Технологии распределенных вычислений. Распределенные базы данных. Технологии и модели клиент-сервер презентация
- Технологии распределенных вычислений. Распределенные базы данных. Технологии и модели клиент-сервер

Содержание
- 2. Учебные вопросы: 1.Технологии распределенных вычислений (РВ) 2.Распределенные базы данных 3.Технологии и модели "Клиент-сервер"
- 3. 1. Технологии распределенных вычислений (РВ)
- 4. Принцип централизованной обработки данных (рис. 5.1) не отвечал высоким требованиям к надежности процесса обработки, затруднял развитие
- 5. Появление персональных компьютеров потребовало нового подхода к организации систем обработки данных, к созданию новых информационных технологий.
- 6. Распределенная обработка данных - обработка данных, выполняемая на независимых, но связанных между собой компьютерах, представляющих распределенную
- 7. Дня реализации распределенной обработки данных были созданы многомашинные ассоциации, структура которых разрабатывается по одному из следующих
- 8. Многомашинный вычислительный комплекс - группа установленных рядом вычислительных машин, объединенных с помощью специальных средств сопряжения и
- 9. Компьютерная (вычислительная) сеть - вычислительная система, включающая в себя несколько компьютеров, терминалов и других аппаратных средств,
- 10. 2. Распределенные базы данных
- 11. Распределенная база данных - это совокупность логически взаимосвязанных баз данных, распределенных в компьютерной сети. Система управления
- 12. Основные принципы создания и функционирования распределенных баз данных: - прозрачность расположения данных для пользователя (иначе говоря,
- 13. - независимость от местоположения (пользователю все равно, где физически находятся данные, он работает так, как будто
- 14. 3. Технологии и модели "Клиент-сервер"
- 15. В технологиях "Клиент-сервер" отступают от одного из главных принципов создания и функционирования распределенных систем - отсутствия
- 16. Под сервером в широком смысле понимается любая система, процесс, компьютер, владеющие каким-либо вычислительным ресурсом (памятью, временем,
- 17. Рис 5.3 - Модель файлового сервера
- 18. Рис 5.4. Модель удаленного доступа к данным (RDA-модель)
- 19. Интероперабельность (многопротокольность) СУБД - способность СУБД обслуживать прикладные программы, первоначально ориентированные на разные типы СУБД. Иначе
- 20. Рис. 5.5 Модель сервера базы данных (DBS-модель)
- 21. Рис. 5.6. Модель сервера приложений (AS-модель)
- 22. Репликой называют особую копию базы данных для размещения на другом компьютере сети с целью автономной работы
- 23. При этом, однако, возникают две проблемы обеспечения одного из основополагающих принципов построения и функционирования распределенных систем
- 25. Скачать презентацию

Учебные вопросы:
1.Технологии распределенных вычислений (РВ)
2.Распределенные базы данных
3.Технологии и модели "Клиент-сервер"
Учебные вопросы:
1.Технологии распределенных вычислений (РВ)
2.Распределенные базы данных
3.Технологии и модели "Клиент-сервер"

1. Технологии распределенных вычислений (РВ)
1. Технологии распределенных вычислений (РВ)
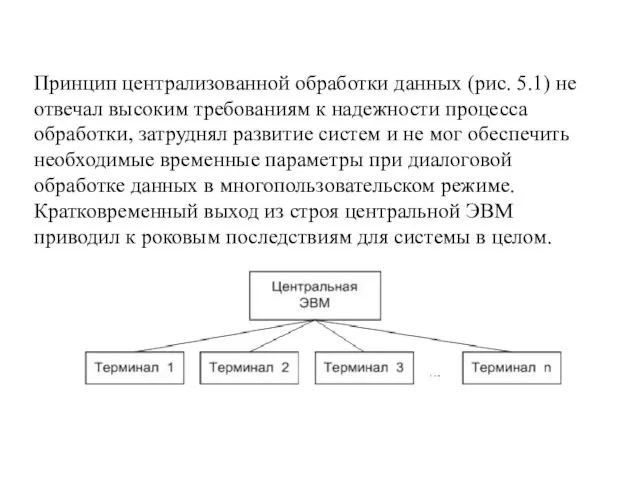
Принцип централизованной обработки данных (рис. 5.1) не отвечал высоким требованиям к
Принцип централизованной обработки данных (рис. 5.1) не отвечал высоким требованиям к
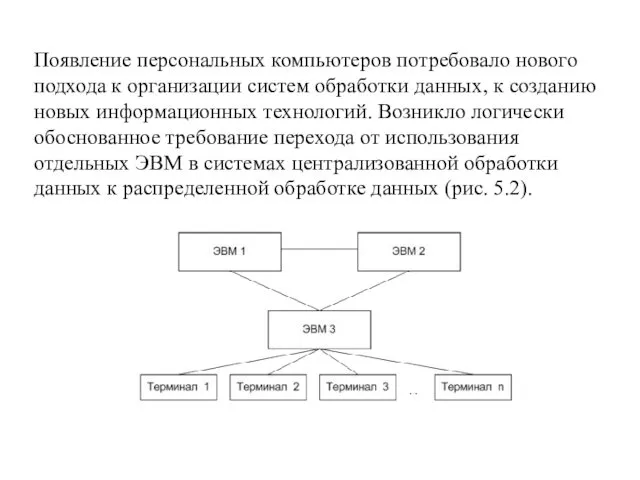
Появление персональных компьютеров потребовало нового подхода к организации систем обработки данных,
Появление персональных компьютеров потребовало нового подхода к организации систем обработки данных,

