Асинхронные операции как часть параллельного программирования. Потоки, примитивы синхронизации в c+ +. Привязка к ядрам презентация
- Асинхронные операции как часть параллельного программирования. Потоки, примитивы синхронизации в c+ +. Привязка к ядрам

Содержание
- 2. Введение в параллельное программирование “To put it quite bluntly: as long as there were no machines,
- 3. Знаменитый закон Мура I Закон Мура (1965): каждые 2 года количество транзисторов в интегральной микросхеме удваивается.
- 4. Первый кризис ПО 60-70 годы 20 века Проблема - язык программирования ассемблер. Компьютеры были готовы обрабатывать
- 5. Первый кризис ПО Решение Появление языков высокого уровня С и Фортран. Появление общих свойств у разных
- 6. Второй кризис ПО 80-90 годы 20 века Проблема: невозможность разработки сложных программ, состоящих из миллионов строк
- 7. Второй кризис ПО Решение Появление ООП и развитие языков высокого уровня С#, Java, C++. Появление библиотек
- 8. Назревает третий кризис ПО Особенности Четкая граница между программой и железом. Программисты больше ничего не должны
- 9. Назревает третий кризис ПО Проблема Высокий уровень абстракции не дает программистам достаточной мотивации писать оптимальные программы,
- 10. Шутка - Скажи мне, Microsofе Office, почему ресурс моего компьютера позволяет в онлайне управлять орбитальной группировкой
- 11. Выводы из действия закона Мура Раньше – производительность процессора росла сама по себе, медленная программа с
- 12. Алгоритм Алгоритм – упорядоченная последовательность действий, приводящая к определенному результату. Задача: z = u∙x + v∙y
- 13. Программа Программа – способ выполнения алгоритма на определенном вычислителе. По сути набор инструкций, приводящий к определенному
- 14. Программа 1.load r1, u 2.load r2, x 3.mul r3, r1,r2 4.load r1, v 5.load r2, y
- 15. Реализация Реализация – способ реализации алгоритма при помощи программы. Это множество путей выполнения алгоритма, часто неоптимальных.
- 16. Вы «царь и бог»
- 17. Компоненты вычислителя • исполнительные устройства, ядра, процессоры, вычислительные узлы, кластера, … • блоки памяти - Оперативная
- 18. Системы с общей памятью Многоядерные процессоры Многопроцессорные узлы …
- 19. Системы с распределенной памятью Сети рабочих станций Кластера Grid …
- 20. Общая иерархия
- 21. Меры качества параллельных программ Производительность системы равняется производительности ее самого слабого звена..
- 22. Поход бойскаутов A B 10 км
- 23. Поход бойскаутов 2 км/час WTF???
- 24. Поход бойскаутов 2 км/час WTF???
- 25. Поход бойскаутов 5 км/час
- 26. Меры качества параллельных программ Время работы Сколько времени программа работает на N ядрах? Ускорение Во сколько
- 27. Пример Хорошо масштабируется Плохо масштабируется
- 28. Меры качества параллельных программ Ускорение Ускорение параллельной программы при использовании N исполнительных устройств относительно… •последовательной: •параллельной
- 29. Пример Хорошо масштабируется Плохо масштабируется
- 30. Меры качества параллельных программ Эффективность распараллеливания Эффективность использования N исполнительных устройств относительно… •последовательной программы: •параллельной программы
- 31. Пример Хорошо масштабируется Плохо масштабируется
- 32. Предел ускорения: закон Амдала α – доля последовательных вычислений [0;1]
- 33. Предел ускорения: закон Амдала α – доля последовательных вычислений [0;1] 1 - α – доля параллельных
- 34. Предел ускорения: закон Амдала α – доля последовательных вычислений [0;1] 1 - α – доля параллельных
- 35. Предел ускорения: закон Амдала α – доля последовательных вычислений [0;1] 1 - α – доля параллельных
