- Программная среда Hadoop

Содержание
- 2. Hadoop MapReduce HDFS Avro Pig Spark MLLIB На этой лекции будут рассмотрены
- 3. Hadoop - это программная среда с открытым исходным кодом, используемая для распределенного хранения и обработки наборов
- 4. Статья "Файловая система Google", опубликована в октябре 2003 года; Hadoop 0.1.0 был выпущен в апреле 2006
- 5. Гибкость для хранения и обработки данных любого типа, будь то структурированные, полуструктурированные или неструктурированные. Он не
- 6. Hadoop работает по системе master-slave. Есть главный узел и есть подчиненные узлы. Главный узел управляет, поддерживает
- 7. Основная система хранения Hadoop. Файловая система на основе Java; Масштабируемая; Отказоустойчивая; Надежная и экономичная. Hadoop Distributed
- 8. FTP file system; Amazon S3 (Simple Storage Service) file system; Windows Azure Storage Blobs (WASB) file
- 9. Namenode - работает на главном узле для HDFS. DataNode - работает на подчиненных узлах для HDFS.
- 10. https://www.joelonsoftware.com/2006/08/01/can-your-programming-language-do-this/ MapReduce
- 11. Hadoop MapReduce
- 12. JobTracker: Принимает задания от клиента; Передает задания на доступные узлы TaskTracker в кластере; TaskTracker: Запускает задания
- 13. Простота - задания MapReduce легко выполнять. Приложения могут быть написаны на любом языке, например, Java, C
- 14. Технология управления ресурсами с открытым исходным кодом, которая развернута в кластере Hadoop. YARN стремится эффективно распределять
- 15. Гибкость - включает другие специализированные модели обработки данных, помимо MapReduce (пакетные), такие как интерактивная и потоковая.
- 16. Apache Hive - это система организации хранилища данных с открытым исходным кодом для запроса и анализа
- 17. Распределенная база данных, предназначенная для хранения структурированных данных в таблицах, которые могут содержать миллиарды строк и
- 18. Avro - это проект с открытым исходным кодом, который предоставляет сериализацию данных и услуги обмена данными
- 19. Parquet, JSON, CSV поддерживаются "из коробки", есть множество плагинов для различных других форматов данных. Другие форматы
- 20. Sqoop импортирует данные из внешних источников в связанные компоненты экосистемы Hadoop, такие как HDFS, Hbase или
- 21. Apache Zookeeper - это централизованная служба и компонент экосистемы Hadoop для поддержки информации о конфигурации, наименованиb,
- 22. HDFS - это распределенная файловая система, отказоустойчивая, масштабируемая и чрезвычайно легко расширяемая. HDFS является основным распределенным
- 23. NameNode: сердце файловой системы HDFS, он поддерживает и управляет метаданными файловой системы. Например; какие блоки составляют
- 24. HDFS: структура
- 25. Отказоустойчивость - данные дублируются на нескольких узлах данных для защиты от сбоев компьютера. По умолчанию коэффициент
- 26. Каждый файл, записанный в HDFS, разбивается на блоки данных Каждый блок хранится на одном или нескольких
- 27. HDFS: Операции чтения и записи
- 28. HDFS: Heartbeats
- 29. HDFS: Чтение данных
- 30. HDFS: Запись данных
- 31. Аутентификация в Hadoop Простой - небезопасный способ использования имени пользователя ОС для аутентификации в hadoop; Kerberos
- 32. Java API (DistributedFileSystem) Обертка на C (libhdfs) Протокол HTTP Протокол WebDAV Командная строка Командная строка является
- 33. Пользовательские Команды hdfs dfs - запускает команды файловой системы на HDFS hdfs fsck - запускает команду
- 34. Показать содержимое директории HDFS: Команды hdfs dfs –ls hdfs dfs -ls / hdfs dfs -ls -R
- 35. Перенести данные в HDFS HDFS: Команды hdfs dfs -mkdir mydata hdfs dfs -ls hdfs dfs -copyFromLocal
- 36. Посмотреть acl для файла HDFS: Команды hdfs dfs -getfacl mydata/somefile.avro hdfs dfs -stat "%r" mydata/somefile.avro echo
- 37. Удалить файл HDFS: Команды (fsck) hdfs dfs -rm mydata/somefile.avro hdfs dfs -ls –R hdfs fsck mydata/somefile.avro
- 38. Запросить отчет об состоянии кластера HDFS: Команды администрирования hdfs dfsadmin –report hdfs dfsadmin –printTopology hdfs dfsadmin
- 39. Получить список namenode кластера HDFS: Команды hdfs getconf –namenodes cd /var/lib/hadoop-hdfs/cache/hdfs/dfs/name/current hdfs oiv -i fsimage_0000000000000003388 -o
