- Корреляция. Понятие корреляционной связи

Содержание
- 2. 1 В статистике различают функциональную и стохастическую связи. Функциональной называют такую связь, при которой имеется однозначное
- 3. 2 Корреляционной связью называют такой частный случай стохастической связи, при которой различным значениям факторного признака соответствуют
- 4. 3 По направлению выделяют связь прямую и обратную. При прямой связи увеличение или уменьшение факторного признака
- 5. 4 По аналитическому выражению связи могут быть линейными и нелинейными. Если статистическая связь между явлениями может
- 6. 5 Принято различать: а) парную корреляцию - связь между результативным и факторным признаками; б) частную корреляцию
- 7. 6 Задачей эконометрического анализа является определение аналитического выражения уравнения связи, которое может зависеть от одного факторного
- 8. 7 В некоторых случаях можно ограничиться лишь качественными результатами о наличии корреляции между признаками и ее
- 9. 8 Вернемся к примеру рассмотренному во введении. На основании данных о годовом располагаемом доходе и годовых
- 10. 9 Обозначения: DPI ( disposable personal income) - доходы PC (personal consumption) - расходы; усл. ед.
- 11. 10 Графическое изображение корреляционного поля
- 12. 11 Расположение точек на графике отражает общую тенденцию вариации факторного и результативного признаков. Теперь хорошо видно,
- 13. 12 Определим линейный коэффициент корреляции как среднее значение произведения нормированных отклонений результативного и факторного признаков от
- 14. 13 Линейный коэффициент корреляции может принимать значения в пределах от -1 до +1 . При наличии
- 15. 14 Эмпирическая схема определения тесноты связи
- 16. 15 Задача На основе приведенной ниже таблицы найти линейный коэффициент корреляции расходов на питание и годовых
- 17. 16 Найдем среднее значение и дисперсию признаков X и Y, используя стандартные функции Excel Срзнач ()
- 18. 2.13. Статистическая проверка гипотез
- 19. 1 Под статистической гипотезой понимают различного рода предположения о характере или параметрах распределения случайной величины ,
- 20. 2 При проверке гипотез ошибки могут быть двоякого рода: а) ошибка первого рода – проверяемая гипотеза
- 21. 3 Статистическая проверка гипотез осуществляется на основании некоторых критериев. Для построения такого критерия необходимо: а) сформулировать
- 22. 4 Уровнем значимости будем называть такое малое значение вероятности попадания критерия в критическую область при условии
- 23. 5 Вероятность совершить ошибку первого рода т. е. отвергнуть гипотезу Н0 когда она верна, называется уровнем
- 24. 6 Величина ошибки первого и второго рода однозначно определяется выбором критической области. Совершенно естественно их хочется
- 25. К понятию критической области Правая критическая область Левая критическая область Область принятия нулевой гипотезы
- 26. 2.14. Статистическая оценка значимости линейного коэффициента корреляции
- 27. 1 Для ответа на вопрос о значимости коэффициента корреляции необходимо при заданном уровне значимости проверить нулевую
- 28. 2 Для проверки нулевой гипотезы рассмотрим величину При справедливости нулевой гипотезы случайная величина t подчиняется распределению
- 29. 3 Отсюда следует простое правило: для того, чтобы при заданном уровне значимости проверить нулевую гипотезу о
- 30. 4 Затем по таблице критических точек распределения Стьюдента при данном числе степеней свободы и уровне значимости
- 31. 5 Применим изложенный выше подход к рассматриваемой задаче . Подставляя численные значения , получаем t эмп
- 32. 3. Парный Регрессионный анализ
- 33. 1 Рассмотрим теперь задачу об определении уравнения линии регрессии. Теоретической линией регрессии называется такая линия, вокруг
- 34. 2 Обсудим применения этого метода для случая, когда предполагается линейная связь между факторным и результативным признаками.
- 35. 2a 2a К определению понятия случайной ошибки точка 1 2 точка i точка i -1
- 36. 3 Очевидно, что S является функцией двух переменных, и поэтому условие минимума дает два уравнения: После
- 37. 4 Действительно. Подставим в выражение для S и продифференцируем это выражение по а: Отсюда получаем первое
- 38. 4а Таким образом, получаем следующую систему нормальных уравнений для определения коэффициентов регрессии
- 39. 5 Решая систему двух уравнений относительно неизвестных коэффициентов a и b, получаем расчетные формулы
- 40. 6 Параметр b называют коэффициентом регрессии. Коэффициент регрессии используют для определения параметра эластичности Между коэффициентом регрессии
- 41. 7 Воспользуемся данными табл. на слайде 16 и найдем параметры линейной регрессионной модели для этой задачи.
- 42. 8 Следовательно уравнение регрессии будет иметь вид
- 43. 9 X Y Регрессионное уравнение, полученное с помощью Excel
- 44. 9 Хотя выше был рассмотрен лишь с случай линейной функции, во многих случаях можно использовать эти
- 45. 10 Действительно, прологарифмировав уравнение степенной зависимости, имеем линейную зависимость для логарифмов Аналогично можно подобрать подходящую замену
- 46. 3. 1. Оценка значимости регрессионной модели. Коэффициент детерминации
- 47. 1 В рассматриваемой линейной модели регрессии вариация зависимой переменной y не может быть объяснена только действием
