- In Search of an Understandable Consensus Algorithm

Содержание
- 2. Motivation (I) "Consensus algorithms allow a collection of machines to work as a coherent group that
- 3. Motivation (II) Paxos Current standard for both teaching and implementing consensus algorithms Very difficult to understand
- 4. Key features of Raft Strong leader: Leader does most of the work: Issues all log updates
- 5. Replicated state machines Allows a collection of servers to Maintain identical copies of the same data
- 6. The distributed log (I) Each server stores a log containing commands Consensus algorithm ensures that all
- 7. The distributed log (II)
- 8. The distributed log (III) Client sends a command to one of the servers Server adds the
- 9. Consensus algorithms (I) Typically satisfy the following properties Safety: Never return an incorrect result under all
- 10. Two types of failures Non-Byzantine Failed nodes stop communicating with other nodes "Clean" failure Fail-stop behavior
- 11. Consensus algorithms (II) Robustness: Do not depend on timing to ensure the consistency of the logs
- 12. Paxos limitations (I) Exceptionally difficult to understand “The dirty little secret of the NSDI* community is
- 13. Paxos limitations (II) Very difficult to implement “There are significant gaps between the description of the
- 14. Designing for understandability Main objective of RAFT Whenever possible, select the alternative that is the easiest
- 15. Problem decomposition Old technique René Descartes' third rule for avoiding fallacies: The third, to conduct my
- 16. Raft consensus algorithm (I) Servers start by electing a leader Sole server habilitated to accept commands
- 17. Raft consensus algorithm (II) Decomposes the problem into three fairly independent subproblems Leader election: How servers
- 18. Raft basics: the servers A RAFT cluster consists of several servers Typically five Each server can
- 19. Server states
- 20. Raft basics: terms (I) Epochs of arbitrary length Start with the election of a leader End
- 21. Raft basics: terms (II)
- 22. Raft basics: terms (III) Terms act as logical clocks Allow servers to detect and discard obsolete
- 23. Raft basics: RPC Servers communicate though idempotent RPCs RequestVote Initiated by candidates during elections AppendEntry Initiated
- 24. Leader elections Servers start being followers Remain followers as long as they receive valid RPCs from
- 25. The leader fails Followers notice at different times the lack of heartbeats Decide to elect a
- 26. Starting an election When a follower starts an election, it Increments its current term Transitions to
- 27. Acting as a candidate A candidate remains in that state until It wins the election Another
- 28. Winning an election Must receive votes from a majority of the servers in the cluster for
- 29. Hearing from other servers Candidates may receive an AppendEntries RPC from another server claiming to be
- 30. Split elections No candidate obtains a majority of the votes in the servers in the cluster
- 31. Avoiding split elections Raft uses randomized election timeouts Chosen randomly from a fixed interval Increases the
- 32. Example Follower A Follower B Leader Last heartbeat X Timeouts Follower with the shortest timeout becomes
- 33. Log replication Leaders Accept client commands Append them to their log (new entry) Issue AppendEntry RPCs
- 34. A client sends a request Leader stores request on its log and forwards it to its
- 35. The followers receive the request Followers store the request on their logs and acknowledge its receipt
- 36. The leader tallies followers' ACKs Once it ascertains the request has been processed by a majority
- 37. The leader tallies followers' ACKs Leader's heartbeats convey the news to its followers: they update their
- 38. Log organization Colors identify terms
- 39. Handling slow followers ,… Leader reissues the AppendEntry RPC They are idempotent
- 40. Committed entries Guaranteed to be both Durable Eventually executed by all the available state machine Committing
- 41. Why? Raft commits entries in strictly sequential order Requires followers to accept log entry appends in
- 42. Raft log matching property If two entries in different logs have the same index and term
- 43. Handling leader crashes (I) Can leave the cluster in a inconsistent state if the old leader
- 44. Handling leader crashes (II) (new term)
- 45. An election starts Candidate for leader position requests votes of other former followers Includes a summary
- 46. Former followers reply Former followers compare the state of their logs with credentials of candidate Vote
- 47. Handling leader crashes (III) Raft solution is to let the new leader to force followers' log
- 48. The new leader is in charge Newly elected candidate forces all its followers to duplicate in
- 49. How? (I) Leader maintains a nextIndex for each follower Index of entry it will send to
- 50. How? (II) Followers that have missed some AppendEntry calls will refuse all further AppendEntry calls Leader
- 51. How? (III) By successive trials and errors, leader finds out that the first log entry that
- 52. Interesting question How will the leader know which log entries it can commit Cannot always gather
- 53. A last observation Handling log inconsistencies does not require a special sub algorithm Rolling back EntryAppend
- 54. Safety Two main issues What if the log of a new leader did not contain all
- 55. Election restriction (I) The log of any new leader must contain all previously committed entries Candidates
- 56. Election restriction (II) Servers holding the last committed log entry Servers having elected the new leader
- 57. Committing entries from a previous term A leader cannot immediately conclude that an entry from a
- 58. Committing entries from a previous term
- 59. Explanations In (a) S1 is leader and partially replicates the log entry at index 2. In
- 60. Explanations If S1 crashes as in (d), S5 could be elected leader (with votes from S2,
- 61. Cluster membership changes Not possible to do an atomic switch Changing the membership of all servers
- 62. The joint consensus configuration Log entries are transmitted to all servers, old and new Any server
- 63. The joint consensus configuration
- 64. Implementations Two thousand lines of C++ code, not including tests, comments, or blank lines. About 25
- 65. Understandability See paper
- 66. Correctness A proof of safety exists
- 67. Performance See paper
- 69. Скачать презентацию