Распределенная обработка данных - обработка данных, выполняемая на независимых, но связанных
Распределенная обработка данных - обработка данных, выполняемая на независимых, но связанных

Дня реализации распределенной обработки данных были созданы многомашинные ассоциации, структура которых
Дня реализации распределенной обработки данных были созданы многомашинные ассоциации, структура которых

Многомашинный вычислительный комплекс - группа установленных рядом вычислительных машин, объединенных с
Многомашинный вычислительный комплекс - группа установленных рядом вычислительных машин, объединенных с

Компьютерная (вычислительная) сеть - вычислительная система, включающая в себя несколько компьютеров,
Компьютерная (вычислительная) сеть - вычислительная система, включающая в себя несколько компьютеров,

2. Распределенные базы данных
2. Распределенные базы данных

Распределенная база данных - это совокупность логически взаимосвязанных баз данных, распределенных
Распределенная база данных - это совокупность логически взаимосвязанных баз данных, распределенных

Основные принципы создания и функционирования распределенных баз данных:
- прозрачность расположения данных
Основные принципы создания и функционирования распределенных баз данных: - прозрачность расположения данных

- независимость от местоположения (пользователю все равно, где физически находятся данные,
- независимость от местоположения (пользователю все равно, где физически находятся данные,

3. Технологии и модели "Клиент-сервер"
3. Технологии и модели "Клиент-сервер"

В технологиях "Клиент-сервер" отступают от одного из главных принципов создания и
В технологиях "Клиент-сервер" отступают от одного из главных принципов создания и

Под сервером в широком смысле понимается любая система, процесс, компьютер, владеющие
Под сервером в широком смысле понимается любая система, процесс, компьютер, владеющие
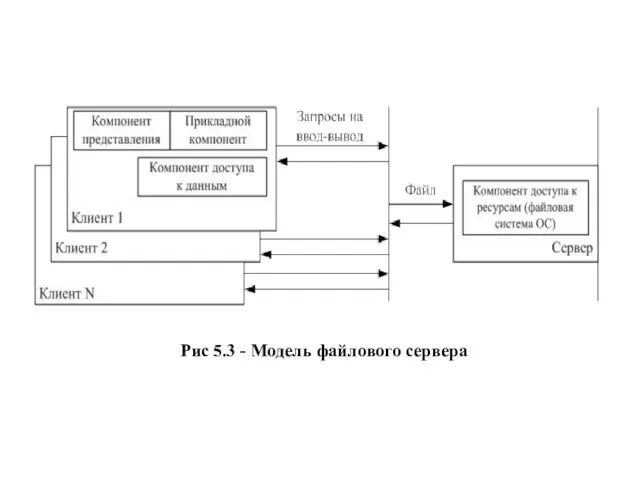
Рис 5.3 - Модель файлового сервера
Рис 5.3 - Модель файлового сервера
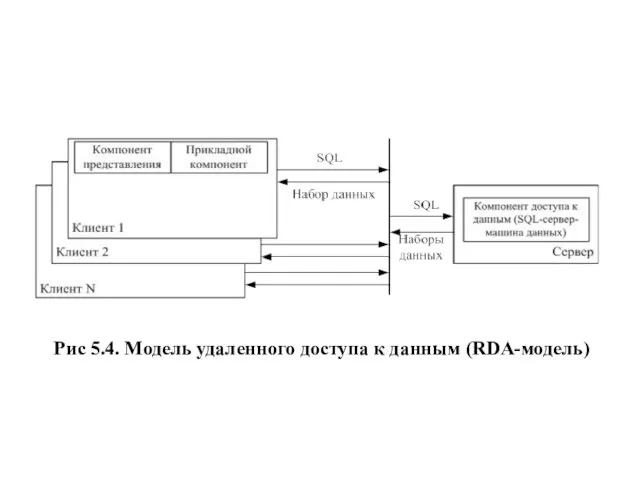
Рис 5.4. Модель удаленного доступа к данным (RDA-модель)
Рис 5.4. Модель удаленного доступа к данным (RDA-модель)

