. Шаблоны параллельного программирования (pattern) Cуществует огромное количество структур организации параллельных программ Наиболее часто встречающихся схем :
- 15. Шаблоны параллельного программирования (pattern) Как организован параллельный алгоритм? Тип алгоритма? Какой шаблон параллельного алгоритма выбрать?
- 16. Последовательные вычисления processor Расчет ЗП Число часов Квалификация ЕСН вычет Подоходный налог t1 t2 t3 t4
- 17. Параллельные вычисления processor Расчет ЗП работник 1 Instruction 1 processor processor processor Instruction 2 Instruction 3
- 18. Параллельные вычисления — это одновременное использование нескольких вычислений для решения вычислительной задачи: Задача разбита на отдельные
- 19. Ускорение (Speedup)
- 20. Процессоры нетрадиционной архитектуры Transputer - инновационный микропроцессор 1980-х годов со встроенной памятью, аппаратным планировщиком и 4-мя
- 21. Thread-level parallelism (TLP) Многопоточность — это способность центрального процессора (ЦП) (или одного ядра в многоядерном процессоре)
- 22. Процессоры нетрадиционной архитектуры Примеры топологий Почему необходимо использовать разные топологии параллельной передачи данных? Топология должна соответствовать
- 23. Процессоры нетрадиционной архитектуры Высокая стоимость первых параллельных систем: процессоры нетрадиционной архитектуры специальные языки программирования Например: Transputer
- 24. Параллельные компьютеры Современные принципы построения параллельных систем: Стандартное оборудование (традиционная архитектура) Параллельные компьютеры могут быть построены
- 25. Параллельные вычисления For example: OpenMP (Open Multi-Processing) - C, C++ and Fortran http://openmp.org (Symmetric Malty Processor)
- 26. Параллельные компьютеры 1. Все компьютеры сегодня параллельны по аппаратному обеспечению, т.к. содержат: несколько исполнительных блоков/ядер -
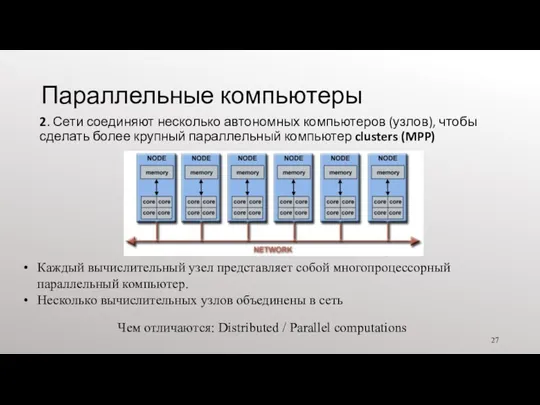
- 27. Параллельные компьютеры 2. Сети соединяют несколько автономных компьютеров (узлов), чтобы сделать более крупный параллельный компьютер clusters
- 28. Параллельные компьютеры Example: modern supercomputer All components are placed next to each other. network is superfast
- 29. введение Что такое параллельные вычисления?
- 30. Зачем использовать параллельные вычисления? Почему у нас есть ограничения для последовательных вычислений? Какие причины создают существенные
- 31. Зачем использовать параллельные вычисления? Ограничения для последовательных вычислений. А) Физические причины: Скорость передачи (Baud rate) сигнала:
- 32. Зачем использовать параллельные вычисления? Б) Экономические ограничения: Все дороже сделать один сверхбыстрый процессор. Производство нескольких более
- 33. ВВЕДЕНИЕ Где используются параллельные вычисления? примеры
- 34. Зачем использовать параллельные вычисления? Основные причины: 1. Реальный мир массивно параллелен: Параллельные вычисления гораздо лучше подходят
- 35. Зачем использовать параллельные вычисления? 2. Экономия времени и/или денег: - Сокращение времени выполнения задачи с потенциальной
- 36. Зачем использовать параллельные вычисления? 3. Решение больших сложных проблемм: Многие задачи настолько велики и/или сложны, что
