- Гармонизация статистических доказательств и предсказаний

Содержание
- 2. Обработка количественных данных Эпидемиологи смотрят на мир сквозь решетку таблицы 2×2. При этом надо помнить, что
- 3. Интерфероны и диагностика ЗВУР - задержки внутриутробного развития Королева Людмила Илларионовна, НИИ АГ им.Д.О.Отта
- 4. ЗВУР Термин задержка внутриутробного развития плода (ЗВУР) используется для описания плода, масса которого гораздо меньше ожидаемой
- 5. Содержание INF-α/β у 16 здоровых матерей здоровых детей и у 20 матерей доношенных новорожденных с ЗВУР
- 6. Гистограмма Гистограмма (от др.-греч. ἱστός — столб + γράμμα — черта, буква, написание) — столбиковая диаграмма
- 7. Сопоставление гистограмм содержания INF-α/β у здоровых матерей здоровых детей и матерей доношенных новорожденных с ЗВУР
- 8. Гистограммы содержания INF-α/β у здоровых матерей здоровых детей и матерей доношенных новорожденных с ЗВУР. Программа PAST
- 9. Нормальные вероятностные графики Здоровые ЗВУР
- 10. Проверка нормальности (гауссовости) распределения у матерей здоровых детей и детей с ЗВУР Практические все Р-значения превышают
- 11. Диаграммы «короб с усами» для данных об уровне индуцированной продукции IFN‑α/β у здоровых матерей здоровых детей
- 12. Исключение резко выделяющихся наблюдений С рекомендаций по отбрасыванию выскакивающих (экстремальных) наблюдений («выбросов», «засорений») начинаются многие руководства
- 13. Резко выделяющиеся значения – «выбросы» Выскакивающие значения можно и нужно выявлять. Но отбрасывать их следует на
- 14. Сжатие (свертка, редукция) статистических данных Статистика – любая функция от случайных величин, порождающих получаемые статистические данные.
- 15. Основная логика статистического оценивания: интервальные оценки Понятно, что если мы многократно повторим эксперимент, то вычисленные средние
- 16. Статистические гипотезы В обычном языке слово «гипотеза» означает предположение. В том же смысле оно употребляется и
- 17. Проверяемая гипотеза В подавляющем большинстве реальных ситуаций проверяемая статистическая гипотеза является гипотезой об отсутствии того или
- 18. Использование доверительных интервалов (ДИ) для проверки нулевых гипотез Например, для проверки нулевой гипотезы о равенстве двух
- 19. Визуализация результатов проверки статистических гипотез с помощью доверительных интервалов для размера эффекта
- 20. Графическое представление результатов статистического сравнения групп матерей здоровых детей и детей с ЗВУР, 1-α = 0,99.
- 21. Статистики критериев (тестовые статистики) Тестовая статистика – статистика, используемая для проверки конкретной статистической гипотезы. Пример: статистика
- 22. Проблема Беренса-Фишера Если дисперсии сравниваемых двух независимых случайных величин не равны, то, то следует использовать модификацию
- 23. Статистика Уэлча приближенно имеет t-распределение Стьюдента, но со степенью свободы νW, который задается выражением: где
- 24. Р-значение Для проверки нулевых гипотез с помощью статистических критериев основным приемом является вычисление значения вероятности, которое
- 25. P-значение есть вероятность наблюдать исход (x), плюс все «еще более экстремальные исходы». Они представлены затушеванной областью
- 26. Односторонние Р-значения
- 27. Двухстороннее Р-значение
- 28. Основная логика использования наблюдаемого значения величины P состоит в том, что если оно малó, то считается,
- 29. Выбор порога для значения P, и можно ли его обосновать? Когда наблюдаемое значение P мало, то
- 30. Традиционная интерпретация значений P (шкала Michelin)
- 31. Результаты статистического сравнение групп матерей здоровых детей и детей с ЗВУР, 1-α = 0,99. Программа ESCI
- 32. Акт интеллектуальной смелости Когда значение P очень мало, мы берем на себя смелость отклонить нулевую гипотезу
- 33. Распространенный соблазн Квинтэссенцию традиционных (частотнических) заключений при проверке статистических гипотез принято интерпретировать так: чем меньше значение
- 34. Распространенное заблуждение Значение P не есть вероятность нулевой гипотезы ! Поскольку P-значение вычисляется при условии, что
- 35. Р-значение потому столь привлекательно для ученых, что с ним очень легко получить «значимый» («достоверный») результат, даже
- 36. «Цена» значения P Для наглядности значения в таблице округлены до первой значащей цифры. Более точно значения
- 37. Бейзовская интерпретация значения P Обычно принято интерпретировать значения P как меру доказательства, предоставляемого имеющимися данными, против
- 38. Привычка свыше нам дана Это прекрасно понимал Р.А. Фишер: «Критерий значимости не позволяет нам делать какие-либо
- 39. Статистическая значимость и размер эффекта Эффект (различие, связь, риск, польза, ассоциация и т. п.) может быть
- 40. Размер эффекта Вопрос о клинической (практической) ценности (важности) наблюдаемого размера эффекта является ключевым при интерпретации результатов
- 41. Стандартизированный размер эффекта по Коуэну (Cohen) dC
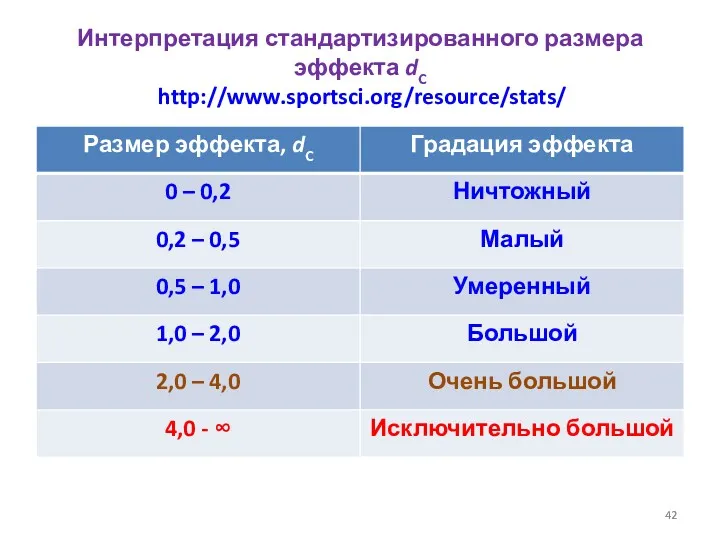
- 42. Интерпретация стандартизированного размера эффекта dC http://www.sportsci.org/resource/stats/
- 43. Результаты статистического сравнения групп матерей здоровых детей и детей с ЗВУР, (1 - α) = 0,99.
- 44. Непараметрическая оценка dC 95%-й ДИ: 0,81,72,5 99%-й ДИ: 0,61,72,6 99,9%-й ДИ: 0,31,72,8
- 45. Бейзов фактор, BF Бейзов фактор BF принципиально отличается от значения P. Бейзов фактор не является вероятностью
- 46. Интерпретация убедительности Бейзовых факторов, BF10 и BF01
- 47. Бейзов фактор, программа Bayes Factor Calculators http://pcl.missouri.edu/bayesfactor
- 48. Вывод результатов (output) В 5555 раз (1/0,00018) более правдоподобно получить наблюдаемое различие (ES = 52,1 у.е.)
- 49. Достаточно малое значение P заставляет думать, что произошло нечто неожиданное. И обычно это интерпретируется как неверность
- 50. Статистические предсказания и воспроизводимость
- 51. Значение вероятностной P-величины Значение P есть наблюдаемое значение (реализация) соответствующей случайной величины Всякий раз мы наблюдаем
- 52. Отсюда следует, что, строго говоря, на основе всего лишь одного изолированного исследования нельзя делать определенные выводы.
- 53. Доверяя, повторяй Часто считается, что если получен «статистически значимый» результат, то это исключает необходимость повторить исследование.
- 54. Воспроизводимость и предсказания абсолютного размера эффекта для групп матерей здоровых детей и детей с ЗВУР. Программа
- 55. Воспроизводимость и предсказания стандартизированного размера эффекта по Коуэну (Cohen) dC
- 56. Воспроизводимость и предсказания размеров эффекта ES и dC для групп матерей здоровых детей и детей с
- 57. Ошибки I и II рода и мощность статистического критерия
- 58. Истинный позитив, верна H0 Истинный негатив, верна H1 Ложный позитив, ошибка I рода, ложная тревога Ложный
- 59. Судебные ошибки
- 60. Диагностика Болезнь Тест
- 61. Теория Неймана-Пирсона: Ошибки I и II рода и мощность критерия Действи-тельность Критерий
- 62. Ошибки I и II рода Ошибка I рода: отклонение верной нулевой гипотезы; Аналитик решает (берет на
- 63. Ошибки I и II рода
- 64. Компромисс Например, в случае металлодетектора. H0 – обнаружен нейтральный предмет. повышение чувствительности прибора приведёт к увеличению
- 65. Мощность статистического критерия Мощность статистического критерия есть вероятность того, что критерий правильно отклонит ложную нулевую гипотезу
- 66. Мощность отвечает на вопрос: Если эффект (определенного размера) действительно существует, то какова вероятность того, что эксперимент
- 67. Анализ мощности a priori или post-hoc Анализ мощности можно проводить либо a priori, т.е. до получения
- 68. Оценка достигнутой мощности (post hoc). Программа G*Power http://www.psycho.uni-duesseldorf.de/aap/projects/gpower/ Достигнутая мощность проведенного исследования составила (1 – β)
- 69. Элементы планирования эксперимента
- 70. Программа G*Power http://www.psycho.uni-duesseldorf.de/abteilungen/aap/gpower3 Оценка a priori минимально необходимого объема выборки N для достижения статистически значимого отличия
- 71. Оценка необходимых объемов выборок (a priori) Для достижения приемлемой статистической мощности (1 – β) = 0,95
- 72. Научный метод Ни один уважающий себя ученый не ограничится в своих исследованиях одним-единственным экспериментом, хотя бы
- 73. Культ одиночного изолированного исследования Чрезмерное «увлечение» анализом одиночных наборов данных пронизывает почти всю статистическую литературу и
- 75. Скачать презентацию