Интероперабельность (многопротокольность) СУБД - способность СУБД обслуживать прикладные программы, первоначально ориентированные
Интероперабельность (многопротокольность) СУБД - способность СУБД обслуживать прикладные программы, первоначально ориентированные
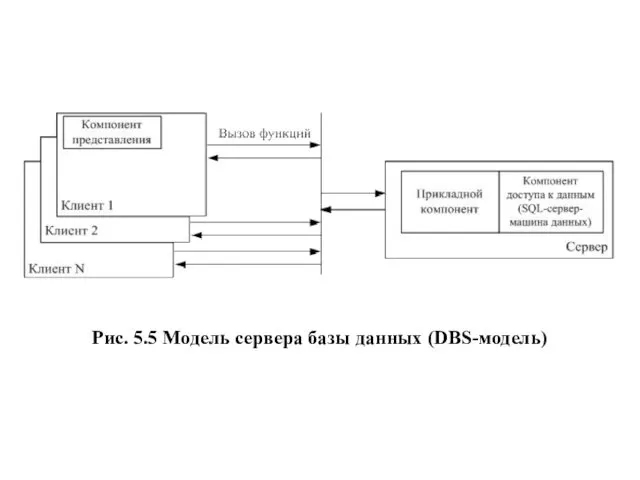
Рис. 5.5 Модель сервера базы данных (DBS-модель)
Рис. 5.5 Модель сервера базы данных (DBS-модель)
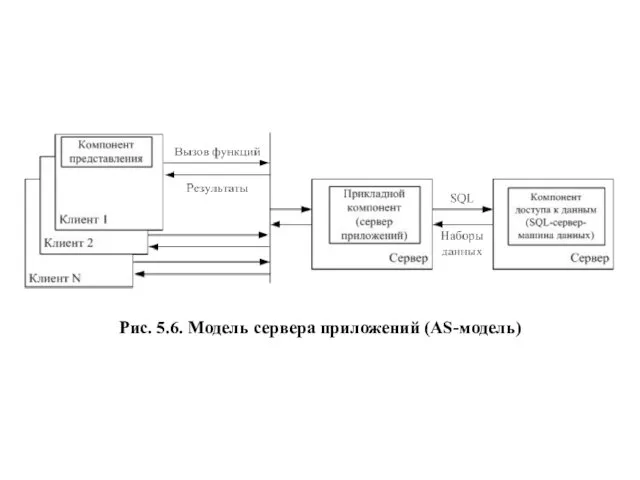
Рис. 5.6. Модель сервера приложений (AS-модель)
Рис. 5.6. Модель сервера приложений (AS-модель)

Репликой называют особую копию базы данных для размещения на другом компьютере
Репликой называют особую копию базы данных для размещения на другом компьютере

При этом, однако, возникают две проблемы обеспечения одного из основополагающих принципов
При этом, однако, возникают две проблемы обеспечения одного из основополагающих принципов
 История вычислительной техники
История вычислительной техники Курсовой проект: Проектирование локальной сети предприятия
Курсовой проект: Проектирование локальной сети предприятия Роль информатики и вычислительной техники в обществе. Информация и информационные процессы
Роль информатики и вычислительной техники в обществе. Информация и информационные процессы Масиви
Масиви Простой софт: учет посетителей
Простой софт: учет посетителей Топология локально-вычислительных сетей ФНС России. Настройка телекоммуникационного оборудования
Топология локально-вычислительных сетей ФНС России. Настройка телекоммуникационного оборудования Виконавці алгоритмів та їхні системи команд. 5 класс
Виконавці алгоритмів та їхні системи команд. 5 класс Huawei takes the lead in creating a converged ecosystem of partners to keep cities safe
Huawei takes the lead in creating a converged ecosystem of partners to keep cities safe Типология журналистики. Журналистика, как система средств массовой информации
Типология журналистики. Журналистика, как система средств массовой информации Издательство Лань. Электронно-библиотечная система
Издательство Лань. Электронно-библиотечная система Динамическое программирование
Динамическое программирование Графические информационные модели
Графические информационные модели Python. Структура программы. Переменные и присваивание. Ввод-вывод
Python. Структура программы. Переменные и присваивание. Ввод-вывод Инструкция Zoom (1)
Инструкция Zoom (1) HTML тілінің көмегімен web-парақтарды құру
HTML тілінің көмегімен web-парақтарды құру Поиск информации в интернете
Поиск информации в интернете Работа с одаренными детьми в области информационных технологий
Работа с одаренными детьми в области информационных технологий Игра как метод решения учебных проблем
Игра как метод решения учебных проблем Текстовые редакторы и текстовые процессоры
Текстовые редакторы и текстовые процессоры Данные. Типы данных
Данные. Типы данных Клавиатура компьютера. Основные приемы работы. Виды клавиш и их основное назначение
Клавиатура компьютера. Основные приемы работы. Виды клавиш и их основное назначение Тема 3. Ветвления. Массивы. Циклы
Тема 3. Ветвления. Массивы. Циклы Информатиканы оқытуда мұғалімнің рөлі
Информатиканы оқытуда мұғалімнің рөлі функция. Область действия (область видимости) идентификатора
функция. Область действия (область видимости) идентификатора Личное информационное пространство
Личное информационное пространство Графический онлайн редактор Canva. Как начать работу
Графический онлайн редактор Canva. Как начать работу Нормализация отношений
Нормализация отношений История развития информационных технологий
История развития информационных технологий