- 48. 2 Отметим основные постулаты, которые должны выполняться для того, чтобы можно было считать применение регрессионного анализа
- 49. 3 4. Возмущения являются независимыми. Отсюда следует, что 5. Возмущение или зависимая переменная уi распределены по
- 50. 4 Для КНЛР - модели доказано несколько важных математических теорем, которые мы примем без доказательства. Теорема
- 51. 5 Одной из задач регрессионного анализа является оценка адекватности модели. Для проверки того, насколько хорошо кривая
- 52. 6 Оценка адекватности линейной модели регрессии на основе вычисления фактора детерминации и оценка значимости уравнения регрессии
- 53. 7 Основная идея метода состоит в том, чтобы разделить общую вариацию факторного признака на часть, которая
- 54. 7а Деление вариации Y на объясняемую и необъясняемую регрессией части
- 55. 7б При возведении в квадрат и последующем суммировании получаем Преобразуем последнее слагаемое. Первое произведение представим в
- 56. 7в Для преобразования второго сомножителя преобразуем сначала последнее выражение И подставим этот результат в рассматриваемый член.
- 57. 7г Поскольку, как было показано ранее, коэффициент b может быть представлен в виде
- 58. 8 Величина QR дает сумму квадратов отклонений, объясненной моделью (Regression sum of squares). Будем использовать для
- 59. 8а Очевидно, что если QR >> QE , то уравнение регрессии статистически значимо и фактор х
- 60. 8б Напомним, что для получения несмещенной оценки дисперсии, сумму квадратов отклонений от средней следует делить не
- 61. 8в
- 62. 9 Рассмотрим две оценки дисперсии где m число параметров в уравнении регрессии, n – число наблюдений.
- 63. 10 Задача. Используя приведенные данные оценить значимость линейной модели связи расходов на питание и доходов семьи
- 64. 11 Линейное регрессионное уравнение было получено ранее и имеет вид Используя электронные таблицы Excel, находим суммы
- 65. 12 Величина F подчиняется распределению Фишера –Снедекора для K1=1, K2=4. Используя функцию Excel FРАСПОБР(0,05;1;4) Получаем критическое
- 66. График плотности распределения Фишера -Снедекора для k1=1, k2=4. Критическая область справа от желтой линии.
- 67. 13а Для проверки значимости линейного уравнения регрессии можно использовать и функцию ЛИНЕЙН ( ) электронных таблиц
- 68. 13 б Задача Имеются следующие данные об общем объеме розничного товарооборота региона по месяцам в 1997
- 69. 14 Sy F n-2 QR Q E Для нахождения параметров линейной модели применим функцию Линейн электронных
- 70. 15 Для оценки значимости регрессионной модели найдем критическую точку распределения Фишера при уровне значимости 0,05 и
- 71. 16 Как уже указывалось, одной из наиболее эффективных оценок адекватности регрессионных моделей, мерой качества уравнения регрессии
- 72. 17 Действительно, вспоминая уравнение для определения коэффициента а и регрессионное уравнение Подставляя последний результат в определение
- 73. 18
- 74. 19 Следует заметить, что оценка качества регрессионного уравнения с помощью критерия Фишера или коэффициента детерминации возможно
- 75. 3. 2. Проверка значимости коэффициентов регрессии Интервальная оценка для коэффициентов регрессии и индивидуальных значений зависимой переменной.
- 76. 1 В линейной регрессии обычно оценивается значимость не только уравнения в целом, но и отдельных его
- 77. 2 В условиях справедливости выдвинутой гипотезы случайные величины tb и ta подчиняются распределению Стьюдента. Поэтому для
- 78. 3 Для нахождения mb найдем дисперсию коэффициента b. Для этого используем запись коэффициента b в виде
- 79. 4 Оценим дисперсию используя формулу остаточной дисперсии. В условиях справедливости выдвигаемой гипотезы (равенства нулю коэффициента b)
- 80. 5 В итоге получаем среднеквадратическое отклонение (ошибку) для коэффициента b в виде Поэтому, если то коэффициент
- 81. 6 интервальная оценка коэффициента при заданном уровне значимости (tкрит) определяется стандартными формулами Статистическая оценка значимости коэффициента
- 82. 6а После такого преобразования коэффициента а, можно вычислить его дисперсию. Введем обозначение Найдем дисперсию коэффициента a.
- 83. 6б Учитывая, что дисперсия суммы равна сумме дисперсий, а также то, что величины xi не являются
- 84. 7 Оценка значимости и расчет доверительного интервала при заданном уровне значимости, определяется точно также как и
- 85. 8 Используя электронные таблицы Excel можно избежать утомительных вычислений, поскольку функция ЛИНЕЙН ( ) возвращает и
- 86. 9 Построим доверительный интервал для функции регрессии т. е. интервал значений переменной yТ, который при заданной
- 87. 10 Найдем среднеквадратическое отклонение для предсказываемых моделью значений yT Дисперсия среднего значения факторной переменной оценивается по
- 88. 11 Дисперсия коэффициента b вычислялась ранее и равна учитывая два последних результата, получаем
- 89. 12 В качестве оценки для дисперсии результативного признака снова возьмем величину необъясненной дисперсии В результате получаем
- 90. 13 Поскольку случайная величина подчиняется распределению Стьюдента с числом степеней свободы k=n-2, то доверительный интервал для
- 92. Скачать презентацию