- 36. Предел ускорения: закон Амдала Ускорение, которое может быть получено на вычислительной системе из p процессоров, по
- 37. Предел ускорения: закон Амдала Ускорение, которое может быть получено на вычислительной системе из p процессоров, по
- 38. Предел ускорения: закон Амдала Если доля последовательных вычислений в алгоритме равна 25 %, то увеличение числа
- 39. Предел ускорения: закон Амдала
- 40. Способы реализация параллельных вычислений Процесс (process) – работающий в текущий момент экземпляр программы
- 41. Способы реализация параллельных вычислений Процесс (process) – работающий в текущий момент экземпляр программы Многозадачность (multitasking) –
- 42. Способы реализация параллельных вычислений Процесс (process) – работающий в текущий момент экземпляр программы Многозадачность (multitasking) –
- 43. Способы реализация параллельных вычислений Процесс (process) – работающий в текущий момент экземпляр программы Многозадачность (multitasking) –
- 44. Главный поток – поток, создаваемый для выполнения программы по умолчанию. Способы реализация параллельных вычислений
- 45. Способы реализация параллельных вычислений
- 46. Максимально нагруженная программа
- 47. Максимально нагруженная программа На сколько % будет загружен четырех-ядерный процессор?
- 48. Максимально нагруженная программа
- 49. Асинхронные операции vs паралелльные вычисления
- 50. Проблемы UI Обрабатываются запросы пользователя. Рисуется интерфейс. Выполняется полезная работа.
- 51. Многопоточность Операции А1-А4 могут выполняться независимо, за их одновременное выполнение отвечает планировщик Windows. Если одна задача
- 52. Отзывчивость интерфейса
- 53. Начальная ситуация Повар готовит роллы == последовательная программа
- 54. Параллельность Много поваров готовит роллы == параллельная реализация
- 55. Асинхронность Повар готовит роллы, помощник варит рис == асинхронность
- 56. Асинхронные операции vs паралелльные вычисления Операции, которые выполняются не прерывая основной поток выполнения программы, называются асинхронными.
- 57. Асинхронные операции Примеры Скачивание интернет-ресурса Взаимодействие с сервером Фоновое копирование файлов в Total Commander И т.д.
- 58. Потоки
- 59. Потоки Стандарт POSIX.1c, Threads extensions (IEEE Std 1003.1c-1995) определяет API для управления потоками, их синхронизации и
- 60. Основные функции Создание потока Передача параметров в поток Ожидание окончания потока Установка приоритета потока Привязка потока
- 61. Пример
- 62. Пример 1. Результат BBBBBBBBBBBBBBBBBBABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABAAAAAAAAAAAAAAAAAA
- 63. Создание потока CreateThread lpThreadAttributes – указатель на SECURITY_ATTRIBUTES (чаще всего NULL) dwStackSize - размер стека в
- 64. Удаление потока Остановка выполнения TerminateThread hThread – хендл потока dwExitCode – код выхода потока Удаление хендла
- 65. Изменение приоритета потока Остановка выполнения TerminateThread hThread – хендл потока dwExitCode – код выхода потока Удаление
- 66. Другие операции SetThreadPriority(handles[0], THREAD_PRIORITY_ABOVE_NORMAL); SetThreadPriority(handles[1], THREAD_PRIORITY_BELOW_NORMAL); Every thread has a base priority level determined by the
- 67. Результат выполнения? ABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABAB
- 68. Привязка потоков к ядрам
- 69. Привязка потоков к ядрам SetThreadAffinityMask(HANDLE hThread, DWORD_PTR dwThreadAffinityMask) dwThreadAffinityMask – число, установленный i-ый бит (== 1),
- 70. Привязка потоков к ядрам SetThreadAffinityMask(handles[0], 1); SetThreadAffinityMask(handles[1], 1); AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB
- 71. Исключения в потоках if( i == 99) i = i / 0; // exception thrown
- 73. Скачать презентацию

