- Многоуровневый и многофакторный анализ неметрических данных в СПСС: новые процедуры

Содержание
- 2. Новые процедуры – новые возможности Дефицитарность процедур ДА в рамках общей линейной модели. Анализ многоуровневых данных.
- 3. Новые подходы и термины MLM - многоуровневое моделирование: подход к статистической обработке данных, имеющих вложенную или
- 4. Новые подходы и термины В СПСС «Смешанными моделями» называются модели, включающие фиксированные и случайные эффекты. Фактически,
- 5. Новые подходы и термины The generalized linear model expands the general linear model so that the
- 6. Функция связи – это способ преобразования ЗП, позволяющей ее оценить с помощью линейной модели. Например: Identity.
- 7. Обработка одноуровневых моделей Процедура GENLIN – Обобщенные линейные модели. Предполагается, что испытуемые случайно выбраны из одной
- 8. Обработка одноуровневых моделей 3. Предикторы и Модель: 1) включение предикторов и эффектов их взаимодействия; 2) смещение
- 9. Результаты (файл: сh3data.sav) Статистики согласияa Значение ст.св. Значение/ст.св. Уклонение 5,191 1 5,191 Масштабированное уклонение 5,191 1
- 10. Результаты 1. Общий критерийa Хи-квадрат отношения правдоподобия ст.св. Знч. 408,781 2 ,000 Зависимая переменная: Умение читать
- 11. Результаты Оценки параметров Параметр B Стд. Ошибка Проверка гипотезы Exp(B) Exp(B) (Константа) 1b ,0466 ,000 1,738
- 12. Обобщенные уравнения оценки Это расширение Обобщенной линейной модели на данные, включающие повторные измерения на одних и
- 13. Установки и опции Вкладка Повтор: указываем: а) переменную, соответствующую испытуемым (subjects variables, групповые переменные), т.е. ту
- 14. Установки и опции Тип рабочей корреляционной матрицы, описывающей структуры повторных измерений ЗП. Заранее сложно предугадать оптимальную
- 15. Пример: ch5data1.sav Нужно оценить, как изменялась в течение года: Динамика успешности чтения в целом (время -
- 17. Скачать презентацию

Новые процедуры – новые возможности
Дефицитарность процедур ДА в рамках общей линейной
Новые процедуры – новые возможности
Дефицитарность процедур ДА в рамках общей линейной

Новые подходы и термины
MLM - многоуровневое моделирование: подход к статистической обработке
Новые подходы и термины
MLM - многоуровневое моделирование: подход к статистической обработке

Новые подходы и термины
В СПСС «Смешанными моделями» называются модели, включающие фиксированные
Новые подходы и термины
В СПСС «Смешанными моделями» называются модели, включающие фиксированные

Новые подходы и термины
The generalized linear model expands the general linear
Новые подходы и термины
The generalized linear model expands the general linear

Функция связи – это способ преобразования ЗП, позволяющей ее оценить с
Функция связи – это способ преобразования ЗП, позволяющей ее оценить с

Обработка одноуровневых моделей
Процедура GENLIN – Обобщенные линейные модели.
Предполагается, что испытуемые случайно
Обработка одноуровневых моделей
Процедура GENLIN – Обобщенные линейные модели.
Предполагается, что испытуемые случайно

Обработка одноуровневых моделей
3. Предикторы и Модель: 1) включение предикторов и эффектов
Обработка одноуровневых моделей
3. Предикторы и Модель: 1) включение предикторов и эффектов

Результаты (файл: сh3data.sav)
Статистики согласияa
Значение ст.св. Значение/ст.св.
Уклонение 5,191 1 5,191
Масштабированное уклонение 5,191 1
Хи-квадрат Пирсона 5,175 1 5,175
Масштабированное значение хи-квадрат Пирсона 5,175 1
Log-правдоподобиеb -3833,346
Информационный критерий Акаике
Результаты (файл: сh3data.sav)
Статистики согласияa
Значение ст.св. Значение/ст.св.
Уклонение 5,191 1 5,191
Масштабированное уклонение 5,191 1
Хи-квадрат Пирсона 5,175 1 5,175
Масштабированное значение хи-квадрат Пирсона 5,175 1
Log-правдоподобиеb -3833,346
Информационный критерий Акаике

Результаты
1. Общий критерийa
Хи-квадрат отношения правдоподобия ст.св. Знч.
408,781 2 ,000
Зависимая переменная: Умение читать
Модель: (Константа), female, minor
Сравнивает
Результаты
1. Общий критерийa
Хи-квадрат отношения правдоподобия ст.св. Знч.
408,781 2 ,000
Зависимая переменная: Умение читать
Модель: (Константа), female, minor
Сравнивает
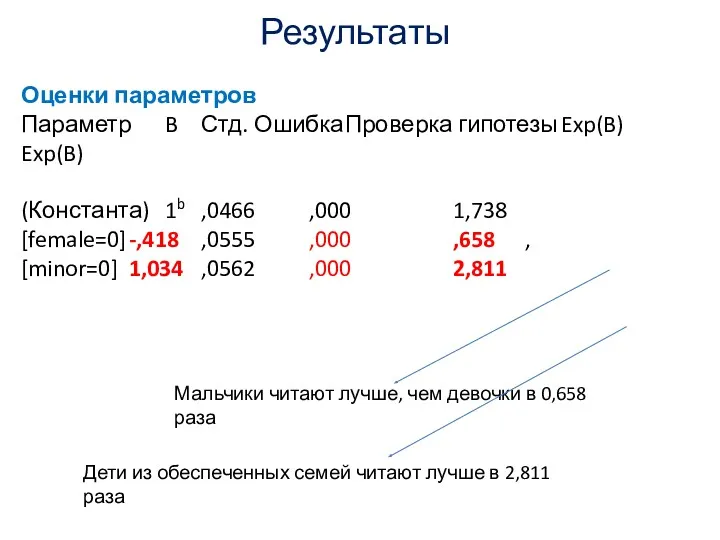
Результаты
Оценки параметров
Параметр B Стд. Ошибка Проверка гипотезы Exp(B) Exp(B)
(Константа) 1b ,0466 ,000 1,738
[female=0] -,418 ,0555 ,000 ,658 ,
[minor=0] 1,034 ,0562 ,000 2,811
Мальчики читают лучше, чем девочки в
Результаты
Оценки параметров
Параметр B Стд. Ошибка Проверка гипотезы Exp(B) Exp(B)
(Константа) 1b ,0466 ,000 1,738
[female=0] -,418 ,0555 ,000 ,658 ,
[minor=0] 1,034 ,0562 ,000 2,811
Мальчики читают лучше, чем девочки в