1
В статистике различают функциональную и стохастическую связи.
Функциональной называют
1
В статистике различают функциональную и стохастическую связи.
Функциональной называют

2
Корреляционной связью называют такой частный случай стохастической связи, при которой
2
Корреляционной связью называют такой частный случай стохастической связи, при которой

3
По направлению выделяют связь прямую и обратную.
При прямой
3
По направлению выделяют связь прямую и обратную.
При прямой

4
По аналитическому выражению связи могут быть линейными и нелинейными.
4
По аналитическому выражению связи могут быть линейными и нелинейными.

5
Принято различать:
а) парную корреляцию - связь между результативным и
5
Принято различать:
а) парную корреляцию - связь между результативным и

6
Задачей эконометрического анализа является определение аналитического выражения уравнения связи, которое
6
Задачей эконометрического анализа является определение аналитического выражения уравнения связи, которое

7
В некоторых случаях можно ограничиться лишь качественными результатами о наличии
7
В некоторых случаях можно ограничиться лишь качественными результатами о наличии

8
Вернемся к примеру рассмотренному во введении. На
8
Вернемся к примеру рассмотренному во введении. На
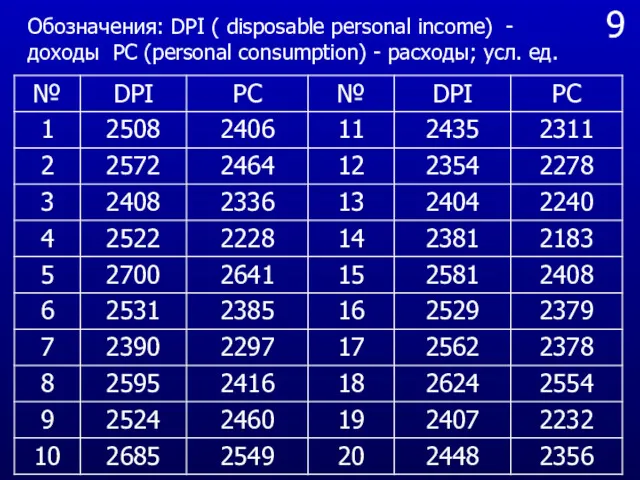
9
Обозначения: DPI ( disposable personal income) - доходы PC (personal consumption)
9
Обозначения: DPI ( disposable personal income) - доходы PC (personal consumption)
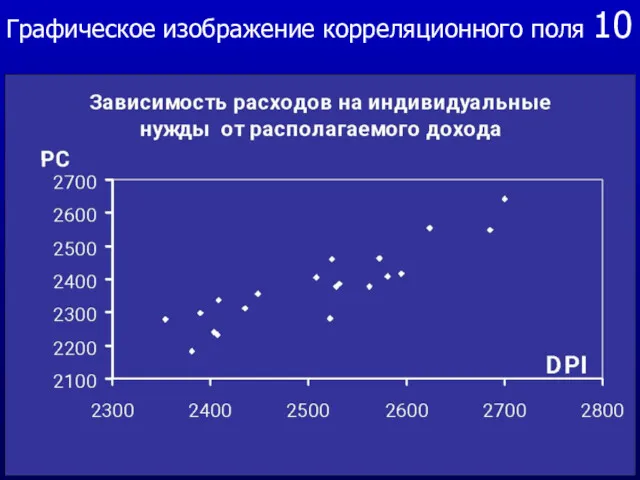
10
Графическое изображение корреляционного поля
10
Графическое изображение корреляционного поля

11
Расположение точек на графике отражает общую тенденцию вариации факторного
11
Расположение точек на графике отражает общую тенденцию вариации факторного