Введение в параллельное программирование
“To put it quite bluntly: as long as
Введение в параллельное программирование
“To put it quite bluntly: as long as

Знаменитый закон Мура
I Закон Мура (1965): каждые 2 года количество транзисторов
Знаменитый закон Мура
I Закон Мура (1965): каждые 2 года количество транзисторов

Первый кризис ПО
60-70 годы 20 века
Проблема - язык программирования ассемблер.
Компьютеры
Первый кризис ПО
60-70 годы 20 века
Проблема - язык программирования ассемблер.
Компьютеры

Первый кризис ПО
Решение
Появление языков высокого уровня С и Фортран. Появление общих
Первый кризис ПО
Решение
Появление языков высокого уровня С и Фортран. Появление общих

Второй кризис ПО
80-90 годы 20 века
Проблема: невозможность разработки сложных программ, состоящих
Второй кризис ПО
80-90 годы 20 века
Проблема: невозможность разработки сложных программ, состоящих

Второй кризис ПО
Решение
Появление ООП и развитие языков высокого уровня С#, Java,
Второй кризис ПО
Решение
Появление ООП и развитие языков высокого уровня С#, Java,

Назревает третий кризис ПО
Особенности
Четкая граница между программой и железом.
Программисты больше
Назревает третий кризис ПО
Особенности
Четкая граница между программой и железом.
Программисты больше

Назревает третий кризис ПО
Проблема
Высокий уровень абстракции не дает программистам достаточной мотивации
Назревает третий кризис ПО
Проблема
Высокий уровень абстракции не дает программистам достаточной мотивации

Шутка
- Скажи мне, Microsofе Office, почему ресурс моего компьютера позволяет в
Шутка
- Скажи мне, Microsofе Office, почему ресурс моего компьютера позволяет в

Выводы из действия закона Мура
Раньше – производительность процессора росла сама по
Выводы из действия закона Мура
Раньше – производительность процессора росла сама по

Алгоритм
Алгоритм – упорядоченная последовательность действий, приводящая к определенному результату.
Задача: z =
Алгоритм
Алгоритм – упорядоченная последовательность действий, приводящая к определенному результату.
Задача: z =

Программа
Программа – способ выполнения алгоритма на определенном вычислителе. По сути набор
Программа
Программа – способ выполнения алгоритма на определенном вычислителе. По сути набор

Программа
1.load r1, u
2.load r2, x
3.mul r3, r1,r2
4.load r1, v
5.load r2, y
6.mul
Программа
1.load r1, u
2.load r2, x
3.mul r3, r1,r2
4.load r1, v
5.load r2, y
6.mul
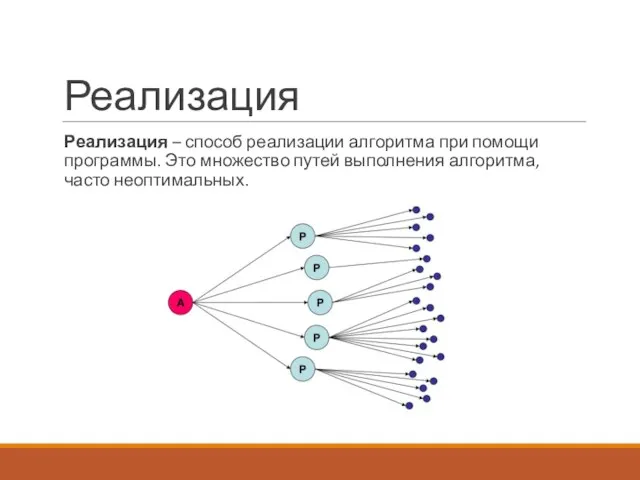
Реализация
Реализация – способ реализации алгоритма при помощи программы. Это множество путей
Реализация
Реализация – способ реализации алгоритма при помощи программы. Это множество путей

Вы «царь и бог»
Вы «царь и бог»

Компоненты вычислителя
• исполнительные устройства, ядра, процессоры, вычислительные узлы, кластера, …
• блоки
Компоненты вычислителя
• исполнительные устройства, ядра, процессоры, вычислительные узлы, кластера, …
• блоки