Обработка количественных данных
Эпидемиологи смотрят на мир сквозь решетку таблицы 2×2. При
Обработка количественных данных
Эпидемиологи смотрят на мир сквозь решетку таблицы 2×2. При

Интерфероны и диагностика ЗВУР - задержки внутриутробного развития
Королева Людмила Илларионовна,
НИИ АГ
Интерфероны и диагностика ЗВУР - задержки внутриутробного развития
Королева Людмила Илларионовна,
НИИ АГ

ЗВУР
Термин задержка внутриутробного развития плода (ЗВУР) используется для описания плода, масса которого гораздо
ЗВУР
Термин задержка внутриутробного развития плода (ЗВУР) используется для описания плода, масса которого гораздо
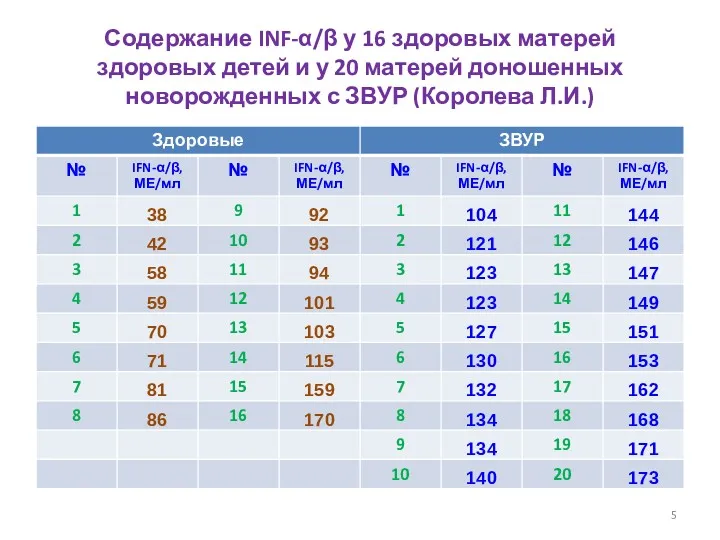
Содержание INF-α/β у 16 здоровых матерей здоровых детей и у 20
Содержание INF-α/β у 16 здоровых матерей здоровых детей и у 20