- 37. Why Use Parallel Computing? For reference only:
- 38. Зачем использовать параллельные вычисления? 4. Поддержка параллельного взаимодействия: Например: совместные сети обеспечивают глобальное общее место, где
- 39. Зачем использовать параллельные вычисления? 5. Совместное использование использование вычислительных ресурсов в глобальной сети. Example 1: SETI@home
- 40. Зачем использовать параллельные вычисления? Совместное использование использование вычислительных ресурсов в глобальной сети. Example 2: Folding@home (folding.stanford.edu)
- 41. Введение Области использлвания параллельных вычислений?
- 42. Кто использует параллельные вычисления? Наука и техника
- 43. Кто использует параллельные вычисления? Промышленность и коммерция - движущие силы в развитии более быстрых компьютеров:
- 44. Пример: аэродинамическая труба (Wind tunnel)
- 45. Аэродинамическая труба(Wind tunnel) Т-104, ЦАГИ Скорость потока - 10–120 м/с Диаметр сопла- 7 м Длина рабочей
- 46. Supercomputer СКИФ МГУ Аэродинамическая труба числовая Пиковая производительность - 60 TFlop/s (1012) До ноября 2011 года
- 47. Кто использует параллельные вычисления? Области применения
- 48. Кто использует параллельные вычисления?
- 49. Понятия и терминология
- 50. Архитектура фон Неймана Венгерский математик/гений Джон фон Нейман около 1940-х (Источник: архивы LANL) С 1945 года
- 51. Архитектура фон Неймана - Четыре основных компонента: память, блок управления, арифметико-логическое устройство, ввод/вывод. - Оперативная память
- 52. Классификация Флинна (Flynn's Classical Taxonomy) Таксономия Флинна — широко используемая классификация с 1966 года. Таксономия Флинна
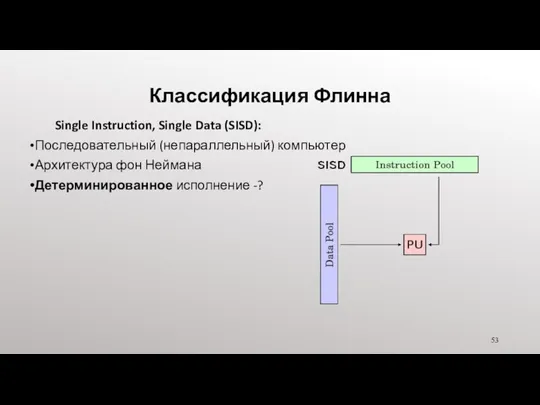
- 53. Классификация Флинна Single Instruction, Single Data (SISD): Последовательный (непараллельный) компьютер Архитектура фон Неймана Детерминированное исполнение -?
- 54. Детерминизм Детерминированные компьютерные программы всегда будет давать один и тот же результат с одним и тем
- 55. Классификация Флинна Single Instruction, Single Data (SISD): Это самый старый тип компьютера UNIVAC1 IBM 360 Dell
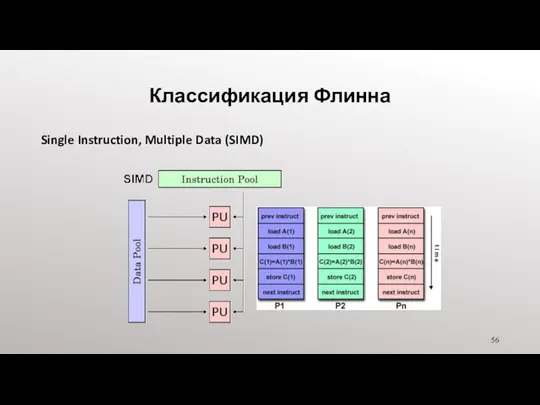
- 56. Классификация Флинна Single Instruction, Multiple Data (SIMD)
- 57. Flynn's Classical Taxonomy Single Instruction, Multiple Data (SIMD): Тип параллельного компьютера Используется для специализированных задач, характеризующихся
- 58. Классификация Флинна Single Instruction, Multiple Data (SIMD) –конвеерно - векторные суперкомпьютеры: MasPar Thinking Machines CM-2 Cray
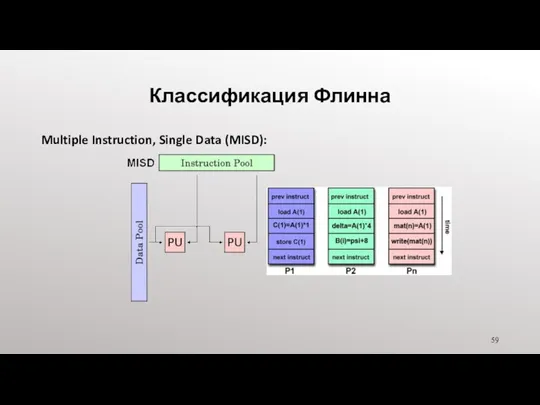
- 59. Классификация Флинна Multiple Instruction, Single Data (MISD):
- 60. Классификация Флинна Multiple Instruction, Single Data (MISD): Tтип параллельного компьютера Детерминированное исполнение Examples: Существовало мало (если
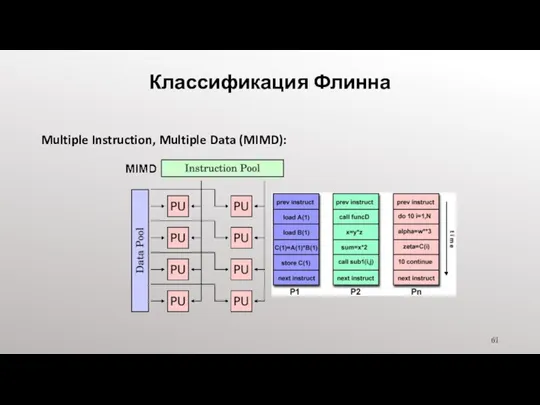
- 61. Классификация Флинна Multiple Instruction, Multiple Data (MIMD):
- 62. Классификация Флинна Multiple Instruction, Multiple Data (MIMD): Тип параллельного компьютера Выполнение может быть синхронным или асинхронным,
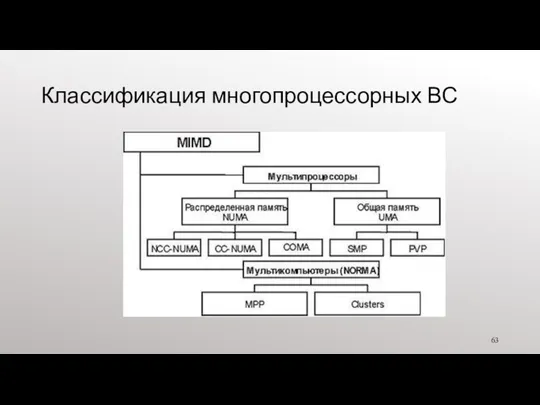
- 63. Классификация многопроцессорных ВС
- 65. Скачать презентацию