Системы с общей памятью
Многоядерные процессоры
Многопроцессорные узлы
…
Системы с общей памятью
Многоядерные процессоры
Многопроцессорные узлы
…
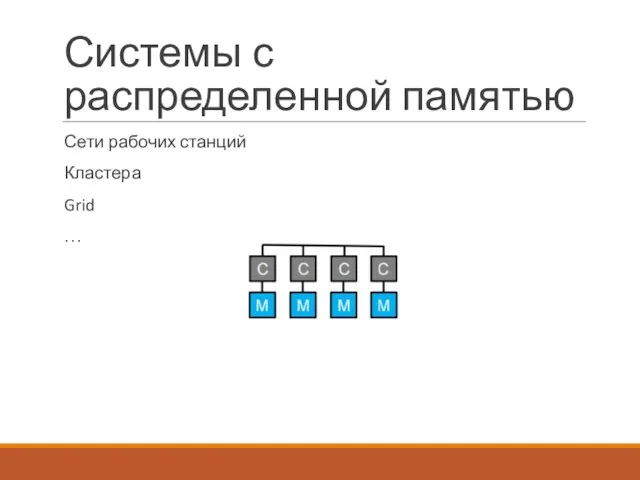
Системы с распределенной памятью
Сети рабочих станций
Кластера
Grid
…
Системы с распределенной памятью
Сети рабочих станций
Кластера
Grid
…
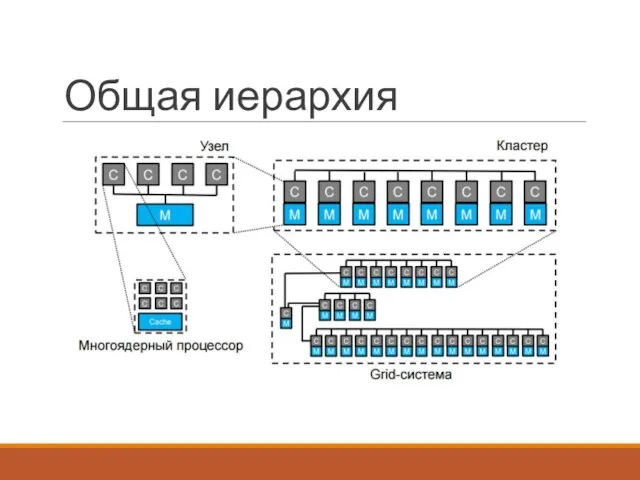
Общая иерархия
Общая иерархия

Меры качества параллельных программ
Производительность системы равняется
производительности ее самого слабого звена..
Меры качества параллельных программ
Производительность системы равняется
производительности ее самого слабого звена..

Поход бойскаутов
A
B
10 км
Поход бойскаутов
A
B
10 км
Поход бойскаутов
2 км/час
WTF???
Поход бойскаутов
2 км/час
WTF???

Поход бойскаутов
2 км/час
WTF???
Поход бойскаутов
2 км/час
WTF???
Поход бойскаутов
5 км/час
Поход бойскаутов
5 км/час

Меры качества параллельных программ
Время работы
Сколько времени программа работает на N
Меры качества параллельных программ
Время работы
Сколько времени программа работает на N
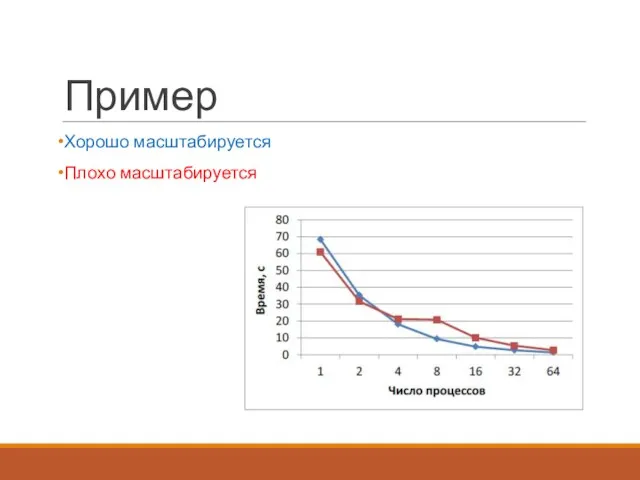
Пример
Хорошо масштабируется
Плохо масштабируется
Пример
Хорошо масштабируется
Плохо масштабируется

Меры качества параллельных программ
Ускорение
Ускорение параллельной программы при использовании N
Меры качества параллельных программ
Ускорение
Ускорение параллельной программы при использовании N

Пример
Хорошо масштабируется
Плохо масштабируется
Пример
Хорошо масштабируется
Плохо масштабируется