Гистограмма
Гистограмма
(от др.-греч. ἱστός — столб + γράμμα — черта, буква, написание)
— столбиковая диаграмма
— способ графического
Гистограмма
Гистограмма
(от др.-греч. ἱστός — столб + γράμμα — черта, буква, написание)
— столбиковая диаграмма
— способ графического
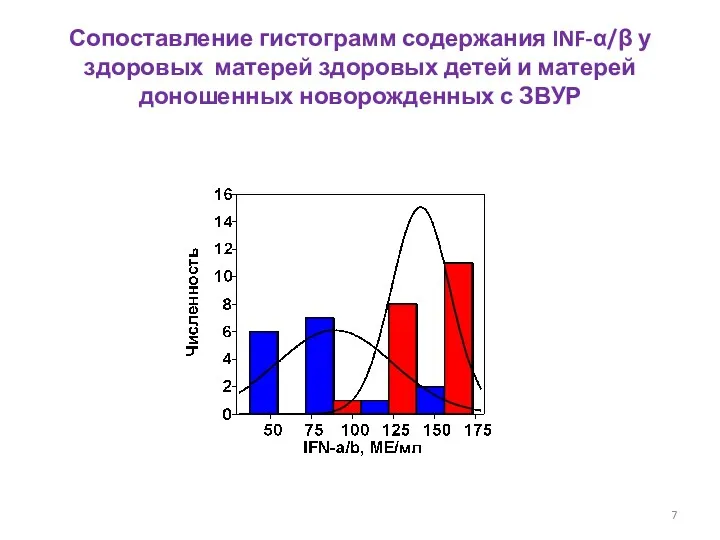
Сопоставление гистограмм содержания INF-α/β у здоровых матерей здоровых детей и матерей
Сопоставление гистограмм содержания INF-α/β у здоровых матерей здоровых детей и матерей
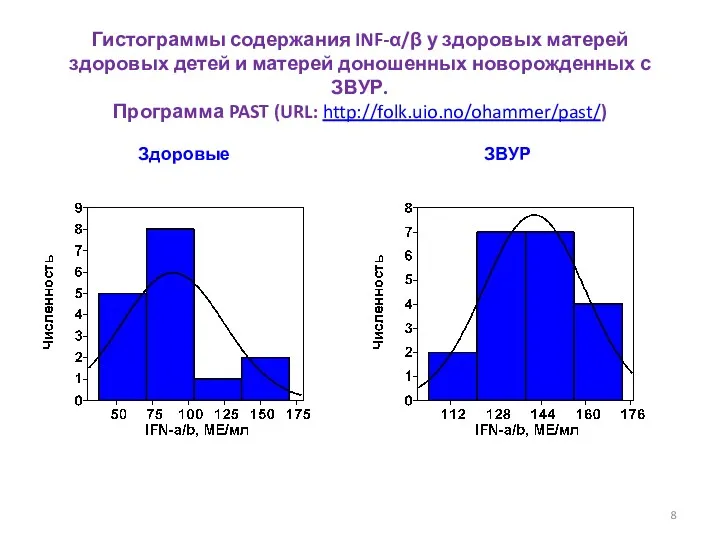
Гистограммы содержания INF-α/β у здоровых матерей здоровых детей и матерей доношенных
Гистограммы содержания INF-α/β у здоровых матерей здоровых детей и матерей доношенных
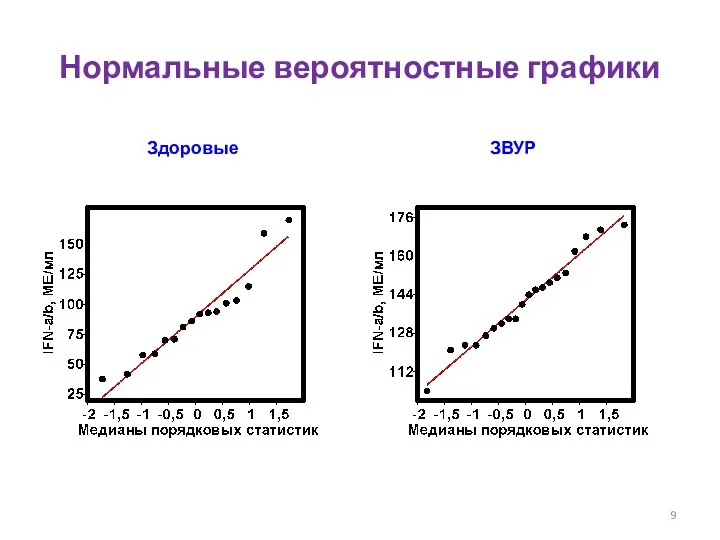
Нормальные вероятностные графики
Здоровые
ЗВУР
Нормальные вероятностные графики
Здоровые
ЗВУР
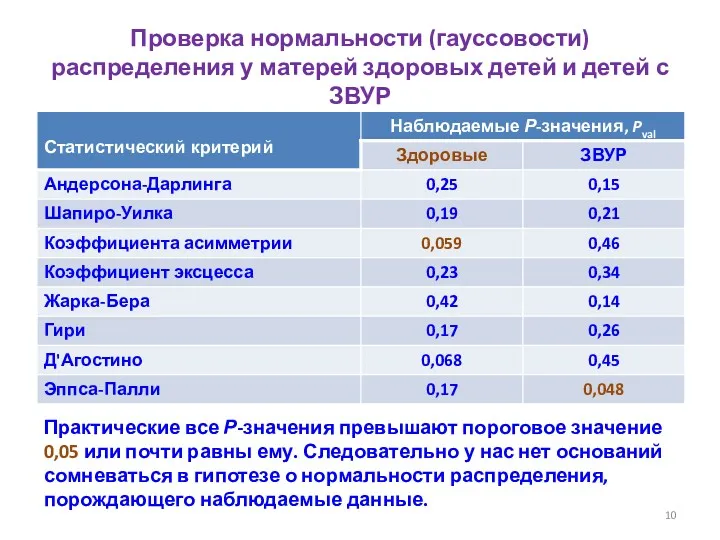
Проверка нормальности (гауссовости) распределения у матерей здоровых детей и детей с
Проверка нормальности (гауссовости) распределения у матерей здоровых детей и детей с
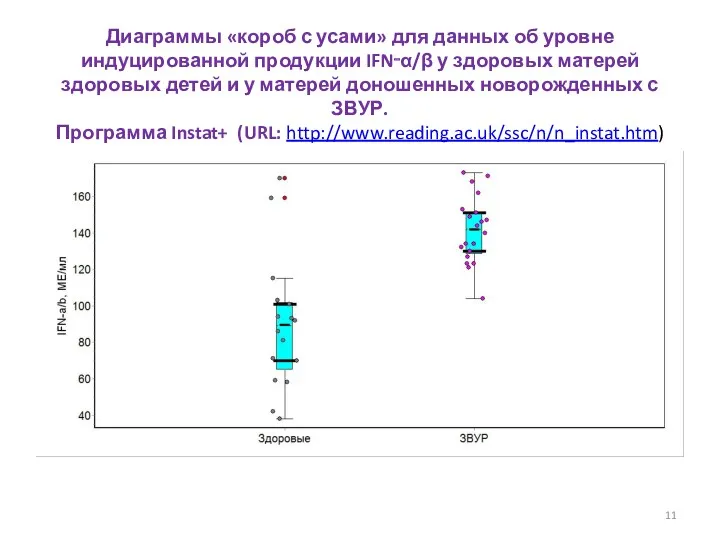
Диаграммы «короб с усами» для данных об уровне индуцированной продукции IFN‑α/β
Диаграммы «короб с усами» для данных об уровне индуцированной продукции IFN‑α/β

Исключение резко выделяющихся наблюдений
С рекомендаций по отбрасыванию выскакивающих (экстремальных) наблюдений («выбросов»,
Исключение резко выделяющихся наблюдений
С рекомендаций по отбрасыванию выскакивающих (экстремальных) наблюдений («выбросов»,

Резко выделяющиеся значения – «выбросы»
Выскакивающие значения можно и нужно выявлять.
Но
Резко выделяющиеся значения – «выбросы»
Выскакивающие значения можно и нужно выявлять.
Но

Сжатие (свертка, редукция) статистических данных
Статистика – любая функция от случайных величин,
Сжатие (свертка, редукция) статистических данных
Статистика – любая функция от случайных величин,

Основная логика статистического оценивания: интервальные оценки
Понятно, что если мы многократно повторим
Основная логика статистического оценивания: интервальные оценки
Понятно, что если мы многократно повторим

Статистические гипотезы
В обычном языке слово «гипотеза» означает предположение.
В том же
Статистические гипотезы
В обычном языке слово «гипотеза» означает предположение.
В том же