Motivation (I)
"Consensus algorithms allow a collection of machines to work as
Motivation (I)
"Consensus algorithms allow a collection of machines to work as

Motivation (II)
Paxos
Current standard for both teaching and implementing consensus algorithms
Very
Motivation (II)
Paxos
Current standard for both teaching and implementing consensus algorithms
Very

Key features of Raft
Strong leader:
Leader does most of the work:
Issues all
Key features of Raft
Strong leader:
Leader does most of the work:
Issues all

Replicated state machines
Allows a collection of servers to
Maintain identical copies of
Replicated state machines
Allows a collection of servers to
Maintain identical copies of

The distributed log (I)
Each server stores a log containing commands
Consensus algorithm
The distributed log (I)
Each server stores a log containing commands
Consensus algorithm
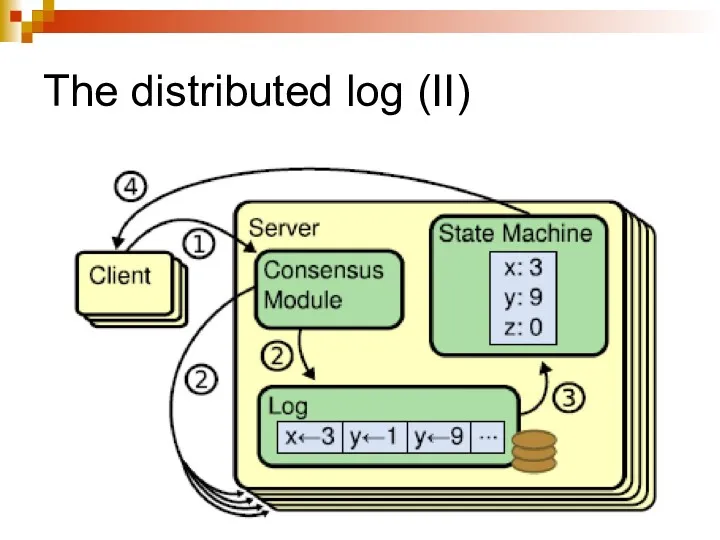
The distributed log (II)
The distributed log (II)

The distributed log (III)
Client sends a command to one of the
The distributed log (III)
Client sends a command to one of the

Consensus algorithms (I)
Typically satisfy the following properties
Safety:
Never return an incorrect result
Consensus algorithms (I)
Typically satisfy the following properties
Safety:
Never return an incorrect result

Two types of failures
Non-Byzantine
Failed nodes stop communicating with other nodes
"Clean" failure
Fail-stop
Two types of failures
Non-Byzantine
Failed nodes stop communicating with other nodes
"Clean" failure
Fail-stop

Consensus algorithms (II)
Robustness:
Do not depend on timing to ensure the
Consensus algorithms (II)
Robustness:
Do not depend on timing to ensure the

Paxos limitations (I)
Exceptionally difficult to understand
“The dirty little secret of the
Paxos limitations (I)
Exceptionally difficult to understand
“The dirty little secret of the

Paxos limitations (II)
Very difficult to implement
“There are significant gaps between the
Paxos limitations (II)
Very difficult to implement
“There are significant gaps between the

Designing for understandability
Main objective of RAFT
Whenever possible, select the alternative that
Designing for understandability
Main objective of RAFT
Whenever possible, select the alternative that

Problem decomposition
Old technique
René Descartes' third rule for avoiding fallacies:
The third, to
Problem decomposition
Old technique
René Descartes' third rule for avoiding fallacies:
The third, to

Raft consensus algorithm (I)
Servers start by electing a leader
Sole server habilitated
Raft consensus algorithm (I)
Servers start by electing a leader
Sole server habilitated

Raft consensus algorithm (II)
Decomposes the problem into three fairly independent subproblems
Leader
Raft consensus algorithm (II)
Decomposes the problem into three fairly independent subproblems
Leader