Меры качества параллельных программ
Эффективность распараллеливания
Эффективность использования N исполнительных устройств относительно…
•последовательной
Меры качества параллельных программ
Эффективность распараллеливания
Эффективность использования N исполнительных устройств относительно…
•последовательной
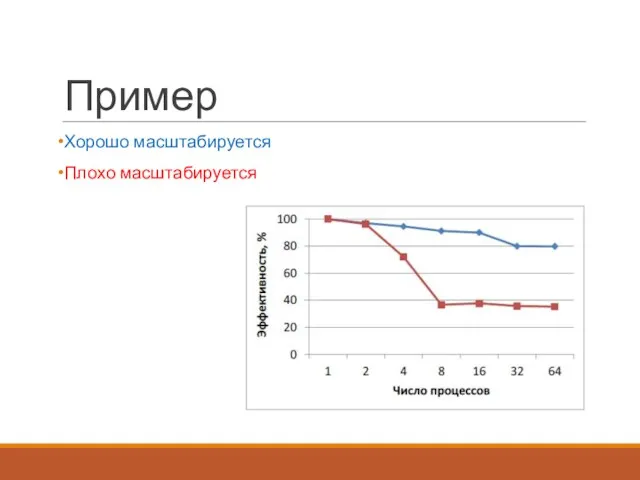
Пример
Хорошо масштабируется
Плохо масштабируется
Пример
Хорошо масштабируется
Плохо масштабируется
![Предел ускорения: закон Амдала α – доля последовательных вычислений [0;1]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/423329/slide-31.jpg)
Предел ускорения: закон Амдала
α – доля последовательных вычислений [0;1]
Предел ускорения: закон Амдала
α – доля последовательных вычислений [0;1]
![Предел ускорения: закон Амдала α – доля последовательных вычислений [0;1]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/423329/slide-32.jpg)
Предел ускорения: закон Амдала
α – доля последовательных вычислений [0;1]
1 -
Предел ускорения: закон Амдала
α – доля последовательных вычислений [0;1]
1 -
![Предел ускорения: закон Амдала α – доля последовательных вычислений [0;1]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/423329/slide-33.jpg)
Предел ускорения: закон Амдала
α – доля последовательных вычислений [0;1]
1 -
Предел ускорения: закон Амдала
α – доля последовательных вычислений [0;1]
1 -
![Предел ускорения: закон Амдала α – доля последовательных вычислений [0;1]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/423329/slide-34.jpg)
Предел ускорения: закон Амдала
α – доля последовательных вычислений [0;1]
1 -
Предел ускорения: закон Амдала
α – доля последовательных вычислений [0;1]
1 -

Предел ускорения: закон Амдала
Ускорение, которое может быть получено на вычислительной
Предел ускорения: закон Амдала
Ускорение, которое может быть получено на вычислительной

Предел ускорения: закон Амдала
Ускорение, которое может быть получено на вычислительной
Предел ускорения: закон Амдала
Ускорение, которое может быть получено на вычислительной
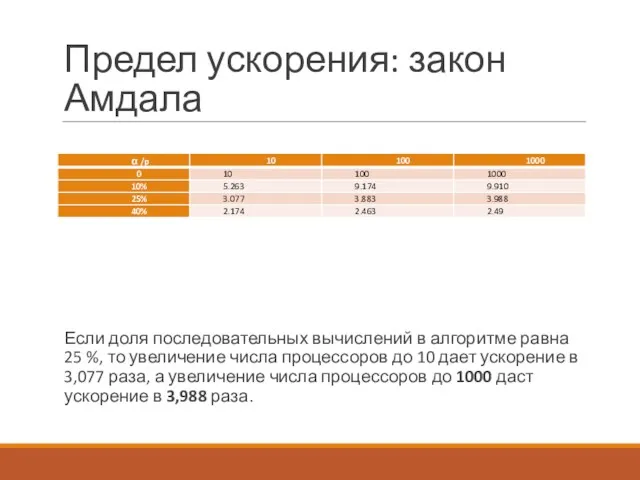
Предел ускорения: закон Амдала
Если доля последовательных вычислений в алгоритме равна
Предел ускорения: закон Амдала
Если доля последовательных вычислений в алгоритме равна
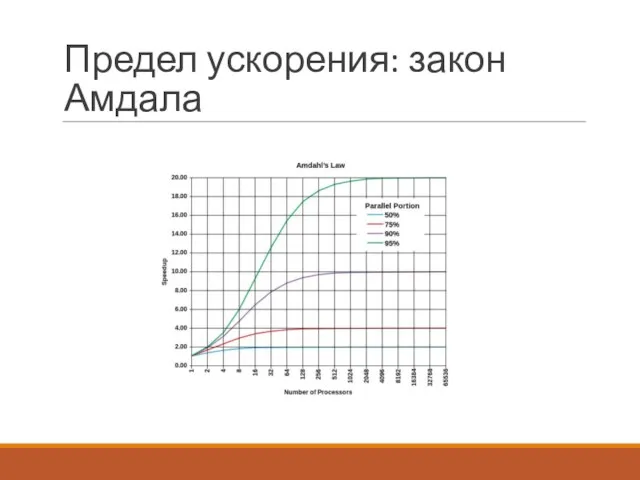
Предел ускорения: закон Амдала
Предел ускорения: закон Амдала