Проверяемая гипотеза
В подавляющем большинстве реальных ситуаций проверяемая статистическая гипотеза является гипотезой
Проверяемая гипотеза
В подавляющем большинстве реальных ситуаций проверяемая статистическая гипотеза является гипотезой

Использование доверительных интервалов (ДИ) для проверки нулевых гипотез
Например, для проверки нулевой
Использование доверительных интервалов (ДИ) для проверки нулевых гипотез
Например, для проверки нулевой

Визуализация результатов проверки статистических гипотез с помощью доверительных интервалов для размера
Визуализация результатов проверки статистических гипотез с помощью доверительных интервалов для размера
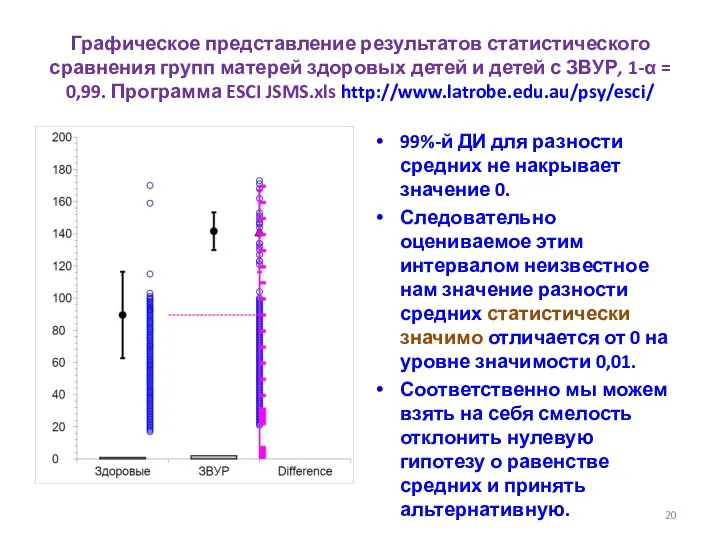
Графическое представление результатов статистического сравнения групп матерей здоровых детей и детей
Графическое представление результатов статистического сравнения групп матерей здоровых детей и детей

Статистики критериев (тестовые статистики)
Тестовая статистика – статистика, используемая для проверки конкретной
Статистики критериев (тестовые статистики)
Тестовая статистика – статистика, используемая для проверки конкретной

Проблема Беренса-Фишера
Если дисперсии сравниваемых двух независимых случайных величин не равны, то,
Проблема Беренса-Фишера
Если дисперсии сравниваемых двух независимых случайных величин не равны, то,

Статистика Уэлча приближенно имеет t-распределение Стьюдента, но со степенью свободы νW,
Статистика Уэлча приближенно имеет t-распределение Стьюдента, но со степенью свободы νW,

Р-значение
Для проверки нулевых гипотез с помощью статистических критериев основным приемом является
Р-значение
Для проверки нулевых гипотез с помощью статистических критериев основным приемом является
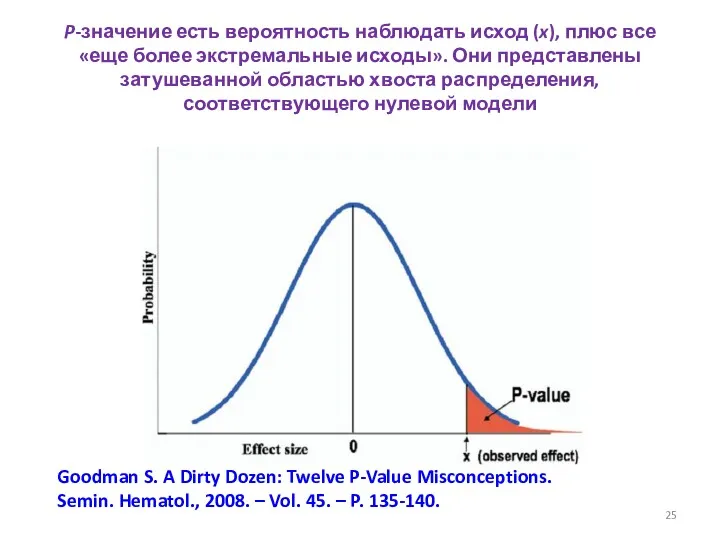
P-значение есть вероятность наблюдать исход (x), плюс все «еще более экстремальные
P-значение есть вероятность наблюдать исход (x), плюс все «еще более экстремальные
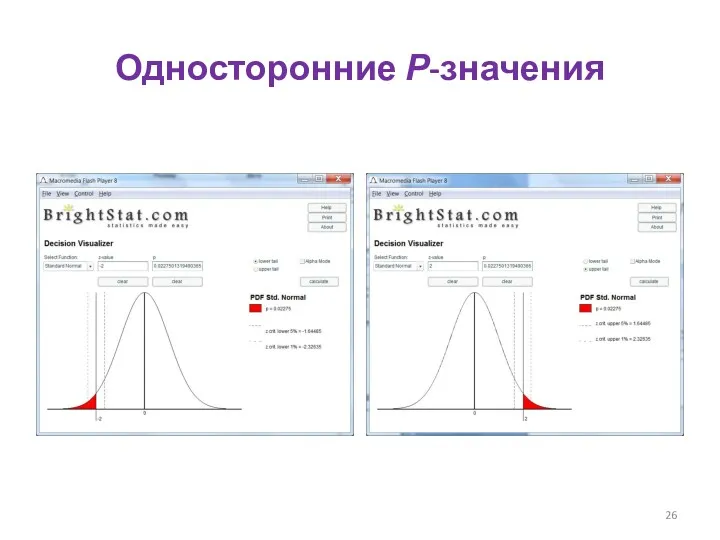
Односторонние Р-значения
Односторонние Р-значения
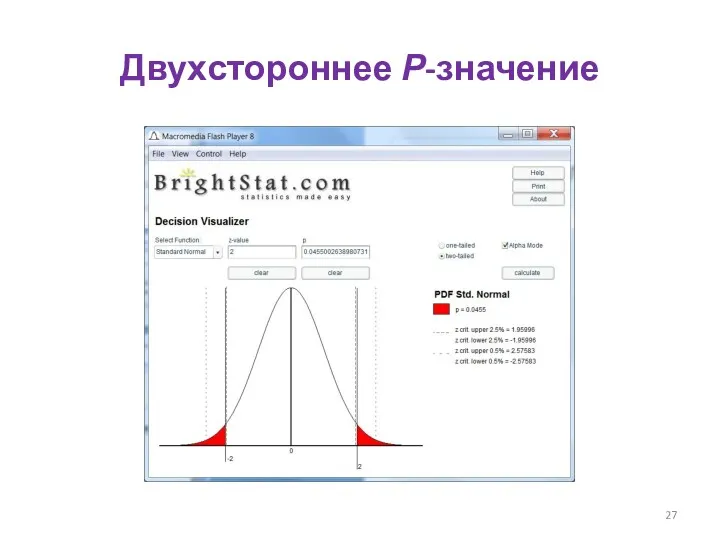
Двухстороннее Р-значение
Двухстороннее Р-значение