Raft basics: the servers
A RAFT cluster consists of several servers
Typically five
Each
Raft basics: the servers
A RAFT cluster consists of several servers
Typically five
Each
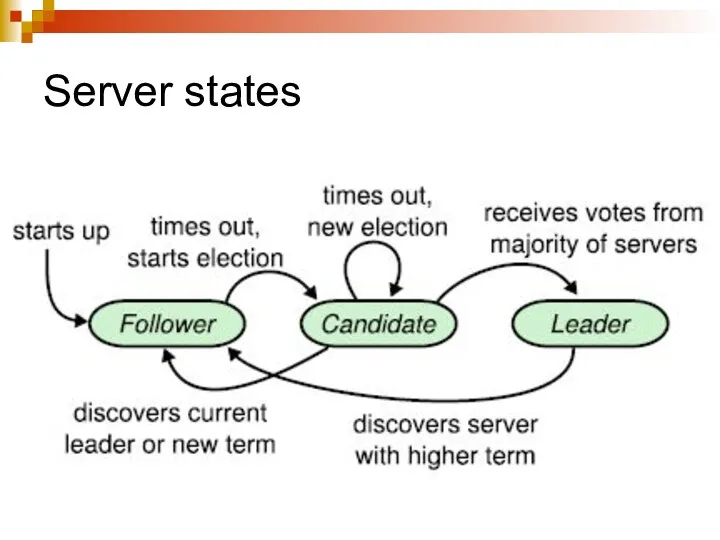
Server states
Server states

Raft basics: terms (I)
Epochs of arbitrary length
Start with the election of
Raft basics: terms (I)
Epochs of arbitrary length
Start with the election of
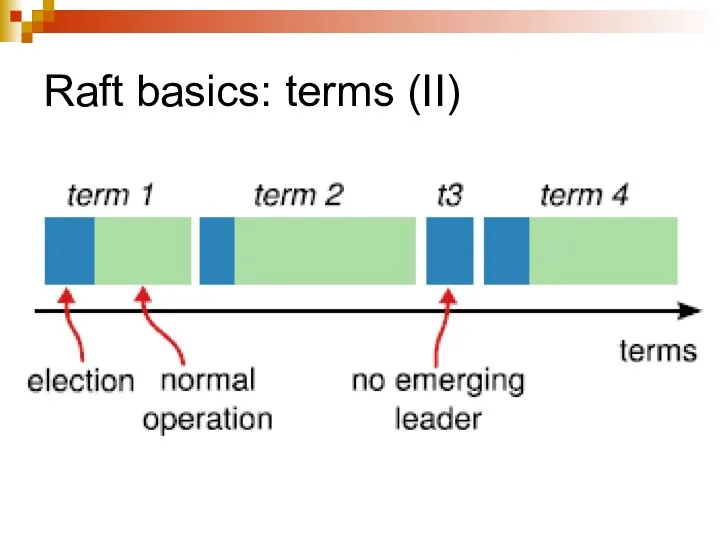
Raft basics: terms (II)
Raft basics: terms (II)

Raft basics: terms (III)
Terms act as logical clocks
Allow servers to detect
Raft basics: terms (III)
Terms act as logical clocks
Allow servers to detect

Raft basics: RPC
Servers communicate though idempotent RPCs
RequestVote
Initiated by candidates during elections
Raft basics: RPC
Servers communicate though idempotent RPCs
RequestVote
Initiated by candidates during elections

Leader elections
Servers start being followers
Remain followers as long as they receive
Leader elections
Servers start being followers
Remain followers as long as they receive
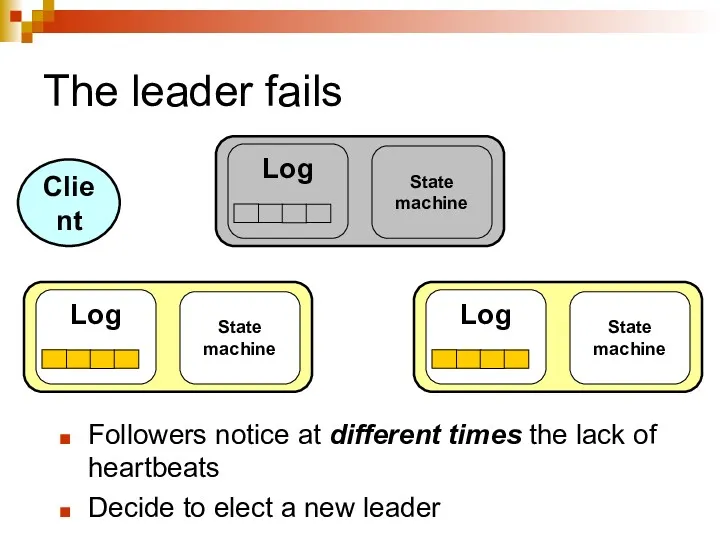
The leader fails
Followers notice at different times the lack of heartbeats
Decide
The leader fails
Followers notice at different times the lack of heartbeats
Decide