for (i = 0; i < 1024; i++) C[i] = A[i]
for (i = 0; i < 1024; i++) C[i] = A[i]

1997 – MMX (Pentium MMX)
8 байт, целочисленные операции
1998 –
1997 – MMX (Pentium MMX)
8 байт, целочисленные операции
1998 –
….
Введение
Fork/join framework
Теория
Консенсусные протоколы
Неблокирующие
алгоритмы
Алгоритмы без ожидания
Шаблоны II программирования
…
…
Параллельные алгоритмы
….
Введение
Fork/join framework
Теория
Консенсусные протоколы
Неблокирующие
алгоритмы
Алгоритмы без ожидания
Шаблоны II программирования
…
…
Параллельные алгоритмы
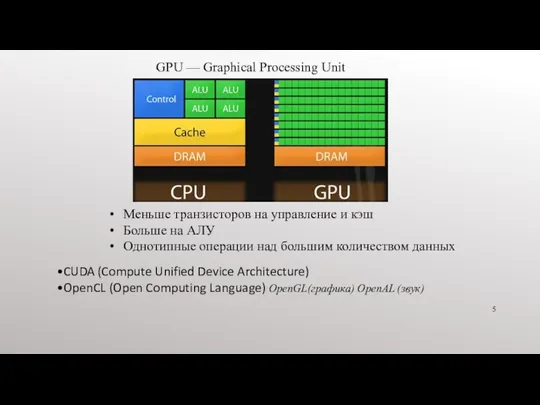
CUDA (Compute Unified Device Architecture)
OpenCL (Open Computing Language) OpenGL(графика) OpenAL (звук)
GPU — Graphical Processing Unit
Меньше
OpenCL (Open Computing Language) OpenGL(графика) OpenAL (звук)
GPU — Graphical Processing Unit
Меньше
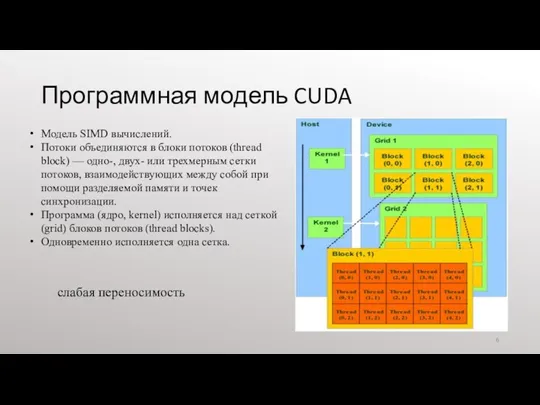
Программная модель CUDA
Модель SIMD вычислений.
Потоки объединяются в блоки потоков (thread block)
Программная модель CUDA
Модель SIMD вычислений.
Потоки объединяются в блоки потоков (thread block)