Основная логика использования наблюдаемого значения величины P состоит в том, что
Основная логика использования наблюдаемого значения величины P состоит в том, что

Выбор порога для значения P, и можно ли его обосновать?
Когда наблюдаемое
Выбор порога для значения P, и можно ли его обосновать?
Когда наблюдаемое
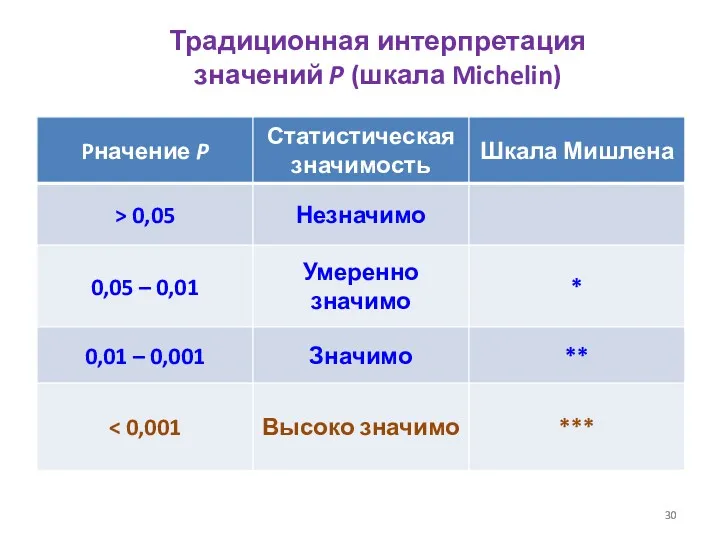
Традиционная интерпретация
значений P (шкала Michelin)
Традиционная интерпретация
значений P (шкала Michelin)

Результаты статистического сравнение групп матерей здоровых детей и детей с ЗВУР,
Результаты статистического сравнение групп матерей здоровых детей и детей с ЗВУР,

Акт интеллектуальной смелости
Когда значение P очень мало, мы берем на себя
Акт интеллектуальной смелости
Когда значение P очень мало, мы берем на себя

Распространенный соблазн
Квинтэссенцию традиционных (частотнических) заключений при проверке статистических гипотез принято интерпретировать
Распространенный соблазн
Квинтэссенцию традиционных (частотнических) заключений при проверке статистических гипотез принято интерпретировать

Распространенное заблуждение
Значение P не есть вероятность нулевой гипотезы !
Поскольку P-значение вычисляется
при
Распространенное заблуждение
Значение P не есть вероятность нулевой гипотезы !
Поскольку P-значение вычисляется
при

Р-значение потому столь привлекательно для ученых, что с ним очень легко
Р-значение потому столь привлекательно для ученых, что с ним очень легко
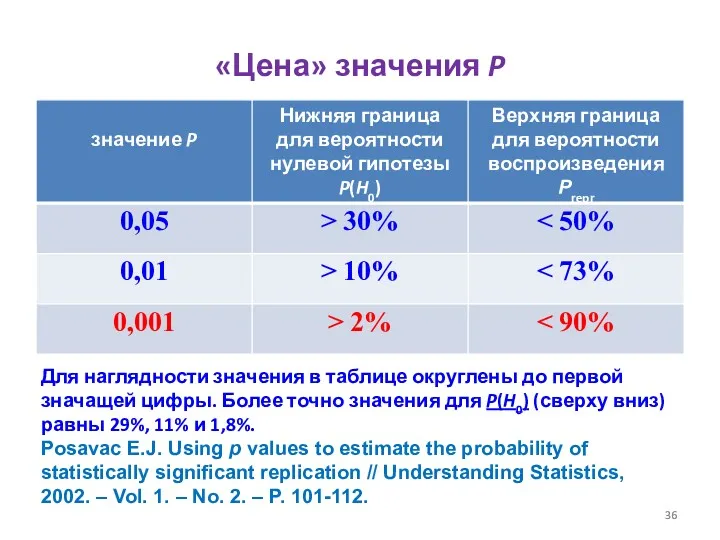
«Цена» значения P
Для наглядности значения в таблице округлены до первой
«Цена» значения P
Для наглядности значения в таблице округлены до первой

Бейзовская интерпретация значения P
Обычно принято интерпретировать значения P как меру
Бейзовская интерпретация значения P
Обычно принято интерпретировать значения P как меру

Привычка свыше нам дана
Это прекрасно понимал Р.А. Фишер:
«Критерий значимости не
Привычка свыше нам дана
Это прекрасно понимал Р.А. Фишер:
«Критерий значимости не

Статистическая значимость и
размер эффекта
Эффект (различие, связь, риск, польза, ассоциация и
Статистическая значимость и
размер эффекта
Эффект (различие, связь, риск, польза, ассоциация и

Размер эффекта
Вопрос о клинической (практической) ценности (важности) наблюдаемого размера эффекта
является
Размер эффекта
Вопрос о клинической (практической) ценности (важности) наблюдаемого размера эффекта
является

Стандартизированный размер эффекта по Коуэну (Cohen) dC
Стандартизированный размер эффекта по Коуэну (Cohen) dC
Интерпретация стандартизированного размера эффекта dC http://www.sportsci.org/resource/stats/
Интерпретация стандартизированного размера эффекта dC http://www.sportsci.org/resource/stats/

Результаты статистического сравнения групп матерей здоровых детей и детей с ЗВУР,
Результаты статистического сравнения групп матерей здоровых детей и детей с ЗВУР,
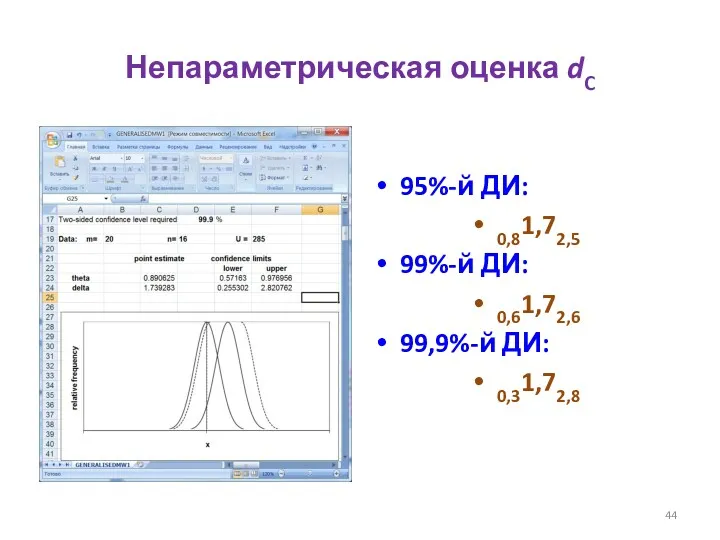
Непараметрическая оценка dC
95%-й ДИ:
0,81,72,5
99%-й ДИ:
0,61,72,6
99,9%-й ДИ:
0,31,72,8
Непараметрическая оценка dC
95%-й ДИ:
0,81,72,5
99%-й ДИ:
0,61,72,6
99,9%-й ДИ:
0,31,72,8