Starting an election
When a follower starts an election, it
Increments its current
Starting an election
When a follower starts an election, it
Increments its current

Acting as a candidate
A candidate remains in that state until
It wins
Acting as a candidate
A candidate remains in that state until
It wins

Winning an election
Must receive votes from a majority of the servers
Winning an election
Must receive votes from a majority of the servers

Hearing from other servers
Candidates may receive an AppendEntries RPC from another
Hearing from other servers
Candidates may receive an AppendEntries RPC from another

Split elections
No candidate obtains a majority of the votes in the
Split elections
No candidate obtains a majority of the votes in the

Avoiding split elections
Raft uses randomized election timeouts
Chosen randomly from a fixed
Avoiding split elections
Raft uses randomized election timeouts
Chosen randomly from a fixed
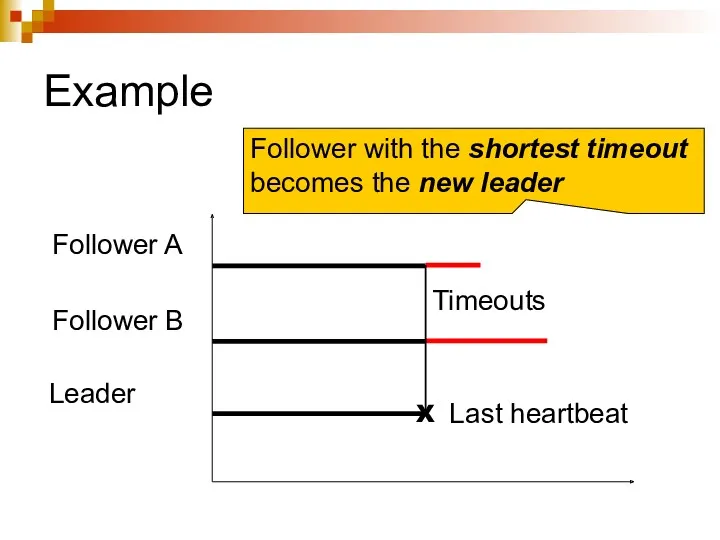
Example
Follower A
Follower B
Leader
Last heartbeat
X
Timeouts
Follower with the shortest timeout
becomes the new leader
Example
Follower A
Follower B
Leader
Last heartbeat
X
Timeouts
Follower with the shortest timeout
becomes the new leader