- 40. Avro Пример схемы AVRO в формате JSON { "type" : "record", "name" : "tweets", "fields" :
- 41. колоночный формат хранения Ключевым преимуществом является хранение вложенных данных в действительно столбчатом формате с использованием уровней
- 42. Способы внесения данных в Hadoop
- 43. Sqoop сокращает количество запросов для осуществления импорта и экспорта с помощью MapReduce Sqoop всегда требует драйвер
- 44. Среда для анализа больших неструктурированных и полуструктурированных данных поверх Hadoop. Pig Engine анализирует, компилирует скрипты Pig
- 45. Ускорение разработки Меньше строк кода (написание MapReduce, как написание SQL-запросов) Повторно используйте код (Pig library, Piggy
- 46. Посчет количества слов на MapReduce
- 47. То же самое на Pig Lines=LOAD ‘input/hadoop.log’ AS (line: chararray); Words = FOREACH Lines GENERATE FLATTEN(TOKENIZE(line))
- 48. Производительность Pig по сравнению с чистым MapReduce
- 49. UDF могут быть написаны, чтобы воспользоваться преимуществом combiner; Четыре реализации join Написание функций загрузки и сохранения
- 50. 70% вычислений в Yahoo (10ks в день) Twitter, LinkedIn, Ebay, AOL,… используют Pig чтобы: Обрабатывать веб-журналы
- 51. Варианты: Пакетный режим: отправить скрипт напрямую Интерактивный режим: Grunt, командная строка Java-класс PigServer, JDBC-подобный интерфейс Режимы
- 52. Скалярные типы: Int, long, float, double, boolean, null, chararray, bytearry; Сложные типы: field, tuple, bag, relation;
- 53. Загрузка данных LOAD loads input data Lines=LOAD ‘input/access.log’ AS (line: chararray); Проекция FOREACH … GENERTE …
- 54. PigStorage: загружает / сохраняет отношения, используя текстовый формат с разделителями полей TextLoader: загружает отношения из простого
- 55. The Foreach … перебирает элементы bag и преобразует их. В результате Foreach тоже получается bag Элементы
- 56. Поля можно адресовать по их позиции. Позиционная нотация в Pig students = LOAD 'student.txt' USING PigStorage()
- 57. Группирует данные в одно или несколько отношений Операторы GROUP и COGROUP идентичны. Оба оператора работают с
- 58. Pig: Dump&Store A = LOAD ‘input/pig/multiquery/A’; B = FILTER A by $1 == “apple”; C =
- 59. Вычислить количество элементов в сумке Используйте функцию COUNT для вычисления количества элементов в сумке. Для COUNT
- 60. Сортирует отношение на основе одного или нескольких полей В Pig отношения неупорядочены. Если вы сортируете отношение
- 61. Локальный режим Используется локальный хост и локальная файловая система Ни Hadoop, ни HDFS не требуются Полезно
- 62. Быстрая, выразительная кластерная вычислительная система, совместимая с Apache Hadoop Работает с любой системой хранения, поддерживаемой Hadoop
- 63. Локальный многоядерный режим: просто библиотека в вашей программе EC2: скрипты для запуска кластера Spark Частный кластер:
- 64. API в Java, Scala и Python Интерактивные оболочки в Scala и Python Поддержка языков в Spark
- 65. Работайте с распределенными коллекциями, как с локальными. Концепция: устойчивые распределенные наборы данных (RDD) Неизменные коллекции объектов,
- 66. Transformations (e.g. map, filter, groupBy, join) Ленивые операции, которые строят RDD из других RDD Actions (e.g.
- 67. Автономные программы могут быть написаны на любом из трех языков, но консоль - это только Python
- 68. Главная точка входа в функциональность Spark Создан для вас в Spark shell как переменная sc В
- 69. # Превратить локальную коллекцию в RDD sc.parallelize ([1, 2, 3]) # Загрузить текстовый файл из локальной
- 70. nums = sc.parallelize ([1, 2, 3]) # Пропустить каждый элемент через функцию squares = nums.map (lambda
- 71. nums = sc.parallelize([1, 2, 3]) # Взять значение RDD в локальную переменную nums.collect() # => [1,
- 72. Быстрая, выразительная кластерная вычислительная система, совместимая с Apache Hadoop Работает с любой системой хранения, поддерживаемой Hadoop
- 73. Заключение Экосистема Hadoop огромна, и содержит элементы для практически любых нужд; Hadoop ориентирован на доставку запросов
- 75. Скачать презентацию