Бейзов фактор, BF
Бейзов фактор BF принципиально отличается от значения P.
Бейзов
Бейзов фактор, BF
Бейзов фактор BF принципиально отличается от значения P.
Бейзов

Интерпретация убедительности
Бейзовых факторов, BF10 и BF01
Интерпретация убедительности
Бейзовых факторов, BF10 и BF01
Бейзов фактор, программа Bayes Factor Calculators
http://pcl.missouri.edu/bayesfactor
Бейзов фактор, программа Bayes Factor Calculators
http://pcl.missouri.edu/bayesfactor
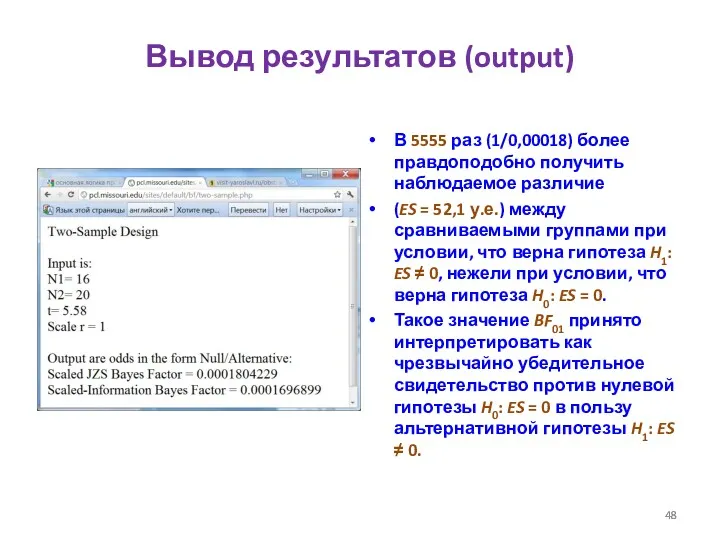
Вывод результатов (output)
В 5555 раз (1/0,00018) более правдоподобно получить наблюдаемое различие
Вывод результатов (output)
В 5555 раз (1/0,00018) более правдоподобно получить наблюдаемое различие

Достаточно малое значение P заставляет думать, что произошло нечто неожиданное.
И обычно
Достаточно малое значение P заставляет думать, что произошло нечто неожиданное.
И обычно

Статистические предсказания и воспроизводимость
Статистические предсказания и воспроизводимость

Значение вероятностной P-величины
Значение P есть наблюдаемое значение (реализация) соответствующей случайной величины
Всякий
Значение вероятностной P-величины
Значение P есть наблюдаемое значение (реализация) соответствующей случайной величины
Всякий

Отсюда следует, что, строго говоря, на основе всего лишь одного изолированного
Отсюда следует, что, строго говоря, на основе всего лишь одного изолированного

Доверяя, повторяй
Часто считается, что если получен «статистически значимый» результат, то это
Доверяя, повторяй
Часто считается, что если получен «статистически значимый» результат, то это
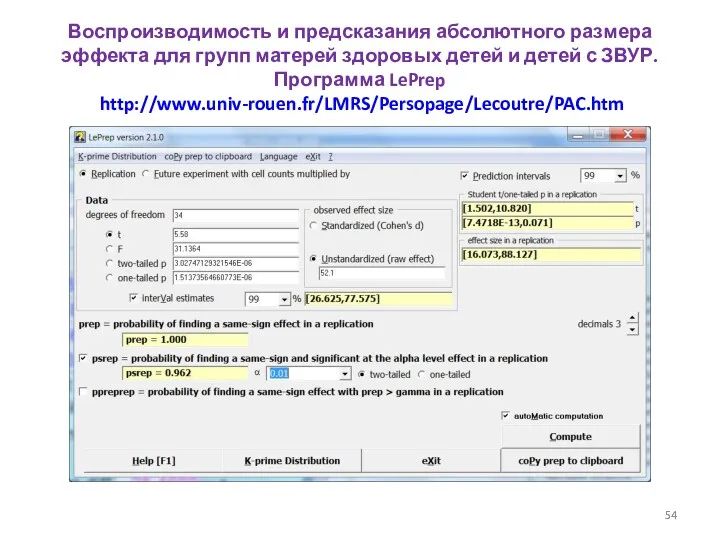
Воспроизводимость и предсказания абсолютного размера эффекта для групп матерей здоровых детей
Воспроизводимость и предсказания абсолютного размера эффекта для групп матерей здоровых детей
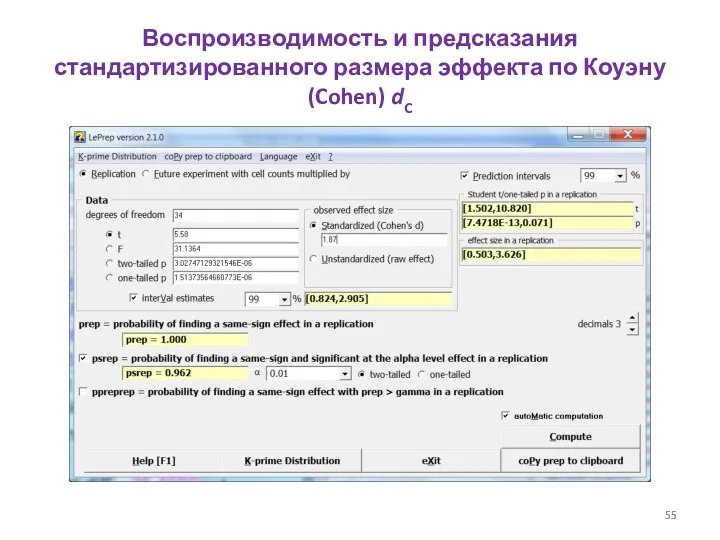
Воспроизводимость и предсказания стандартизированного размера эффекта по Коуэну (Cohen) dC
Воспроизводимость и предсказания стандартизированного размера эффекта по Коуэну (Cohen) dC

Воспроизводимость и предсказания размеров эффекта ES и dC для групп матерей
Воспроизводимость и предсказания размеров эффекта ES и dC для групп матерей