Log replication
Leaders
Accept client commands
Append them to their log (new entry)
Issue
Log replication
Leaders
Accept client commands
Append them to their log (new entry)
Issue
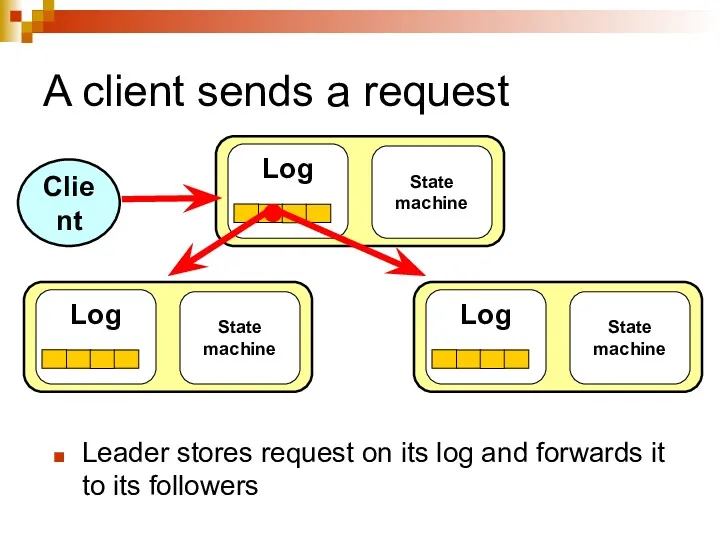
A client sends a request
Leader stores request on its log and
A client sends a request
Leader stores request on its log and
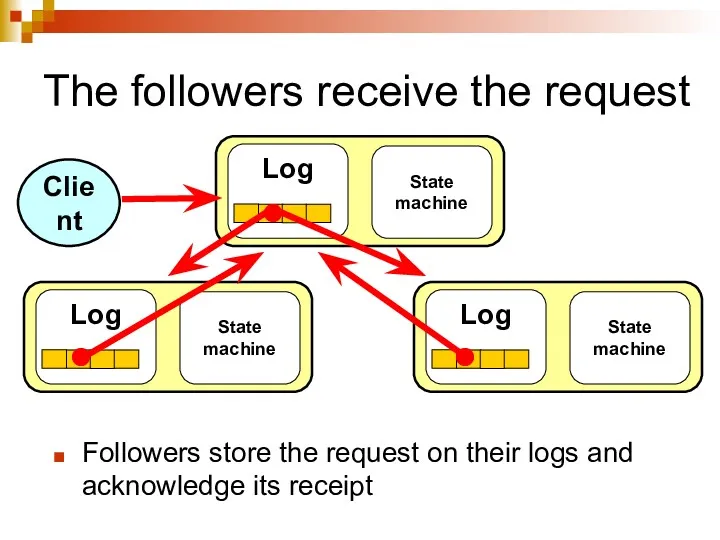
The followers receive the request
Followers store the request on their logs
The followers receive the request
Followers store the request on their logs
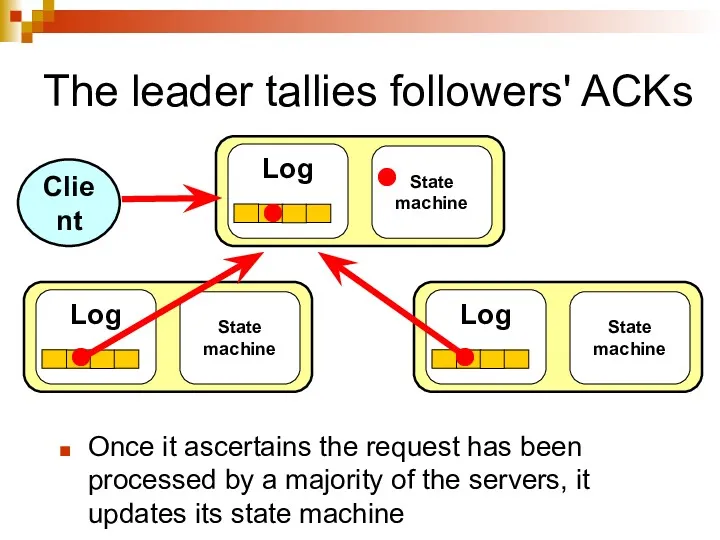
The leader tallies followers' ACKs
Once it ascertains the request has been
The leader tallies followers' ACKs
Once it ascertains the request has been
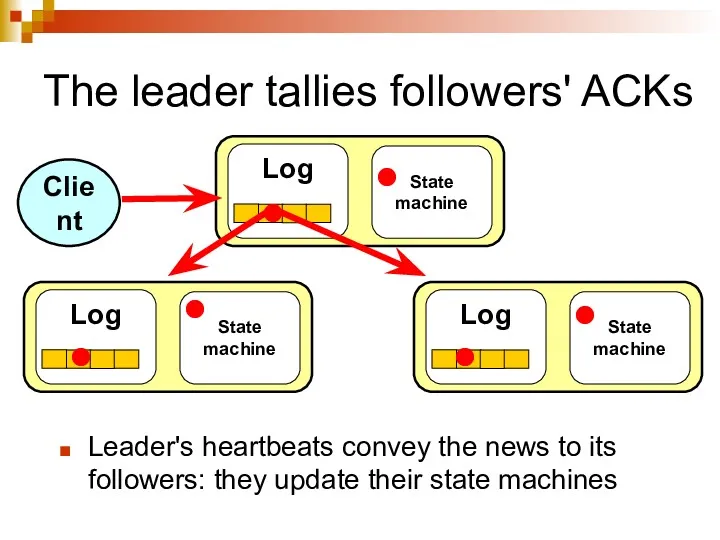
The leader tallies followers' ACKs
Leader's heartbeats convey the news to its
The leader tallies followers' ACKs
Leader's heartbeats convey the news to its
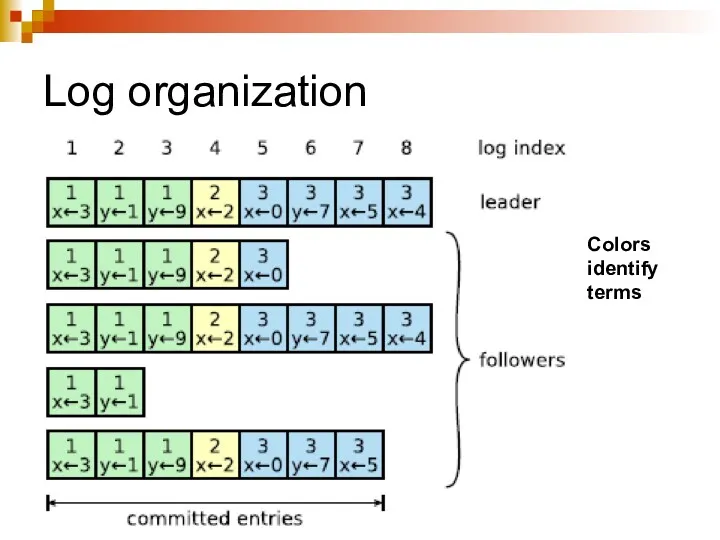
Log organization
Colors
identify
terms
Log organization
Colors
identify
terms