Способы реализация параллельных вычислений
Процесс (process) – работающий в текущий момент экземпляр
Способы реализация параллельных вычислений
Процесс (process) – работающий в текущий момент экземпляр

Способы реализация параллельных вычислений
Процесс (process) – работающий в текущий момент экземпляр
Способы реализация параллельных вычислений
Процесс (process) – работающий в текущий момент экземпляр

Способы реализация параллельных вычислений
Процесс (process) – работающий в текущий момент экземпляр
Способы реализация параллельных вычислений
Процесс (process) – работающий в текущий момент экземпляр

Способы реализация параллельных вычислений
Процесс (process) – работающий в текущий момент экземпляр
Способы реализация параллельных вычислений
Процесс (process) – работающий в текущий момент экземпляр

Главный поток – поток, создаваемый для выполнения программы по умолчанию.
Способы
Главный поток – поток, создаваемый для выполнения программы по умолчанию.
Способы
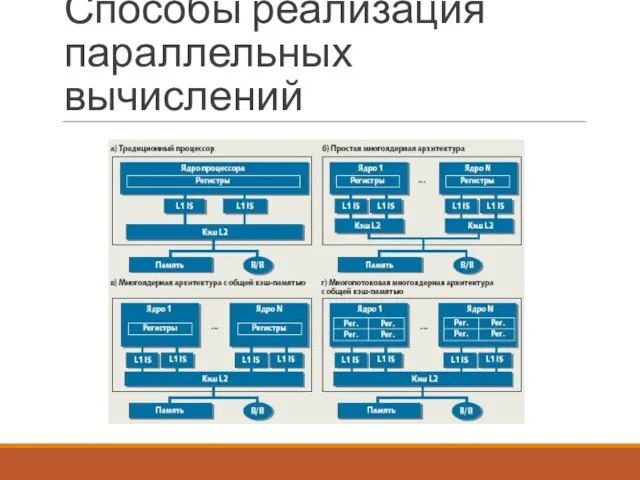
Способы реализация параллельных вычислений
Способы реализация параллельных вычислений

Максимально нагруженная программа
Максимально нагруженная программа

Максимально нагруженная программа
На сколько % будет загружен четырех-ядерный процессор?
Максимально нагруженная программа
На сколько % будет загружен четырех-ядерный процессор?

