- Дополнительные возможности SQL

Содержание
- 2. Зачем соединения? Что такое предикат соединения? Для каких строк и из каких таблиц проверяется предикат? Какие
- 3. Объединение результатов нескольких запросов Вынесение подзапроса в оператор WITH Аналитические функции Оконные функции Иерархические запросы Практика
- 4. Объединение результатов нескольких запросов Клиенты Клиенты Партнеров
- 5. Объединение результатов нескольких запросов Объединение результатов запросов позволяет сформировать единый набор данных Какие запросы можно объединять
- 6. Объединение результатов нескольких запросов SELECT -- Q1 column1 ,column2 ,column3 FROM [TABLE_1] as t1 -- таблица
- 7. Объединение результатов нескольких запросов UNION vs UNION ALL UNION ALL объединяет 2 набора данных и выводит
- 8. Обобщенное табличное выражение Common Table Expression CTE – способ оформления кода Не влияет на выполнение SQL
- 9. Common Table Expression WITH [CTE_NAME] as ( SELECT * FROM [TABLE_1] as t1 -- таблица или
- 10. Аналитические, Ранжирующие Оконные функции Аналитические функции вычисляют статистическое значение на основе группы строк. Аналитические функции можно
- 11. Оконные функции Задают правила разбиения строк на группы (секции, окна) Задают правила упорядочивания строк в группе
- 12. Оконные функции SELECT FUNC( ? ) OVER( PARTITION BY Column1 ORDER BY Column 2, Column 3)
- 13. Оконные функции Нарастающий итог Ранжирование Добавление к строке «пред.\след.» значений какой-то величины Сумма продаж месяцем ранее
- 14. Ранжирующие функции ROW_NUMBER() – нумерует строки по порядку ROW_NUMBER() OVER(PARTITION BY ? ORDER BY ? )
- 15. Аналитические функции LAG(scalar_expression, offset, default ) – возвращает «предыдущее» значение LAG(?, ?, ? )OVER(PARTITION BY ?
- 16. Иерархическая структура Примеры иерархической организации: Главная компания Дочерняя компания Маленькая дочерняя компания Маленькая дочерняя компания Страна
- 18. Скачать презентацию

Зачем соединения?
Что такое предикат соединения?
Для каких строк и из каких таблиц
Зачем соединения?
Что такое предикат соединения?
Для каких строк и из каких таблиц

Объединение результатов нескольких запросов
Вынесение подзапроса в оператор WITH
Аналитические функции
Оконные функции
Объединение результатов нескольких запросов
Вынесение подзапроса в оператор WITH
Аналитические функции
Оконные функции

Объединение результатов нескольких запросов
Клиенты
Клиенты Партнеров
Объединение результатов нескольких запросов
Клиенты
Клиенты Партнеров

Объединение результатов нескольких запросов
Объединение результатов запросов позволяет сформировать единый набор данных
Какие
Объединение результатов нескольких запросов
Объединение результатов запросов позволяет сформировать единый набор данных
Какие
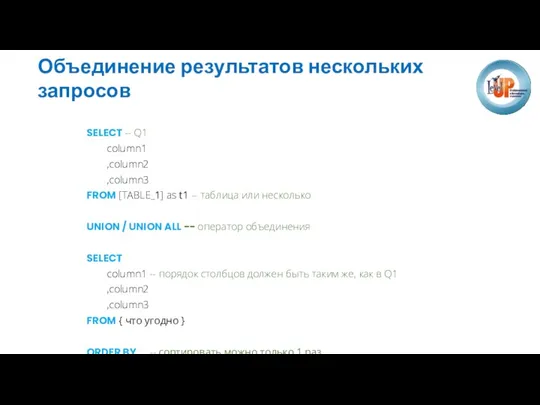
Объединение результатов нескольких запросов
SELECT -- Q1
column1
,column2
,column3
FROM [TABLE_1] as t1 -- таблица
Объединение результатов нескольких запросов
SELECT -- Q1
column1
,column2
,column3
FROM [TABLE_1] as t1 -- таблица

Объединение результатов нескольких запросов
UNION vs UNION ALL
UNION ALL объединяет 2 набора
Объединение результатов нескольких запросов
UNION vs UNION ALL
UNION ALL объединяет 2 набора