Handling slow followers ,…
Leader reissues the AppendEntry RPC
They are idempotent
Handling slow followers ,…
Leader reissues the AppendEntry RPC
They are idempotent

Committed entries
Guaranteed to be both
Durable
Eventually executed by all the available state
Committed entries
Guaranteed to be both
Durable
Eventually executed by all the available state

Why?
Raft commits entries in strictly sequential order
Requires followers to accept log
Why?
Raft commits entries in strictly sequential order
Requires followers to accept log

Raft log matching property
If two entries in different logs have the
Raft log matching property
If two entries in different logs have the

Handling leader crashes (I)
Can leave the cluster in a inconsistent state
Handling leader crashes (I)
Can leave the cluster in a inconsistent state
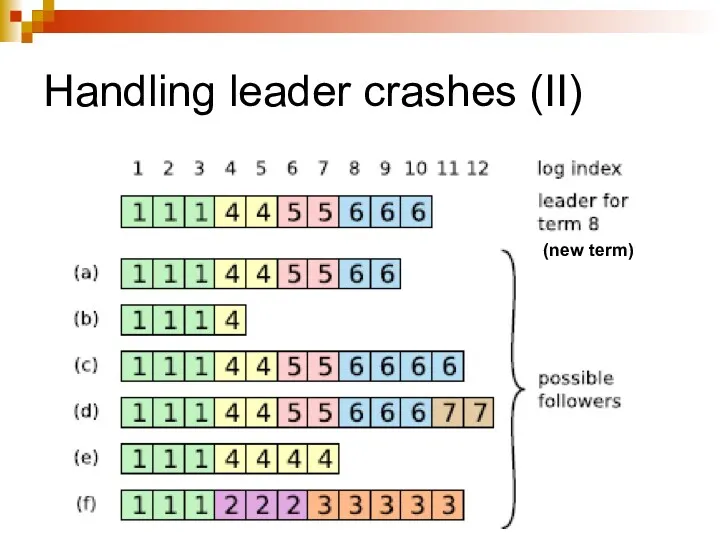
Handling leader crashes (II)
(new term)
Handling leader crashes (II)
(new term)
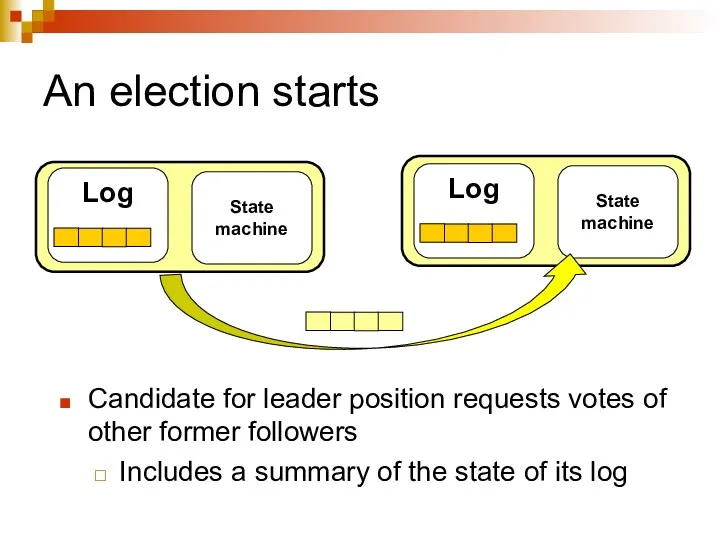
An election starts
Candidate for leader position requests votes of other
An election starts
Candidate for leader position requests votes of other
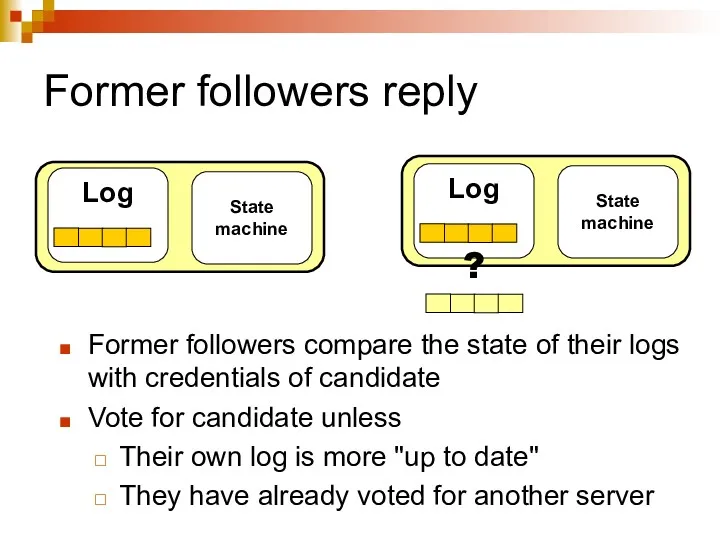
Former followers reply
Former followers compare the state of their logs with
Former followers reply
Former followers compare the state of their logs with