12
Определим линейный коэффициент корреляции как среднее значение произведения нормированных отклонений результативного
12
Определим линейный коэффициент корреляции как среднее значение произведения нормированных отклонений результативного

13
Линейный коэффициент корреляции может принимать значения в пределах от -1
13
Линейный коэффициент корреляции может принимать значения в пределах от -1

14
Эмпирическая схема определения тесноты связи
14
Эмпирическая схема определения тесноты связи
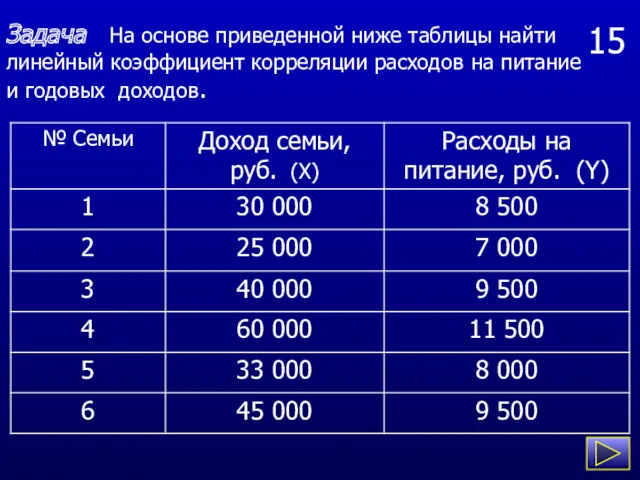
15
Задача На основе приведенной ниже таблицы найти линейный коэффициент корреляции расходов
15
Задача На основе приведенной ниже таблицы найти линейный коэффициент корреляции расходов

16
Найдем среднее значение и дисперсию признаков X и Y, используя
16
Найдем среднее значение и дисперсию признаков X и Y, используя

2.13. Статистическая
проверка гипотез
2.13. Статистическая
проверка гипотез

1
Под статистической гипотезой понимают различного рода предположения о характере или
1
Под статистической гипотезой понимают различного рода предположения о характере или

2
При проверке гипотез ошибки могут быть двоякого рода:
а) ошибка
2
При проверке гипотез ошибки могут быть двоякого рода:
а) ошибка

3
Статистическая проверка гипотез осуществляется на основании некоторых критериев.
Для
3
Статистическая проверка гипотез осуществляется на основании некоторых критериев.
Для

4
Уровнем значимости будем называть такое малое значение вероятности попадания критерия
4
Уровнем значимости будем называть такое малое значение вероятности попадания критерия

5
Вероятность совершить ошибку первого рода т. е. отвергнуть гипотезу Н0
5
Вероятность совершить ошибку первого рода т. е. отвергнуть гипотезу Н0

6
Величина ошибки первого и второго рода однозначно определяется выбором критической
6
Величина ошибки первого и второго рода однозначно определяется выбором критической
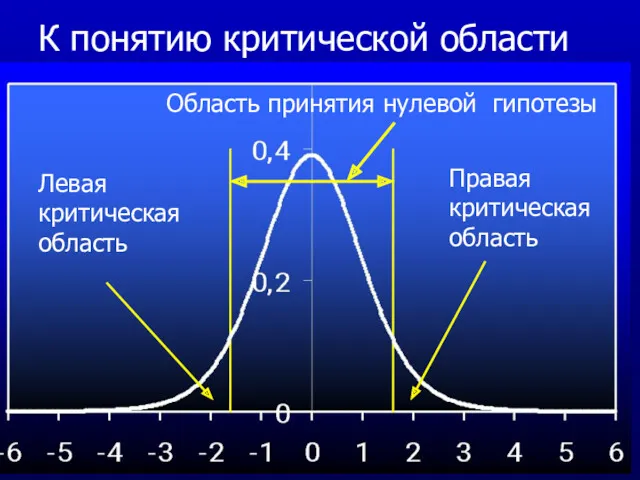
К понятию критической области
Правая критическая область
Левая критическая область
Область принятия нулевой гипотезы
К понятию критической области
Правая критическая область
Левая критическая область
Область принятия нулевой гипотезы

2.14. Статистическая оценка значимости линейного коэффициента корреляции
2.14. Статистическая оценка значимости линейного коэффициента корреляции

1
Для ответа на вопрос о значимости коэффициента корреляции необходимо при
1
Для ответа на вопрос о значимости коэффициента корреляции необходимо при

2
Для проверки нулевой гипотезы рассмотрим величину
При справедливости нулевой
2
Для проверки нулевой гипотезы рассмотрим величину
При справедливости нулевой

3
Отсюда следует простое правило: для того, чтобы при заданном уровне
3
Отсюда следует простое правило: для того, чтобы при заданном уровне