Обобщенные уравнения оценки
Это расширение Обобщенной линейной модели на данные, включающие повторные
Обобщенные уравнения оценки
Это расширение Обобщенной линейной модели на данные, включающие повторные

Установки и опции
Вкладка Повтор: указываем: а) переменную, соответствующую испытуемым (subjects variables,
Установки и опции
Вкладка Повтор: указываем: а) переменную, соответствующую испытуемым (subjects variables,

Установки и опции
Тип рабочей корреляционной матрицы, описывающей структуры повторных измерений ЗП.
Установки и опции
Тип рабочей корреляционной матрицы, описывающей структуры повторных измерений ЗП.

Пример: ch5data1.sav
Нужно оценить, как изменялась в течение года:
Динамика успешности чтения в
Пример: ch5data1.sav
Нужно оценить, как изменялась в течение года:
Динамика успешности чтения в
 Оценка точности при параметрическом способе уравнивания
Оценка точности при параметрическом способе уравнивания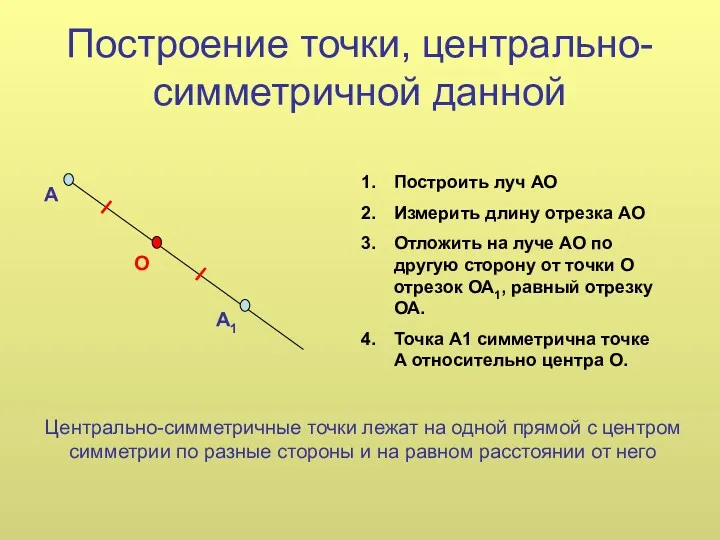 Построение точки, центрально-симметричной данной
Построение точки, центрально-симметричной данной Тест по теме: Признаки равенства треугольника
Тест по теме: Признаки равенства треугольника Вычисление количеств по процентам
Вычисление количеств по процентам Урок математики по теме: Умножение и деление на 3.
Урок математики по теме: Умножение и деление на 3. Прогрессии в нашей жизни
Прогрессии в нашей жизни Клуб весёлых математиков. 5 класс
Клуб весёлых математиков. 5 класс Значения тригонометрических функций
Значения тригонометрических функций Решение нестандартных уравнений
Решение нестандартных уравнений Действия с десятичными дробями
Действия с десятичными дробями Презентация к уроку математики Текстовые задачи, 3 класс
Презентация к уроку математики Текстовые задачи, 3 класс Измерение углов
Измерение углов Сложение и вычитание десятков
Сложение и вычитание десятков Фракталы в музыке
Фракталы в музыке Презентация к уроку математики
Презентация к уроку математики Сложение и вычитание в пределах 10
Сложение и вычитание в пределах 10 Архимед. Открытия Архимеда
Архимед. Открытия Архимеда Теория погрешностей
Теория погрешностей Числовые промежутки
Числовые промежутки Решение простейших тригонометрических уравнений - 1
Решение простейших тригонометрических уравнений - 1 Реализация алгоритма ветвления на QBASIC
Реализация алгоритма ветвления на QBASIC Задачи с величинами: цена, количество, стоимость
Задачи с величинами: цена, количество, стоимость Оценка устойчивости замкнутого контура САР по критерию Михайлова с помощью программы Exsel
Оценка устойчивости замкнутого контура САР по критерию Михайлова с помощью программы Exsel Деление многозначных чисел
Деление многозначных чисел Увеличение и уменьшение чисел в 10 и в 100 раз
Увеличение и уменьшение чисел в 10 и в 100 раз сложение и вычитание десятичных дробей. Путешествие в сказку. 5 класс
сложение и вычитание десятичных дробей. Путешествие в сказку. 5 класс Все действия с дробями. Урок математики в 5 классе
Все действия с дробями. Урок математики в 5 классе Решение заданий В8 по материалам открытого банка задач ЕГЭ по математике
Решение заданий В8 по материалам открытого банка задач ЕГЭ по математике