Максимально нагруженная программа
Максимально нагруженная программа

Асинхронные операции vs паралелльные вычисления
Асинхронные операции vs паралелльные вычисления
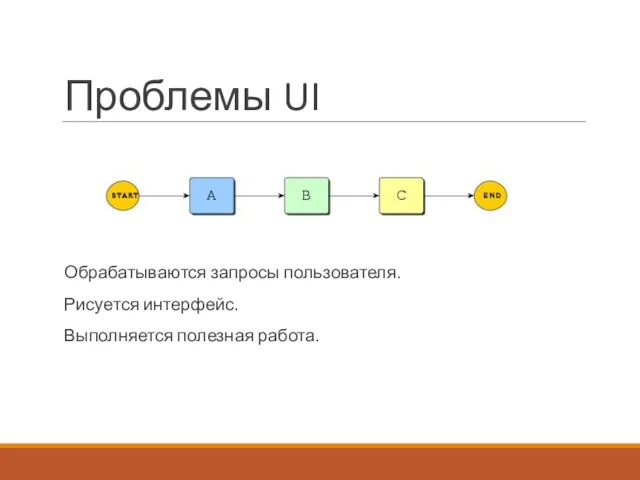
Проблемы UI
Обрабатываются запросы пользователя.
Рисуется интерфейс.
Выполняется полезная работа.
Проблемы UI
Обрабатываются запросы пользователя.
Рисуется интерфейс.
Выполняется полезная работа.
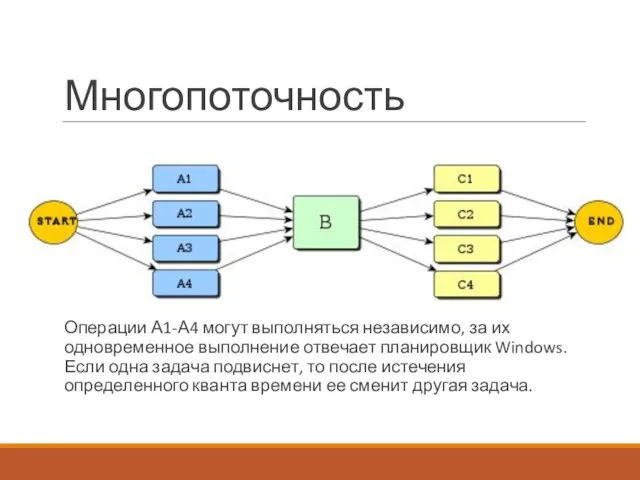
Многопоточность
Операции А1-А4 могут выполняться независимо, за их одновременное выполнение отвечает планировщик
Многопоточность
Операции А1-А4 могут выполняться независимо, за их одновременное выполнение отвечает планировщик
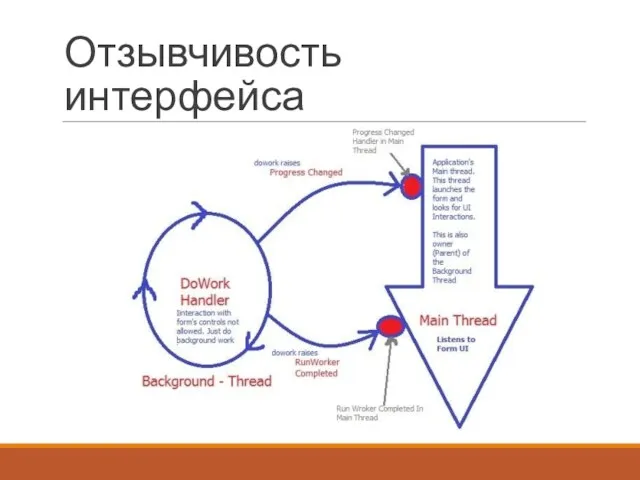
Отзывчивость интерфейса
Отзывчивость интерфейса

Начальная ситуация
Повар готовит роллы == последовательная программа
Начальная ситуация
Повар готовит роллы == последовательная программа

Параллельность
Много поваров готовит роллы == параллельная реализация
Параллельность
Много поваров готовит роллы == параллельная реализация

Асинхронность
Повар готовит роллы, помощник варит рис == асинхронность
Асинхронность
Повар готовит роллы, помощник варит рис == асинхронность

Асинхронные операции vs паралелльные вычисления
Операции, которые выполняются не прерывая основной поток
Асинхронные операции vs паралелльные вычисления
Операции, которые выполняются не прерывая основной поток

Асинхронные операции
Примеры
Скачивание интернет-ресурса
Взаимодействие с сервером
Фоновое копирование файлов в Total Commander
И т.д.
Асинхронные операции
Примеры
Скачивание интернет-ресурса
Взаимодействие с сервером
Фоновое копирование файлов в Total Commander
И т.д.

Потоки
Потоки

Потоки
Стандарт POSIX.1c, Threads extensions (IEEE Std 1003.1c-1995) определяет API для управления
Потоки
Стандарт POSIX.1c, Threads extensions (IEEE Std 1003.1c-1995) определяет API для управления

Основные функции
Создание потока
Передача параметров в поток
Ожидание окончания потока
Установка приоритета потока
Привязка потока
Основные функции
Создание потока
Передача параметров в поток
Ожидание окончания потока
Установка приоритета потока
Привязка потока

Пример
Пример

Пример 1. Результат
BBBBBBBBBBBBBBBBBBABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABAAAAAAAAAAAAAAAAAA
Пример 1. Результат
BBBBBBBBBBBBBBBBBBABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABAAAAAAAAAAAAAAAAAA

Создание потока
CreateThread
lpThreadAttributes – указатель на SECURITY_ATTRIBUTES (чаще всего NULL)
dwStackSize - размер стека
Создание потока
CreateThread
lpThreadAttributes – указатель на SECURITY_ATTRIBUTES (чаще всего NULL)
dwStackSize - размер стека

Удаление потока
Остановка выполнения
TerminateThread
hThread – хендл потока
dwExitCode – код выхода потока
Удаление хендла
CloseHandle
hThread
Удаление потока
Остановка выполнения
TerminateThread
hThread – хендл потока
dwExitCode – код выхода потока
Удаление хендла
CloseHandle
hThread