Транзакционная память (transactional memory) для многопоточного программирования
в ней реализован механизм управления
Транзакционная память (transactional memory) для многопоточного программирования
в ней реализован механизм управления

Транзакционная память (transactional memory -TM)
Транзакция (Atomicity, Consistency, Isolation, Durability –принципы ASID):
Неделимость —
Транзакционная память (transactional memory -TM)
Транзакция (Atomicity, Consistency, Isolation, Durability –принципы ASID):
Неделимость —

Консенсусные протоколы
Консенсус – совместное однократное принятие общего решения N потоками из
Консенсусные протоколы
Консенсус – совместное однократное принятие общего решения N потоками из

Блокчейн (blockchain) — это распределенная база данных, которая содержит информацию обо всех
Блокчейн (blockchain) — это распределенная база данных, которая содержит информацию обо всех

Транзакционная память (transactional memory -TM)
Основа – два сложно реализуемых механизма:
управление версиями
Транзакционная память (transactional memory -TM)
Основа – два сложно реализуемых механизма:
управление версиями

Неблокирующие алгоритмы
Формальное определение lock-free объекта звучит так: разделяемый объект называется lock-free
Неблокирующие алгоритмы
Формальное определение lock-free объекта звучит так: разделяемый объект называется lock-free

Неблокирующие алгоритмы
Неблокирующая синхронизация — подход в параллельном программировании, в котором отходят от
Неблокирующие алгоритмы
Неблокирующая синхронизация — подход в параллельном программировании, в котором отходят от

Шаблоны параллельного программирования (pattern)
Cуществует огромное количество структур организации параллельных программ
Наиболее часто
Шаблоны параллельного программирования (pattern)
Cуществует огромное количество структур организации параллельных программ
Наиболее часто