Handling leader crashes (III)
Raft solution is to let the new leader
Handling leader crashes (III)
Raft solution is to let the new leader
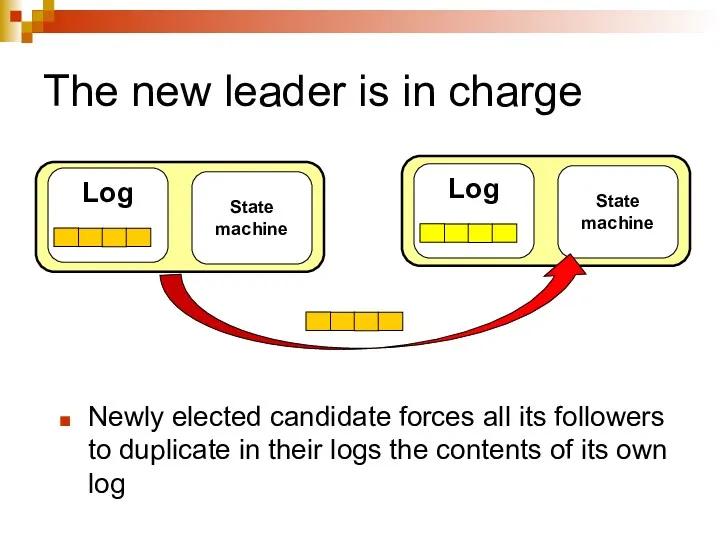
The new leader is in charge
Newly elected candidate forces all its
The new leader is in charge
Newly elected candidate forces all its

How? (I)
Leader maintains a nextIndex for each follower
Index of entry it
How? (I)
Leader maintains a nextIndex for each follower
Index of entry it

How? (II)
Followers that have missed some AppendEntry calls will refuse all
How? (II)
Followers that have missed some AppendEntry calls will refuse all

How? (III)
By successive trials and errors, leader finds out that the
How? (III)
By successive trials and errors, leader finds out that the

Interesting question
How will the leader know which log entries it can
Interesting question
How will the leader know which log entries it can

A last observation
Handling log inconsistencies does not require a special sub
A last observation
Handling log inconsistencies does not require a special sub

Safety
Two main issues
What if the log of a new leader did
Safety
Two main issues
What if the log of a new leader did

Election restriction (I)
The log of any new leader must contain all
Election restriction (I)
The log of any new leader must contain all
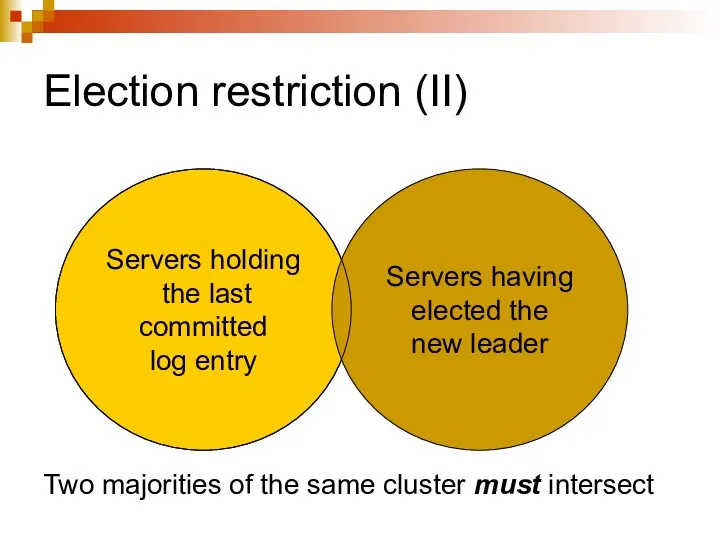
Election restriction (II)
Servers holding
the last committed
log entry
Servers having
elected the
new
Election restriction (II)
Servers holding
the last committed
log entry
Servers having
elected the
new