Обобщенное табличное выражение
Common Table Expression
CTE – способ оформления кода
Не влияет на
Обобщенное табличное выражение
Common Table Expression
CTE – способ оформления кода
Не влияет на
![Common Table Expression WITH [CTE_NAME] as ( SELECT * FROM](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/206483/slide-8.jpg)
Common Table Expression
WITH [CTE_NAME] as (
SELECT *
FROM [TABLE_1] as t1 --
Common Table Expression
WITH [CTE_NAME] as (
SELECT *
FROM [TABLE_1] as t1 --

Аналитические, Ранжирующие
Оконные функции
Аналитические функции вычисляют статистическое значение на основе
Аналитические, Ранжирующие
Оконные функции
Аналитические функции вычисляют статистическое значение на основе

Оконные функции
Задают правила разбиения строк на группы (секции, окна)
Задают правила
Оконные функции
Задают правила разбиения строк на группы (секции, окна)
Задают правила

Оконные функции
SELECT
FUNC( ? ) OVER( PARTITION BY Column1 ORDER BY
Оконные функции
SELECT
FUNC( ? ) OVER( PARTITION BY Column1 ORDER BY

Оконные функции
Нарастающий итог
Ранжирование
Добавление к строке «пред.\след.» значений какой-то величины
Сумма продаж месяцем
Оконные функции
Нарастающий итог
Ранжирование
Добавление к строке «пред.\след.» значений какой-то величины
Сумма продаж месяцем

Ранжирующие функции
ROW_NUMBER() – нумерует строки по порядку
ROW_NUMBER() OVER(PARTITION BY ? ORDER
Ранжирующие функции
ROW_NUMBER() – нумерует строки по порядку
ROW_NUMBER() OVER(PARTITION BY ? ORDER

Аналитические функции
LAG(scalar_expression, offset, default ) – возвращает «предыдущее» значение
LAG(?, ?, ?
Аналитические функции
LAG(scalar_expression, offset, default ) – возвращает «предыдущее» значение
LAG(?, ?, ?

Иерархическая структура
Примеры иерархической организации:
Главная компания
Дочерняя компания
Маленькая дочерняя компания
Маленькая дочерняя компания
Страна
Область
Город
Улица
Потомок
Иерархическая структура
Примеры иерархической организации:
Главная компания
Дочерняя компания
Маленькая дочерняя компания
Маленькая дочерняя компания
Страна
Область
Город
Улица
Потомок
 Интернет технологии Язык HTML и основы Web - страниц
Интернет технологии Язык HTML и основы Web - страниц Ютуберы и блогеры
Ютуберы и блогеры JAVA – Язык программирования
JAVA – Язык программирования Снифферы, ddos
Снифферы, ddos Определение количества информации
Определение количества информации Путешествие по клавишам
Путешествие по клавишам Информация и информационные процессы
Информация и информационные процессы Программирование на VBA. (Тема 2)
Программирование на VBA. (Тема 2) Software metrics using constructive cost model
Software metrics using constructive cost model Функції. Масиви
Функції. Масиви Элементы теории языков. Лекция 24
Элементы теории языков. Лекция 24 Microcontrollers board misis board 877
Microcontrollers board misis board 877 Правильное место для торговли бинарными опционами
Правильное место для торговли бинарными опционами Указатели. Динамические массивы
Указатели. Динамические массивы Unity Timeline
Unity Timeline Компьютерные вирусы и методы борьбы с ними
Компьютерные вирусы и методы борьбы с ними Язык Python. Виключення
Язык Python. Виключення Техника безопасности в компьютерном классе
Техника безопасности в компьютерном классе HTTP, HTTPS, FTP
HTTP, HTTPS, FTP Архитектура и структура персонального компьютера
Архитектура и структура персонального компьютера Как правильно установить Windows7
Как правильно установить Windows7 Робот, помогающий хозяевам пушистых комочков, делать своих питомцев счастливыми
Робот, помогающий хозяевам пушистых комочков, делать своих питомцев счастливыми Практическая работа в MS PowerPoint-2010
Практическая работа в MS PowerPoint-2010 OpenServer – программа, позволяющая запускать на компьютере локальный web‐сервер
OpenServer – программа, позволяющая запускать на компьютере локальный web‐сервер Розв’язування задач, які передбачають створення програмних об’єктів
Розв’язування задач, які передбачають створення програмних об’єктів 12_Псевдоклассы. Псевдоэлементы
12_Псевдоклассы. Псевдоэлементы Задания TulaHack-2019
Задания TulaHack-2019 Построение запросов к БД оператор select
Построение запросов к БД оператор select