Ошибки I и II рода
и мощность статистического критерия
Ошибки I и II рода
и мощность статистического критерия
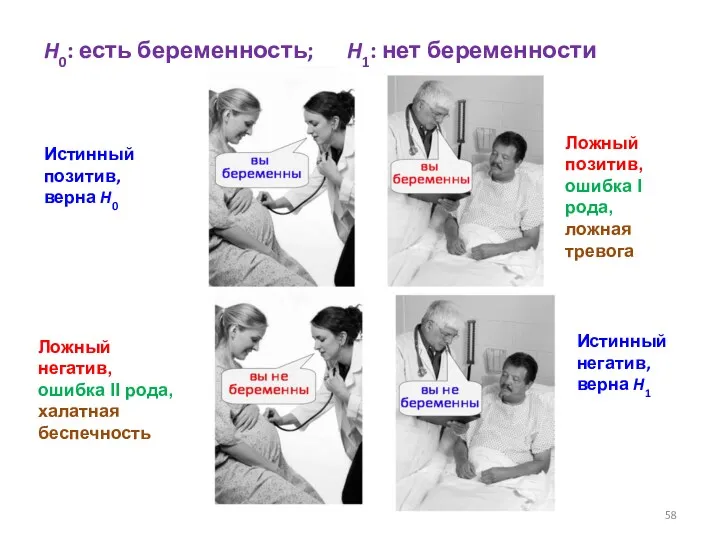
Истинный позитив, верна H0
Истинный негатив, верна H1
Ложный позитив, ошибка
Истинный позитив, верна H0
Истинный негатив, верна H1
Ложный позитив, ошибка
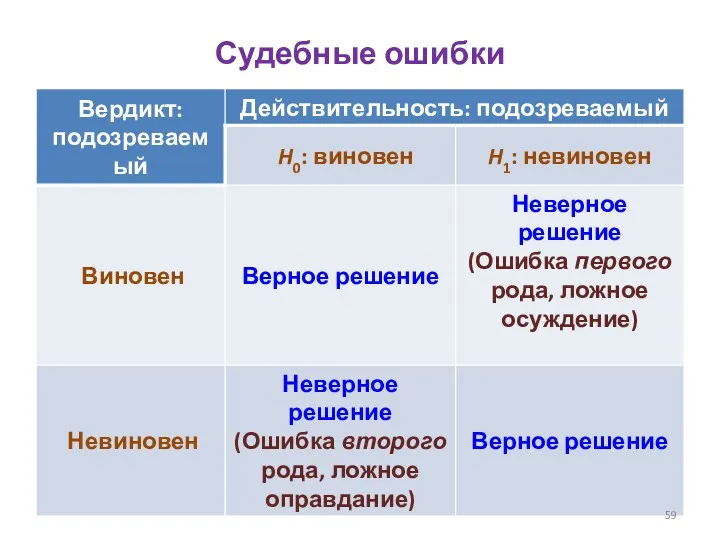
Судебные ошибки
Судебные ошибки
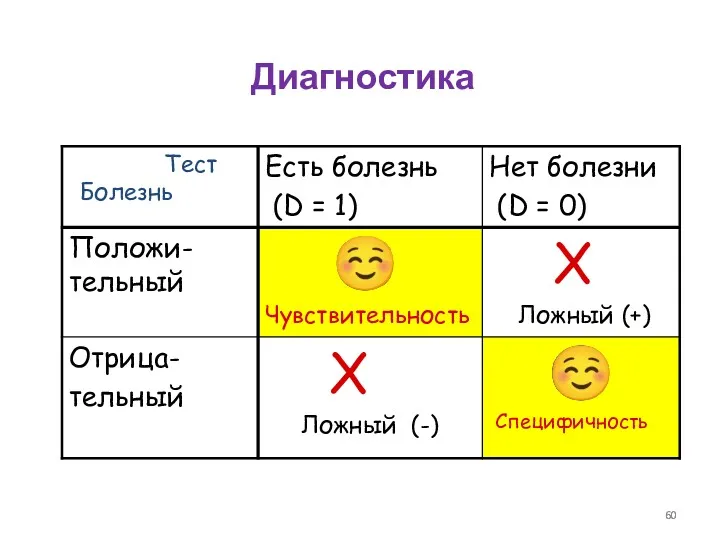
Диагностика
Болезнь
Тест
Диагностика
Болезнь
Тест
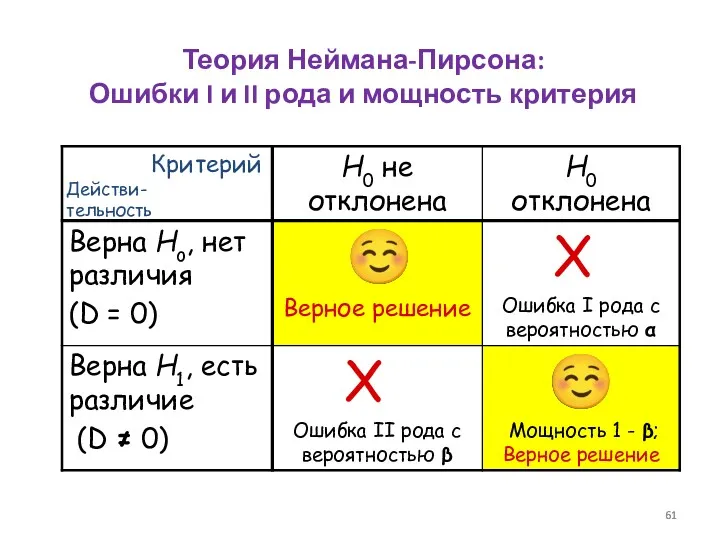
Теория Неймана-Пирсона:
Ошибки I и II рода и мощность критерия
Действи-тельность
Критерий
Теория Неймана-Пирсона:
Ошибки I и II рода и мощность критерия
Действи-тельность
Критерий

Ошибки I и II рода
Ошибка I рода: отклонение верной нулевой гипотезы;
Ошибки I и II рода
Ошибка I рода: отклонение верной нулевой гипотезы;
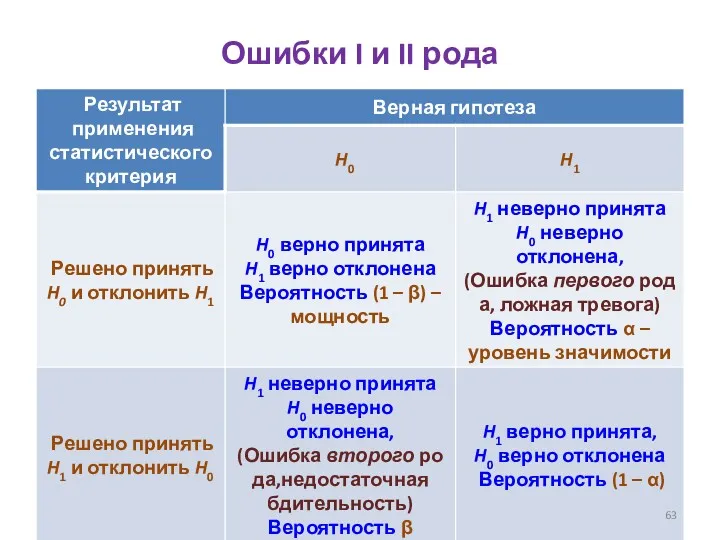
Ошибки I и II рода
Ошибки I и II рода

Компромисс
Например, в случае металлодетектора. H0 – обнаружен нейтральный предмет.
повышение чувствительности прибора
Компромисс
Например, в случае металлодетектора. H0 – обнаружен нейтральный предмет.
повышение чувствительности прибора

Мощность статистического критерия
Мощность статистического критерия есть вероятность того, что критерий правильно
Мощность статистического критерия
Мощность статистического критерия есть вероятность того, что критерий правильно

Мощность отвечает на вопрос:
Если эффект (определенного размера) действительно существует, то какова
Мощность отвечает на вопрос:
Если эффект (определенного размера) действительно существует, то какова