Шаблоны параллельного программирования (pattern)
Как организован параллельный алгоритм?
Тип алгоритма?
Какой шаблон параллельного алгоритма
Шаблоны параллельного программирования (pattern)
Как организован параллельный алгоритм?
Тип алгоритма?
Какой шаблон параллельного алгоритма
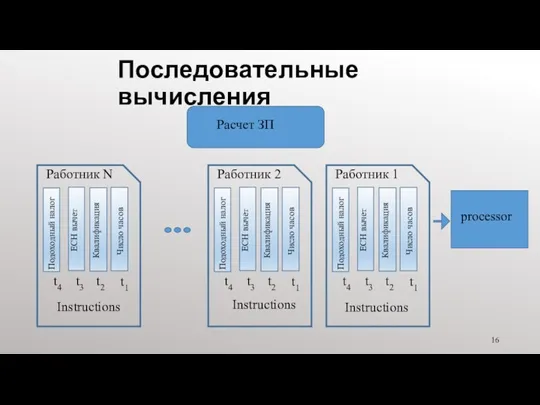
Последовательные вычисления
processor
Расчет ЗП
Число часов
Квалификация
ЕСН вычет
Подоходный налог
t1
t2
t3
t4
Работник N
Число часов
Квалификация
ЕСН вычет
Подоходный налог
t1
t2
t3
t4
Работник 1
Число
Последовательные вычисления
processor
Расчет ЗП
Число часов
Квалификация
ЕСН вычет
Подоходный налог
t1
t2
t3
t4
Работник N
Число часов
Квалификация
ЕСН вычет
Подоходный налог
t1
t2
t3
t4
Работник 1
Число
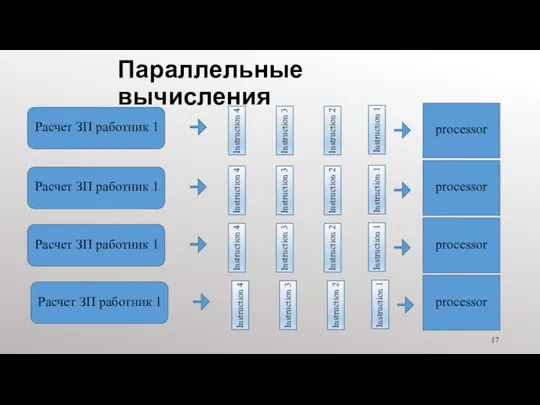
Параллельные вычисления
processor
Расчет ЗП работник 1
Instruction 1
processor
processor
processor
Instruction 2
Instruction 3
Instruction 4
Расчет ЗП работник
Параллельные вычисления
processor
Расчет ЗП работник 1
Instruction 1
processor
processor
processor
Instruction 2
Instruction 3
Instruction 4
Расчет ЗП работник

Параллельные вычисления — это одновременное использование нескольких вычислений для решения вычислительной
Параллельные вычисления — это одновременное использование нескольких вычислений для решения вычислительной
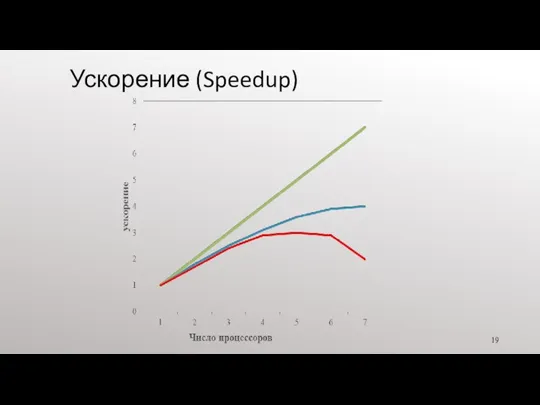
Ускорение (Speedup)
Ускорение (Speedup)
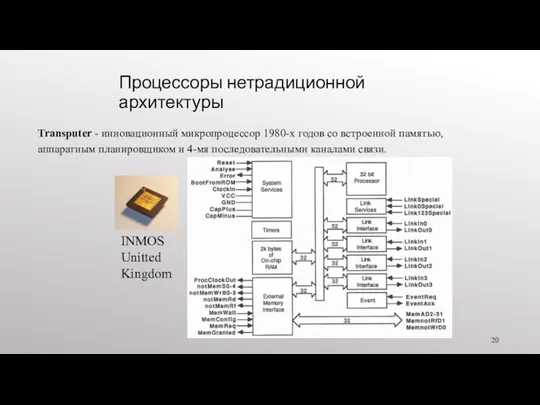
Процессоры нетрадиционной архитектуры
Transputer - инновационный микропроцессор 1980-х годов со встроенной памятью,
Процессоры нетрадиционной архитектуры
Transputer - инновационный микропроцессор 1980-х годов со встроенной памятью,
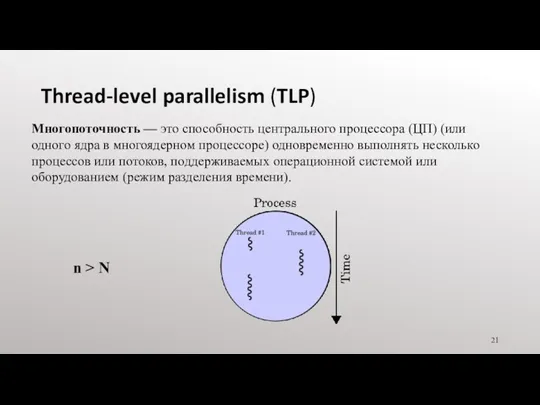
Thread-level parallelism (TLP)
Многопоточность — это способность центрального процессора (ЦП) (или одного ядра
Thread-level parallelism (TLP)
Многопоточность — это способность центрального процессора (ЦП) (или одного ядра