4
Затем по таблице критических точек распределения Стьюдента при данном числе
4
Затем по таблице критических точек распределения Стьюдента при данном числе

5
Применим изложенный выше подход к рассматриваемой задаче . Подставляя численные
5
Применим изложенный выше подход к рассматриваемой задаче . Подставляя численные

3. Парный Регрессионный анализ
3. Парный Регрессионный анализ

1
Рассмотрим теперь задачу об определении уравнения линии регрессии. Теоретической линией
1
Рассмотрим теперь задачу об определении уравнения линии регрессии. Теоретической линией

2
Обсудим применения этого метода для случая, когда предполагается линейная связь
2
Обсудим применения этого метода для случая, когда предполагается линейная связь
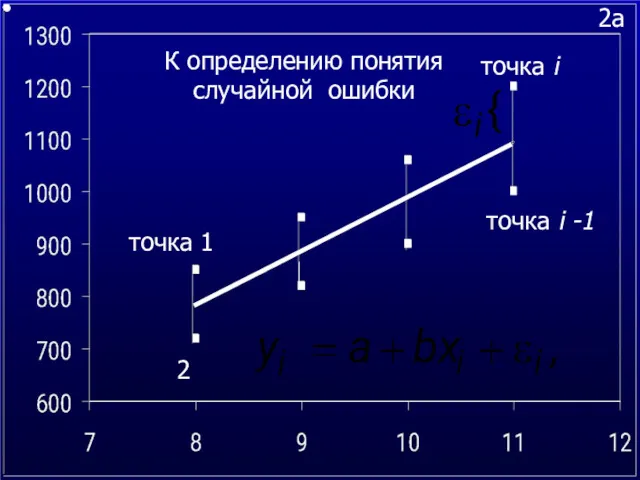
2a
2a
К определению понятия случайной ошибки
точка 1
2
точка i
точка i -1
2a
2a
К определению понятия случайной ошибки
точка 1
2
точка i
точка i -1

3
Очевидно, что S является функцией двух переменных, и поэтому условие
3
Очевидно, что S является функцией двух переменных, и поэтому условие

4
Действительно. Подставим
в выражение для S и продифференцируем это выражение по
4
Действительно. Подставим
в выражение для S и продифференцируем это выражение по

4а
Таким образом, получаем следующую систему нормальных уравнений для определения коэффициентов регрессии
4а
Таким образом, получаем следующую систему нормальных уравнений для определения коэффициентов регрессии

5
Решая систему двух уравнений относительно неизвестных коэффициентов a и b,
5
Решая систему двух уравнений относительно неизвестных коэффициентов a и b,

6
Параметр b называют коэффициентом регрессии. Коэффициент регрессии используют для определения
6
Параметр b называют коэффициентом регрессии. Коэффициент регрессии используют для определения

7
Воспользуемся данными табл. на слайде 16 и найдем параметры линейной
7
Воспользуемся данными табл. на слайде 16 и найдем параметры линейной

8
Следовательно уравнение регрессии будет иметь вид
8
Следовательно уравнение регрессии будет иметь вид
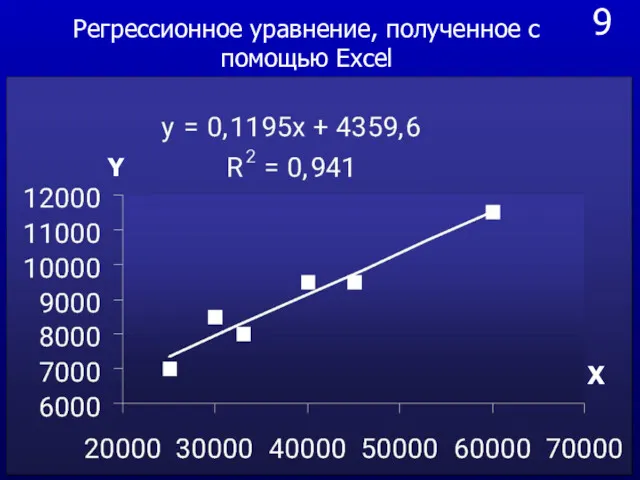
9
X
Y
Регрессионное уравнение, полученное с помощью Excel
9
X
Y
Регрессионное уравнение, полученное с помощью Excel

9
Хотя выше был рассмотрен лишь с случай линейной функции, во
9
Хотя выше был рассмотрен лишь с случай линейной функции, во

10
Действительно, прологарифмировав уравнение степенной зависимости, имеем линейную зависимость для логарифмов
Аналогично можно
10
Действительно, прологарифмировав уравнение степенной зависимости, имеем линейную зависимость для логарифмов
Аналогично можно

3. 1. Оценка значимости регрессионной модели.
Коэффициент детерминации
3. 1. Оценка значимости регрессионной модели.
Коэффициент детерминации