Committing entries from a previous term
A leader cannot immediately conclude that
Committing entries from a previous term
A leader cannot immediately conclude that
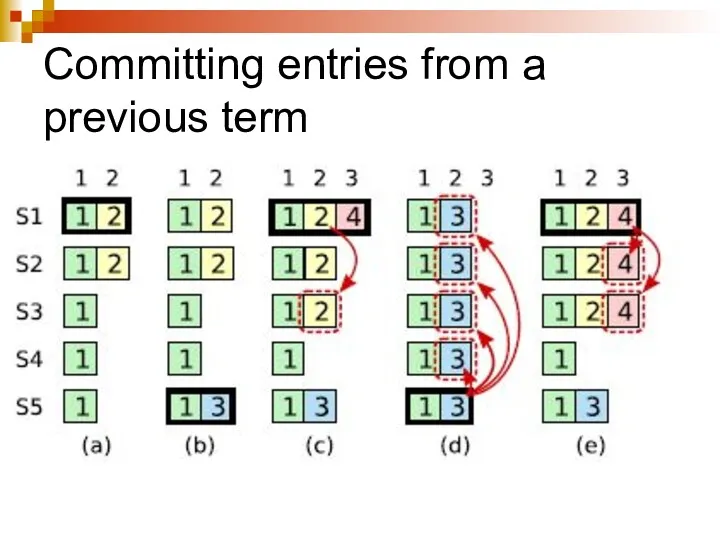
Committing entries from a previous term
Committing entries from a previous term

Explanations
In (a) S1 is leader and partially replicates the log entry
Explanations
In (a) S1 is leader and partially replicates the log entry

Explanations
If S1 crashes as in (d), S5 could be elected leader
Explanations
If S1 crashes as in (d), S5 could be elected leader

Cluster membership changes
Not possible to do an atomic switch
Changing the membership
Cluster membership changes
Not possible to do an atomic switch
Changing the membership

The joint consensus configuration
Log entries are transmitted to all servers, old
The joint consensus configuration
Log entries are transmitted to all servers, old

The joint consensus configuration
The joint consensus configuration

Implementations
Two thousand lines of C++ code, not including tests, comments, or
Implementations
Two thousand lines of C++ code, not including tests, comments, or

Understandability
See paper
Understandability
See paper

Correctness
A proof of safety exists
Correctness
A proof of safety exists

Performance
See paper
Performance
See paper
 Необходимость управления. Определение управления. Уровни управления
Необходимость управления. Определение управления. Уровни управления Понятие и классификация проектов. Управление проектами
Понятие и классификация проектов. Управление проектами Основы бережливого производства
Основы бережливого производства Управление качеством проекта. Лекция 7
Управление качеством проекта. Лекция 7 Менеджмент и функции менеджмента. Корпоративная культура
Менеджмент и функции менеджмента. Корпоративная культура Стратегический менеджмент
Стратегический менеджмент Организация работ по предоставлению услуг почтовой связи
Организация работ по предоставлению услуг почтовой связи Основы ITIL. Управление ИТ-услугами в соответствии с ITIL
Основы ITIL. Управление ИТ-услугами в соответствии с ITIL Управление конфликтами. (Лекция 18)
Управление конфликтами. (Лекция 18) Метод оценки рисков: “галстук-бабочка”
Метод оценки рисков: “галстук-бабочка” SKW – Strategiczna karta wyników
SKW – Strategiczna karta wyników Совершенствование управления малыми предприятиями в современных условиях (на примере ИП Соловьев А.А.)
Совершенствование управления малыми предприятиями в современных условиях (на примере ИП Соловьев А.А.) Анализ и оценка рисков
Анализ и оценка рисков 1Внешняя и внутренняя срда организации
1Внешняя и внутренняя срда организации Організаційний план як складова частина бізнес-плану
Організаційний план як складова частина бізнес-плану Навыки медицинского представителя. Тренинг
Навыки медицинского представителя. Тренинг Зарубежный опыт управления персоналом
Зарубежный опыт управления персоналом Механізм корпоративного управління
Механізм корпоративного управління Навигатор. Консалтинговая компания
Навигатор. Консалтинговая компания Менеджмент компании Johnson & Johnson
Менеджмент компании Johnson & Johnson Стратегический менеджмент
Стратегический менеджмент Организационная структура таможенных органов
Организационная структура таможенных органов Переговоры, деловые встречи. Решение проблем
Переговоры, деловые встречи. Решение проблем Оперативті басқару, жоспарлау, басқару шешімдерін қабылдау
Оперативті басқару, жоспарлау, басқару шешімдерін қабылдау Санитарные требования к складским помещениям, их планировке, содержанию
Санитарные требования к складским помещениям, их планировке, содержанию To Pouring Pattern Stripping & return Manipulator on jib crane Pattern Change
To Pouring Pattern Stripping & return Manipulator on jib crane Pattern Change Анализ и проектирование рабочего места. Должностные инструкции
Анализ и проектирование рабочего места. Должностные инструкции Басшылардың рөлдерінің түрлері және типологиясы
Басшылардың рөлдерінің түрлері және типологиясы