Процессоры нетрадиционной архитектуры
Примеры топологий
Почему необходимо использовать разные топологии параллельной передачи данных?
Топология
Процессоры нетрадиционной архитектуры
Примеры топологий
Почему необходимо использовать разные топологии параллельной передачи данных?
Топология

Процессоры нетрадиционной архитектуры
Высокая стоимость первых параллельных систем:
процессоры нетрадиционной архитектуры
специальные языки программирования
Например:
Процессоры нетрадиционной архитектуры
Высокая стоимость первых параллельных систем:
процессоры нетрадиционной архитектуры
специальные языки программирования
Например:

Параллельные компьютеры
Современные принципы построения параллельных систем:
Стандартное оборудование (традиционная архитектура) Параллельные компьютеры
Параллельные компьютеры
Современные принципы построения параллельных систем:
Стандартное оборудование (традиционная архитектура) Параллельные компьютеры

Параллельные вычисления
For example:
OpenMP (Open Multi-Processing) - C, C++ and Fortran http://openmp.org (Symmetric
Параллельные вычисления
For example:
OpenMP (Open Multi-Processing) - C, C++ and Fortran http://openmp.org (Symmetric

Параллельные компьютеры
1. Все компьютеры сегодня параллельны по аппаратному обеспечению, т.к. содержат:
несколько
Параллельные компьютеры
1. Все компьютеры сегодня параллельны по аппаратному обеспечению, т.к. содержат:
несколько
Параллельные компьютеры
2. Сети соединяют несколько автономных компьютеров (узлов), чтобы сделать более
Параллельные компьютеры
2. Сети соединяют несколько автономных компьютеров (узлов), чтобы сделать более

Параллельные компьютеры
Example: modern supercomputer
All components are placed next to each other.
Параллельные компьютеры
Example: modern supercomputer
All components are placed next to each other.

введение
Что такое параллельные вычисления?
введение
Что такое параллельные вычисления?

Зачем использовать параллельные вычисления?
Почему у нас есть ограничения для последовательных вычислений?
Какие
Зачем использовать параллельные вычисления?
Почему у нас есть ограничения для последовательных вычислений?
Какие

Зачем использовать параллельные вычисления?
Ограничения для последовательных вычислений.
А) Физические причины:
Скорость передачи (Baud
Зачем использовать параллельные вычисления?
Ограничения для последовательных вычислений.
А) Физические причины:
Скорость передачи (Baud

Зачем использовать параллельные вычисления?
Б) Экономические ограничения:
Все дороже сделать один сверхбыстрый процессор.
Производство
Зачем использовать параллельные вычисления?
Б) Экономические ограничения:
Все дороже сделать один сверхбыстрый процессор.
Производство

ВВЕДЕНИЕ
Где используются
параллельные вычисления?
примеры
ВВЕДЕНИЕ
Где используются
параллельные вычисления?
примеры

Зачем использовать параллельные вычисления?
Основные причины:
1. Реальный мир массивно параллелен:
Параллельные вычисления
Зачем использовать параллельные вычисления?
Основные причины:
1. Реальный мир массивно параллелен:
Параллельные вычисления

Зачем использовать параллельные вычисления?
2. Экономия времени и/или денег:
- Сокращение времени выполнения
Зачем использовать параллельные вычисления?
2. Экономия времени и/или денег:
- Сокращение времени выполнения

Зачем использовать параллельные вычисления?
3. Решение больших сложных проблемм:
Многие задачи настолько велики
Зачем использовать параллельные вычисления?
3. Решение больших сложных проблемм:
Многие задачи настолько велики

Why Use Parallel Computing?
For reference only:
Why Use Parallel Computing?
For reference only:

Зачем использовать параллельные вычисления?
4. Поддержка параллельного взаимодействия:
Например: совместные сети обеспечивают глобальное
Зачем использовать параллельные вычисления?
4. Поддержка параллельного взаимодействия:
Например: совместные сети обеспечивают глобальное
Зачем использовать параллельные вычисления?
5. Совместное использование использование вычислительных ресурсов в глобальной
Зачем использовать параллельные вычисления?
5. Совместное использование использование вычислительных ресурсов в глобальной

Зачем использовать параллельные вычисления?
Совместное использование использование вычислительных ресурсов в глобальной сети.
Example
Зачем использовать параллельные вычисления?
Совместное использование использование вычислительных ресурсов в глобальной сети.
Example

Введение
Области использлвания параллельных вычислений?
Введение
Области использлвания параллельных вычислений?

Кто использует параллельные вычисления?
Наука и техника
Кто использует параллельные вычисления?
Наука и техника

Кто использует параллельные вычисления?
Промышленность и коммерция - движущие силы в развитии
Кто использует параллельные вычисления?
Промышленность и коммерция - движущие силы в развитии

Пример: аэродинамическая труба (Wind tunnel)
Пример: аэродинамическая труба (Wind tunnel)

Аэродинамическая труба(Wind tunnel) Т-104, ЦАГИ
Скорость потока - 10–120 м/с
Диаметр сопла- 7
Аэродинамическая труба(Wind tunnel) Т-104, ЦАГИ
Скорость потока - 10–120 м/с
Диаметр сопла- 7

Supercomputer СКИФ МГУ
Аэродинамическая труба числовая
Пиковая производительность - 60 TFlop/s (1012)
До ноября
Supercomputer СКИФ МГУ
Аэродинамическая труба числовая
Пиковая производительность - 60 TFlop/s (1012)
До ноября

Кто использует параллельные вычисления?
Области применения
Кто использует параллельные вычисления?
Области применения
Кто использует параллельные вычисления?
Кто использует параллельные вычисления?

Понятия и терминология
Понятия и терминология

Архитектура фон Неймана
Венгерский математик/гений
Джон фон Нейман около 1940-х (Источник: архивы LANL)
С 1945
Архитектура фон Неймана
Венгерский математик/гений
Джон фон Нейман около 1940-х (Источник: архивы LANL)
С 1945

Архитектура фон Неймана
- Четыре основных компонента: память, блок управления, арифметико-логическое устройство,
Архитектура фон Неймана
- Четыре основных компонента: память, блок управления, арифметико-логическое устройство,

Классификация Флинна (Flynn's Classical Taxonomy)
Таксономия Флинна — широко используемая классификация с
Классификация Флинна (Flynn's Classical Taxonomy)
Таксономия Флинна — широко используемая классификация с
Классификация Флинна
Single Instruction, Single Data (SISD):
Последовательный (непараллельный) компьютер
Архитектура фон Неймана
Детерминированное
Классификация Флинна
Single Instruction, Single Data (SISD):
Последовательный (непараллельный) компьютер
Архитектура фон Неймана
Детерминированное

Детерминизм
Детерминированные компьютерные программы всегда будет давать один и тот же результат
Детерминизм
Детерминированные компьютерные программы всегда будет давать один и тот же результат

Классификация Флинна
Single Instruction, Single Data (SISD):
Это самый старый тип компьютера
UNIVAC1
IBM 360
Dell
Классификация Флинна
Single Instruction, Single Data (SISD):
Это самый старый тип компьютера
UNIVAC1
IBM 360
Dell
Классификация Флинна
Single Instruction, Multiple Data (SIMD)
Классификация Флинна
Single Instruction, Multiple Data (SIMD)

Flynn's Classical Taxonomy
Single Instruction, Multiple Data (SIMD):
Тип параллельного компьютера
Используется для
Flynn's Classical Taxonomy
Single Instruction, Multiple Data (SIMD):
Тип параллельного компьютера
Используется для

Классификация Флинна
Single Instruction, Multiple Data (SIMD) –конвеерно - векторные суперкомпьютеры:
MasPar
Thinking Machines
Классификация Флинна
Single Instruction, Multiple Data (SIMD) –конвеерно - векторные суперкомпьютеры:
MasPar
Thinking Machines
Классификация Флинна
Multiple Instruction, Single Data (MISD):
Классификация Флинна
Multiple Instruction, Single Data (MISD):