1
В рассматриваемой линейной модели регрессии вариация зависимой переменной y не
1
В рассматриваемой линейной модели регрессии вариация зависимой переменной y не

2
Отметим основные постулаты, которые должны выполняться для того, чтобы можно было
2
Отметим основные постулаты, которые должны выполняться для того, чтобы можно было

3
4. Возмущения являются независимыми. Отсюда следует, что
5. Возмущение или зависимая
3
4. Возмущения являются независимыми. Отсюда следует, что
5. Возмущение или зависимая

4
Для КНЛР - модели доказано несколько важных математических теорем, которые мы
4
Для КНЛР - модели доказано несколько важных математических теорем, которые мы

5
Одной из задач регрессионного анализа является оценка адекватности модели. Для
5
Одной из задач регрессионного анализа является оценка адекватности модели. Для

6
Оценка адекватности линейной модели регрессии на основе вычисления фактора детерминации
6
Оценка адекватности линейной модели регрессии на основе вычисления фактора детерминации

7
Основная идея метода состоит в том, чтобы разделить
7
Основная идея метода состоит в том, чтобы разделить

7а
Деление вариации Y на объясняемую и необъясняемую регрессией части
7а
Деление вариации Y на объясняемую и необъясняемую регрессией части

7б
При возведении в квадрат и последующем суммировании получаем
Преобразуем последнее слагаемое. Первое
7б
При возведении в квадрат и последующем суммировании получаем
Преобразуем последнее слагаемое. Первое

7в
Для преобразования второго сомножителя преобразуем сначала последнее выражение
И подставим этот результат
7в
Для преобразования второго сомножителя преобразуем сначала последнее выражение
И подставим этот результат

7г
Поскольку, как было показано ранее, коэффициент b может быть представлен в
7г
Поскольку, как было показано ранее, коэффициент b может быть представлен в

8
Величина QR дает сумму квадратов отклонений, объясненной моделью (Regression sum
8
Величина QR дает сумму квадратов отклонений, объясненной моделью (Regression sum

8а
Очевидно, что если QR >> QE , то уравнение регрессии
8а
Очевидно, что если QR >> QE , то уравнение регрессии

8б
Напомним, что для получения несмещенной оценки дисперсии, сумму квадратов отклонений от
8б
Напомним, что для получения несмещенной оценки дисперсии, сумму квадратов отклонений от
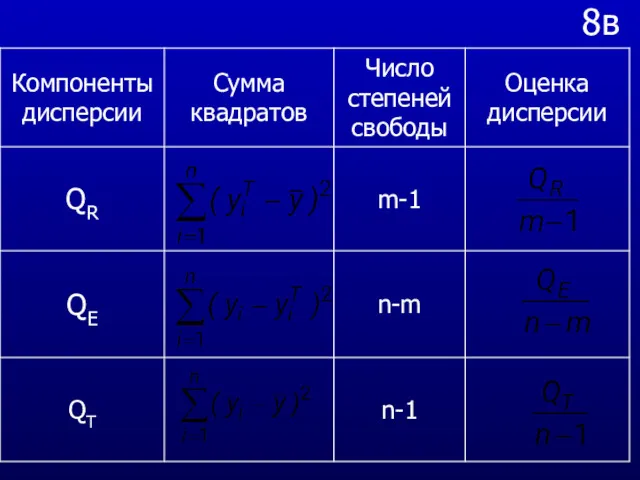
8в
8в

9
Рассмотрим две оценки дисперсии
где m число параметров в уравнении регрессии,
9
Рассмотрим две оценки дисперсии
где m число параметров в уравнении регрессии,

10
Задача. Используя приведенные данные оценить значимость линейной модели связи расходов на
10
Задача. Используя приведенные данные оценить значимость линейной модели связи расходов на

11
Линейное регрессионное уравнение было получено ранее и имеет вид
Используя
11
Линейное регрессионное уравнение было получено ранее и имеет вид
Используя

12
Величина F подчиняется распределению Фишера –Снедекора для K1=1, K2=4.
Используя функцию
12
Величина F подчиняется распределению Фишера –Снедекора для K1=1, K2=4.
Используя функцию
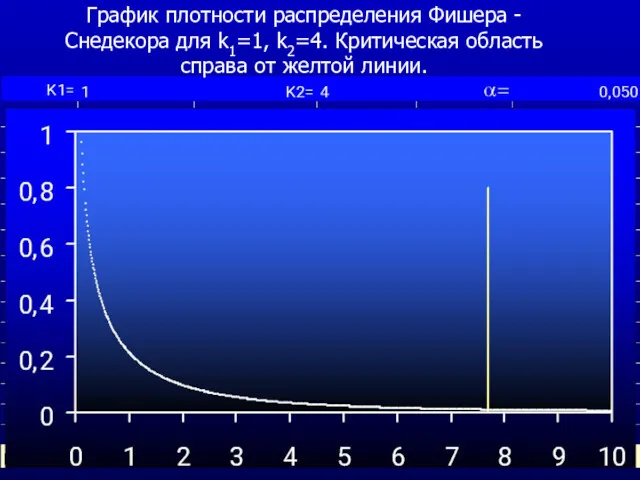
График плотности распределения Фишера -Снедекора для k1=1, k2=4. Критическая область справа
График плотности распределения Фишера -Снедекора для k1=1, k2=4. Критическая область справа