Изменение приоритета потока
Остановка выполнения
TerminateThread
hThread – хендл потока
dwExitCode – код выхода потока
Удаление
Изменение приоритета потока
Остановка выполнения
TerminateThread
hThread – хендл потока
dwExitCode – код выхода потока
Удаление
![Другие операции SetThreadPriority(handles[0], THREAD_PRIORITY_ABOVE_NORMAL); SetThreadPriority(handles[1], THREAD_PRIORITY_BELOW_NORMAL); Every thread has a](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/423329/slide-65.jpg)
Другие операции
SetThreadPriority(handles[0], THREAD_PRIORITY_ABOVE_NORMAL);
SetThreadPriority(handles[1], THREAD_PRIORITY_BELOW_NORMAL);
Every thread has a base priority level determined
Другие операции
SetThreadPriority(handles[0], THREAD_PRIORITY_ABOVE_NORMAL);
SetThreadPriority(handles[1], THREAD_PRIORITY_BELOW_NORMAL);
Every thread has a base priority level determined

Результат выполнения?
ABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABAB
Результат выполнения?
ABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABAB

Привязка потоков к ядрам
Привязка потоков к ядрам

Привязка потоков к ядрам
SetThreadAffinityMask(HANDLE hThread, DWORD_PTR dwThreadAffinityMask)
dwThreadAffinityMask – число, установленный i-ый
Привязка потоков к ядрам
SetThreadAffinityMask(HANDLE hThread, DWORD_PTR dwThreadAffinityMask)
dwThreadAffinityMask – число, установленный i-ый
![Привязка потоков к ядрам SetThreadAffinityMask(handles[0], 1); SetThreadAffinityMask(handles[1], 1); AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/423329/slide-69.jpg)
Привязка потоков к ядрам
SetThreadAffinityMask(handles[0], 1);
SetThreadAffinityMask(handles[1], 1);
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB
Привязка потоков к ядрам
SetThreadAffinityMask(handles[0], 1);
SetThreadAffinityMask(handles[1], 1);
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB

Исключения в потоках
if( i == 99) i = i / 0; //
Исключения в потоках
if( i == 99) i = i / 0; //
 Использование прикладных программ компьютера в работе с дошкольниками для формирования знаний по правилам дорожного движения
Использование прикладных программ компьютера в работе с дошкольниками для формирования знаний по правилам дорожного движения Информационное моделирование
Информационное моделирование Медиапланирование как основа деятельности пресс-службы
Медиапланирование как основа деятельности пресс-службы Растровая графика
Растровая графика Выполнение работ по одной или нескольким профессиям рабочих, должностям служащих
Выполнение работ по одной или нескольким профессиям рабочих, должностям служащих Введение в Python
Введение в Python Методы на языке С#
Методы на языке С# Алгоритми. Лекция 1
Алгоритми. Лекция 1 Основные понятия языка гипертекстовой разметки документов HTML. Структура html-документа
Основные понятия языка гипертекстовой разметки документов HTML. Структура html-документа Антивирусные программы
Антивирусные программы Веб-разработка. Библиотека jQuery
Веб-разработка. Библиотека jQuery Алфавитный подход к определению количества информации
Алфавитный подход к определению количества информации Обработка исключений Python
Обработка исключений Python Тема 6
Тема 6 Журнал Esquire как СМИ
Журнал Esquire как СМИ История телеканала TV1000
История телеканала TV1000 Онтологический инжиниринг
Онтологический инжиниринг Swot-анализ мобильного приложения GrandApp
Swot-анализ мобильного приложения GrandApp Администрирование информационных систем
Администрирование информационных систем Программа Графический дизайнер старт карьеры
Программа Графический дизайнер старт карьеры Python nima?
Python nima? Двигатели на платформе arduino
Двигатели на платформе arduino Системы оптического распознавания документов
Системы оптического распознавания документов Концептуальное проектирование базы данных
Концептуальное проектирование базы данных Мир электронной почты, телеконференция. 9 класс
Мир электронной почты, телеконференция. 9 класс Основные направления развития искусственного интеллекта (лекция 2)
Основные направления развития искусственного интеллекта (лекция 2) Основы алгебры логики. Логические основы компьютера
Основы алгебры логики. Логические основы компьютера Виды 3D-моделирования
Виды 3D-моделирования