Классификация Флинна
Multiple Instruction, Single Data (MISD):
Tтип параллельного компьютера
Детерминированное исполнение
Examples:
Существовало мало (если
Классификация Флинна
Multiple Instruction, Single Data (MISD):
Tтип параллельного компьютера
Детерминированное исполнение
Examples:
Существовало мало (если
Классификация Флинна
Multiple Instruction, Multiple Data (MIMD):
Классификация Флинна
Multiple Instruction, Multiple Data (MIMD):

Классификация Флинна
Multiple Instruction, Multiple Data (MIMD):
Тип параллельного компьютера
Выполнение может быть синхронным
Классификация Флинна
Multiple Instruction, Multiple Data (MIMD):
Тип параллельного компьютера
Выполнение может быть синхронным
Классификация многопроцессорных ВС
Классификация многопроцессорных ВС
 Salome & Code_Aster достойная замена платным пакетам МКЭ
Salome & Code_Aster достойная замена платным пакетам МКЭ Основы научных исследований. Поиск научных статей и монографий в базе данных IEEE Xplore. Тема 5
Основы научных исследований. Поиск научных статей и монографий в базе данных IEEE Xplore. Тема 5 Презентация к уроку Модели. Моделирование
Презентация к уроку Модели. Моделирование Проектирование реляционной базы данных
Проектирование реляционной базы данных Management systems. Formation of queries, forms and reports. Working with graphics applications
Management systems. Formation of queries, forms and reports. Working with graphics applications Основные понятия языка. Лекция 2
Основные понятия языка. Лекция 2 Информационные технологии: общая характеристика
Информационные технологии: общая характеристика Интервью. Жанр или метод?
Интервью. Жанр или метод? Методы искусственного интеллекта в менеджменте
Методы искусственного интеллекта в менеджменте Одномерные массивы
Одномерные массивы Строки как одномерные массивы данных типа char (терминальные строки)
Строки как одномерные массивы данных типа char (терминальные строки) Земли промышленности, энергетики, транспорта, связи, радиовещания, телевидения, информатики
Земли промышленности, энергетики, транспорта, связи, радиовещания, телевидения, информатики Стильове оформлення абзаців. Розділи. Колонтитули. Структура документа. (Урок 13, 8 клас)
Стильове оформлення абзаців. Розділи. Колонтитули. Структура документа. (Урок 13, 8 клас) Презентация по теме Кодирование информации 3 класс
Презентация по теме Кодирование информации 3 класс Ассемблер Atmel AVR
Ассемблер Atmel AVR Элементы алгебры логики. Математические основы информатики. Информатика. 8 класс
Элементы алгебры логики. Математические основы информатики. Информатика. 8 класс Хранение, отбор и сортировка информации в базах данных. Лекция 19
Хранение, отбор и сортировка информации в базах данных. Лекция 19 Сравнительный анализ крупнейших IT компаний России
Сравнительный анализ крупнейших IT компаний России Основные алгоритмические структуры
Основные алгоритмические структуры Презентация Обработка информации
Презентация Обработка информации Объекты растровой графики и действия над ними. Фрагмент
Объекты растровой графики и действия над ними. Фрагмент Программирование. Введение
Программирование. Введение Управление и кибернетика. Алгоритм и его свойства. Алгоритмические структуры. Графический учебный исполнитель. Тест по информатике для 9 класса.
Управление и кибернетика. Алгоритм и его свойства. Алгоритмические структуры. Графический учебный исполнитель. Тест по информатике для 9 класса. Концептуальная модель uml
Концептуальная модель uml Сетевая адресация. Понятие IP-адреса и маски сети. Структура IP-адреса. Типы IP-адресов. Публичные и частные IP-адреса
Сетевая адресация. Понятие IP-адреса и маски сети. Структура IP-адреса. Типы IP-адресов. Публичные и частные IP-адреса Модем. Интернет желісі
Модем. Интернет желісі Язык программирования JavaScript
Язык программирования JavaScript Личный кабинет клиента my.ponyexpress.ru
Личный кабинет клиента my.ponyexpress.ru