13а
Для проверки значимости линейного уравнения регрессии можно использовать и функцию
13а
Для проверки значимости линейного уравнения регрессии можно использовать и функцию

13 б
Задача
Имеются следующие данные об общем объеме розничного товарооборота региона
13 б
Задача
Имеются следующие данные об общем объеме розничного товарооборота региона
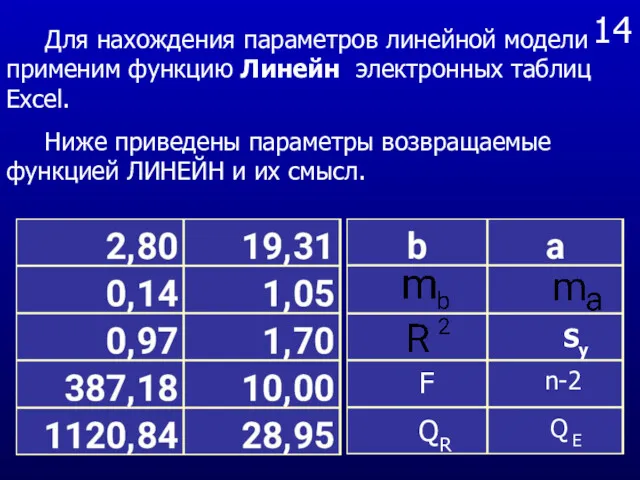
14
Sy
F
n-2
QR
Q E
Для нахождения параметров линейной модели применим функцию Линейн электронных
14
Sy
F
n-2
QR
Q E
Для нахождения параметров линейной модели применим функцию Линейн электронных

15
Для оценки значимости регрессионной модели найдем критическую точку распределения Фишера
15
Для оценки значимости регрессионной модели найдем критическую точку распределения Фишера

16
Как уже указывалось, одной из наиболее эффективных оценок адекватности регрессионных
16
Как уже указывалось, одной из наиболее эффективных оценок адекватности регрессионных

17
Действительно, вспоминая уравнение для определения коэффициента а и регрессионное уравнение
Подставляя последний
17
Действительно, вспоминая уравнение для определения коэффициента а и регрессионное уравнение
Подставляя последний
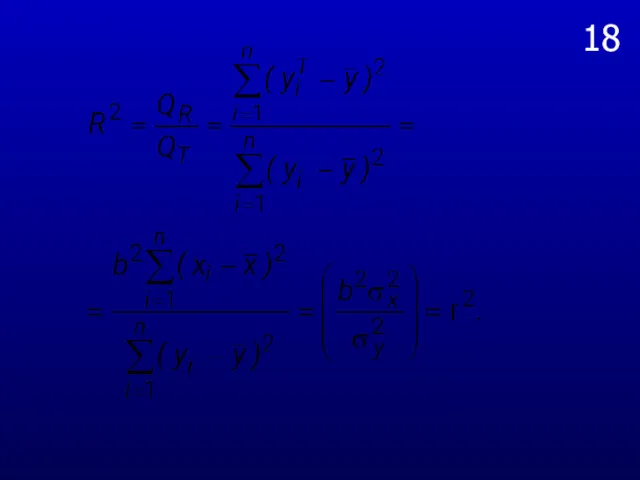
18
18

19
Следует заметить, что оценка качества регрессионного уравнения с помощью критерия
19
Следует заметить, что оценка качества регрессионного уравнения с помощью критерия

3. 2. Проверка значимости коэффициентов регрессии
Интервальная оценка для коэффициентов регрессии и
3. 2. Проверка значимости коэффициентов регрессии
Интервальная оценка для коэффициентов регрессии и

1
В линейной регрессии обычно оценивается значимость не только уравнения в целом,
1
В линейной регрессии обычно оценивается значимость не только уравнения в целом,

2
В условиях справедливости выдвинутой гипотезы случайные величины tb и ta
2
В условиях справедливости выдвинутой гипотезы случайные величины tb и ta

3
Для нахождения mb найдем дисперсию коэффициента b. Для этого используем запись
3
Для нахождения mb найдем дисперсию коэффициента b. Для этого используем запись

4
Оценим дисперсию используя формулу остаточной дисперсии. В условиях справедливости выдвигаемой
4
Оценим дисперсию используя формулу остаточной дисперсии. В условиях справедливости выдвигаемой