Анализ мощности a priori или post-hoc
Анализ мощности можно проводить либо a
Анализ мощности a priori или post-hoc
Анализ мощности можно проводить либо a
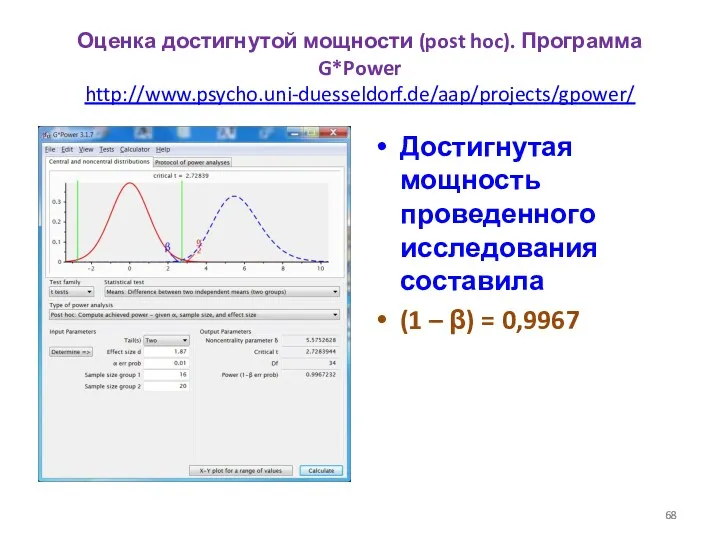
Оценка достигнутой мощности (post hoc). Программа G*Power
http://www.psycho.uni-duesseldorf.de/aap/projects/gpower/
Достигнутая мощность проведенного исследования составила
(1
Оценка достигнутой мощности (post hoc). Программа G*Power
http://www.psycho.uni-duesseldorf.de/aap/projects/gpower/
Достигнутая мощность проведенного исследования составила
(1

Элементы планирования эксперимента
Элементы планирования эксперимента

Программа G*Power
http://www.psycho.uni-duesseldorf.de/abteilungen/aap/gpower3
Оценка a priori минимально необходимого объема выборки N для
Программа G*Power
http://www.psycho.uni-duesseldorf.de/abteilungen/aap/gpower3
Оценка a priori минимально необходимого объема выборки N для
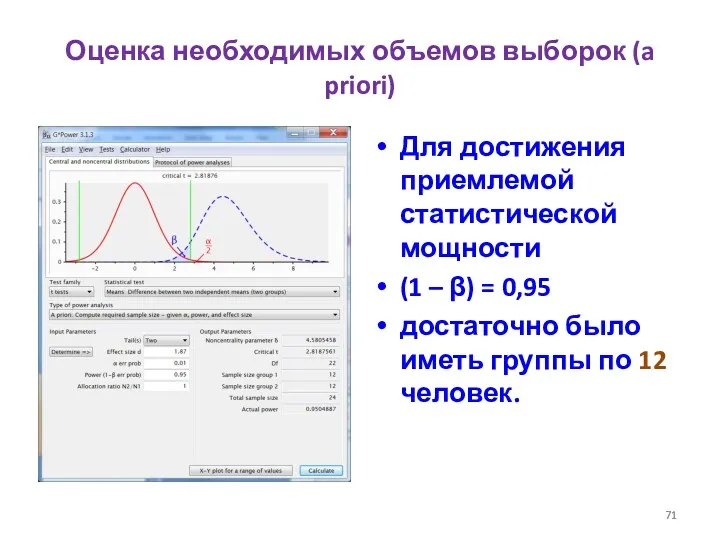
Оценка необходимых объемов выборок (a priori)
Для достижения приемлемой статистической мощности
(1
Оценка необходимых объемов выборок (a priori)
Для достижения приемлемой статистической мощности
(1

Научный метод
Ни один уважающий себя ученый не ограничится в своих
Научный метод
Ни один уважающий себя ученый не ограничится в своих

Культ одиночного изолированного исследования
Чрезмерное «увлечение» анализом одиночных наборов данных пронизывает почти
Культ одиночного изолированного исследования
Чрезмерное «увлечение» анализом одиночных наборов данных пронизывает почти
 Парная линейная регрессия в экономике
Парная линейная регрессия в экономике Действия с натуральными числами
Действия с натуральными числами Конспект урока математики 3 класс Закрепление темы: Таблица умножения на 2,3,4,5,6. Решение задач
Конспект урока математики 3 класс Закрепление темы: Таблица умножения на 2,3,4,5,6. Решение задач Применение различных способов разложения многочлена на множители. 7 класс
Применение различных способов разложения многочлена на множители. 7 класс Сложение числа б с однозначными числами. 1 класс
Сложение числа б с однозначными числами. 1 класс Векторы в пространстве
Векторы в пространстве Математика, 4 класс. Тема: Углы. Виды углов
Математика, 4 класс. Тема: Углы. Виды углов Треугольники. Виды треугольников. Признаки равенства треугольников
Треугольники. Виды треугольников. Признаки равенства треугольников Внеклассное мероприятие по математике: Своя игра
Внеклассное мероприятие по математике: Своя игра Формы и методы подготовки аналитической информации
Формы и методы подготовки аналитической информации Сечение поверхности плоскостью. (Лекция 6)
Сечение поверхности плоскостью. (Лекция 6) Виды углов. Измерение углов. 5 класс
Виды углов. Измерение углов. 5 класс Тікбұрышты параллелепипед көлемі
Тікбұрышты параллелепипед көлемі Презентация к уроку математики по теме: Нахождение неизвестного множителя. 3 класс УМК Перспективная начальная школа
Презентация к уроку математики по теме: Нахождение неизвестного множителя. 3 класс УМК Перспективная начальная школа Дроби и проценты. Нахождение процента от величины
Дроби и проценты. Нахождение процента от величины Площадь. Свойства площади. Формула площади прямоугольника
Площадь. Свойства площади. Формула площади прямоугольника Моделирование систем и процессов. Теория графов. (Лекция 2)
Моделирование систем и процессов. Теория графов. (Лекция 2) Двугранный угол
Двугранный угол Тест. Таблица умножения.
Тест. Таблица умножения. Текстовые задачи и пути их решения. Элективный курс. 9 класс
Текстовые задачи и пути их решения. Элективный курс. 9 класс Презентация. Математика. Умножение
Презентация. Математика. Умножение Способы доказательства теоремы Пифагора
Способы доказательства теоремы Пифагора Признак перпендикулярности прямой и плоскости. (10 класс)
Признак перпендикулярности прямой и плоскости. (10 класс) Презентация к уроку математики Морское путешествие
Презентация к уроку математики Морское путешествие Можно ли без шаблона разметить круг? Циркуль – чертежный инструмент
Можно ли без шаблона разметить круг? Циркуль – чертежный инструмент Урок с применением ИКТ
Урок с применением ИКТ презентация по теме Развитие креативного мышления младших школьников средством дидактических игр на уроках математики в системе развивающего обучения
презентация по теме Развитие креативного мышления младших школьников средством дидактических игр на уроках математики в системе развивающего обучения Обобщение материала по теме Умножение и деление обыкновенных дробей 6 класс
Обобщение материала по теме Умножение и деление обыкновенных дробей 6 класс