5
В итоге получаем среднеквадратическое отклонение (ошибку) для коэффициента b в
5
В итоге получаем среднеквадратическое отклонение (ошибку) для коэффициента b в

6
интервальная оценка коэффициента при заданном уровне значимости (tкрит) определяется стандартными
6
интервальная оценка коэффициента при заданном уровне значимости (tкрит) определяется стандартными

6а
После такого преобразования коэффициента а, можно вычислить его дисперсию. Введем обозначение
6а
После такого преобразования коэффициента а, можно вычислить его дисперсию. Введем обозначение

6б
Учитывая, что дисперсия суммы равна сумме дисперсий, а также то,
6б
Учитывая, что дисперсия суммы равна сумме дисперсий, а также то,

7
Оценка значимости и расчет доверительного интервала при заданном уровне значимости,
7
Оценка значимости и расчет доверительного интервала при заданном уровне значимости,

8
Используя электронные таблицы Excel можно избежать утомительных вычислений, поскольку функция
8
Используя электронные таблицы Excel можно избежать утомительных вычислений, поскольку функция

9
Построим доверительный интервал для функции регрессии т. е. интервал значений
9
Построим доверительный интервал для функции регрессии т. е. интервал значений

10
Найдем среднеквадратическое отклонение для предсказываемых моделью значений yT
Дисперсия среднего значения факторной
10
Найдем среднеквадратическое отклонение для предсказываемых моделью значений yT
Дисперсия среднего значения факторной

11
Дисперсия коэффициента b вычислялась ранее и равна
учитывая два последних результата,
11
Дисперсия коэффициента b вычислялась ранее и равна
учитывая два последних результата,

12
В качестве оценки для дисперсии результативного признака снова возьмем величину
12
В качестве оценки для дисперсии результативного признака снова возьмем величину

13
Поскольку случайная величина
подчиняется распределению Стьюдента с числом степеней свободы k=n-2, то
13
Поскольку случайная величина
подчиняется распределению Стьюдента с числом степеней свободы k=n-2, то
 Делимость суммы и разности чисел. Урок 102
Делимость суммы и разности чисел. Урок 102 Загальні відомості про дослідження операцій
Загальні відомості про дослідження операцій Точечные и интервальные оценки неизвестных параметров распределения
Точечные и интервальные оценки неизвестных параметров распределения Теория комплексных чисел. (Тема 2)
Теория комплексных чисел. (Тема 2) Неделя математики
Неделя математики Неопределенный интеграл
Неопределенный интеграл Истоки математики. Пифагор
Истоки математики. Пифагор Итоговый тест за курс начальной школы
Итоговый тест за курс начальной школы Принцип Дирихле
Принцип Дирихле Трапеція. Означення, властивості та види трапецій. Розв’язування задач. 8 класс
Трапеція. Означення, властивості та види трапецій. Розв’язування задач. 8 класс Презентация у уроку математики во 2 классе по теме Свойство противоположных сторон прямоугольника
Презентация у уроку математики во 2 классе по теме Свойство противоположных сторон прямоугольника Призма. Решение задач
Призма. Решение задач Первый признак равенства треугольников
Первый признак равенства треугольников Вероятность и статистика. Урок 2. 7 класс
Вероятность и статистика. Урок 2. 7 класс Математическая интерактивная игра Кем быть?.
Математическая интерактивная игра Кем быть?. Определённый интеграл. Вычисление площади криволинейной трапеции
Определённый интеграл. Вычисление площади криволинейной трапеции Правильная четырехугольная пирамида. Задачи
Правильная четырехугольная пирамида. Задачи Краткий запись задач 1 клас
Краткий запись задач 1 клас Общая теория. Графики. Тренажер
Общая теория. Графики. Тренажер Решение заданий В8 (часть 2) по материалам открытого банка задач ЕГЭ по математике
Решение заданий В8 (часть 2) по материалам открытого банка задач ЕГЭ по математике Построить проекции замкнутой ломаной линии ABCD, выполнив требования. (задача 19)
Построить проекции замкнутой ломаной линии ABCD, выполнив требования. (задача 19) Эллипс
Эллипс Делители и кратные. 6 класс
Делители и кратные. 6 класс Арифметичні дії з іменованими числами математика
Арифметичні дії з іменованими числами математика Методическая разработка к уроку математики для 2 класса. Тема: Сложение однозначных чисел с переходом через разряд
Методическая разработка к уроку математики для 2 класса. Тема: Сложение однозначных чисел с переходом через разряд Сложение и умножение вероятностей
Сложение и умножение вероятностей Медианы, биссектрисы и высоты треугольника
Медианы, биссектрисы и высоты треугольника Объем конуса
Объем конуса