Hadoop
MapReduce
HDFS
Avro
Pig
Spark
MLLIB
На этой лекции будут рассмотрены
Hadoop
MapReduce
HDFS
Avro
Pig
Spark
MLLIB
На этой лекции будут рассмотрены

Hadoop - это программная среда с открытым исходным кодом, используемая для
Hadoop - это программная среда с открытым исходным кодом, используемая для

Статья "Файловая система Google", опубликована в октябре 2003 года;
Hadoop 0.1.0 был
Статья "Файловая система Google", опубликована в октябре 2003 года;
Hadoop 0.1.0 был

Гибкость для хранения и обработки данных любого типа, будь то структурированные,
Гибкость для хранения и обработки данных любого типа, будь то структурированные,
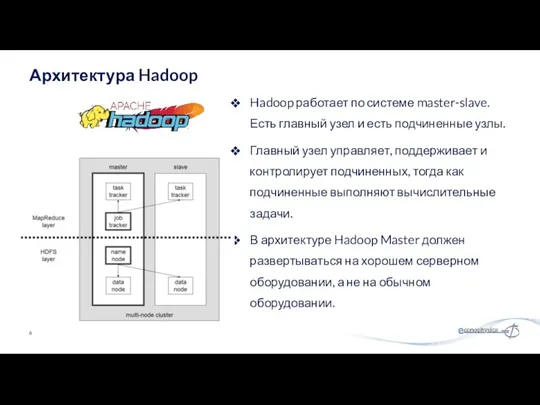
Hadoop работает по системе master-slave. Есть главный узел и есть подчиненные
Hadoop работает по системе master-slave. Есть главный узел и есть подчиненные

Основная система хранения Hadoop.
Файловая система на основе Java;
Масштабируемая;
Отказоустойчивая;
Надежная и
Основная система хранения Hadoop.
Файловая система на основе Java;
Масштабируемая;
Отказоустойчивая;
Надежная и
FTP file system;
Amazon S3 (Simple Storage Service) file system;
Windows Azure Storage
FTP file system;
Amazon S3 (Simple Storage Service) file system;
Windows Azure Storage

Namenode - работает на главном узле для HDFS.
DataNode - работает на
Namenode - работает на главном узле для HDFS.
DataNode - работает на

https://www.joelonsoftware.com/2006/08/01/can-your-programming-language-do-this/
MapReduce
https://www.joelonsoftware.com/2006/08/01/can-your-programming-language-do-this/
MapReduce
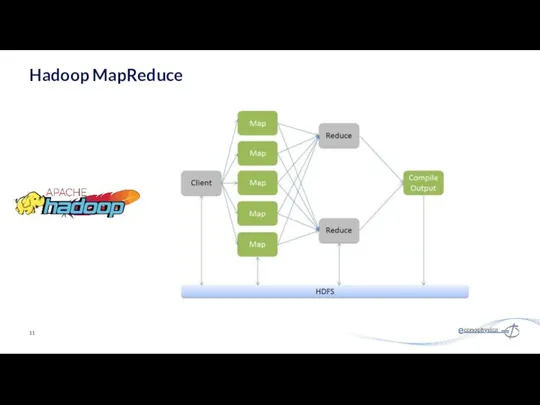
Hadoop MapReduce
Hadoop MapReduce

JobTracker:
Принимает задания от клиента;
Передает задания на доступные узлы TaskTracker в кластере;
TaskTracker:
Запускает
JobTracker:
Принимает задания от клиента;
Передает задания на доступные узлы TaskTracker в кластере;
TaskTracker:
Запускает

Простота - задания MapReduce легко выполнять. Приложения могут быть написаны на
Простота - задания MapReduce легко выполнять. Приложения могут быть написаны на

Технология управления ресурсами с открытым исходным кодом, которая развернута в кластере
Технология управления ресурсами с открытым исходным кодом, которая развернута в кластере

Гибкость - включает другие специализированные модели обработки данных, помимо MapReduce (пакетные),
Гибкость - включает другие специализированные модели обработки данных, помимо MapReduce (пакетные),

Apache Hive - это система организации хранилища данных с открытым исходным
Apache Hive - это система организации хранилища данных с открытым исходным

Распределенная база данных, предназначенная для хранения структурированных данных в таблицах, которые
Распределенная база данных, предназначенная для хранения структурированных данных в таблицах, которые

Avro - это проект с открытым исходным кодом, который предоставляет сериализацию
Avro - это проект с открытым исходным кодом, который предоставляет сериализацию

Parquet, JSON, CSV поддерживаются "из коробки", есть множество плагинов для различных
Parquet, JSON, CSV поддерживаются "из коробки", есть множество плагинов для различных

Sqoop импортирует данные из внешних источников в связанные компоненты экосистемы Hadoop,
Sqoop импортирует данные из внешних источников в связанные компоненты экосистемы Hadoop,

Apache Zookeeper - это централизованная служба и компонент экосистемы Hadoop для
Apache Zookeeper - это централизованная служба и компонент экосистемы Hadoop для

HDFS - это распределенная файловая система, отказоустойчивая, масштабируемая и чрезвычайно легко
HDFS - это распределенная файловая система, отказоустойчивая, масштабируемая и чрезвычайно легко

NameNode: сердце файловой системы HDFS, он поддерживает и управляет метаданными файловой
NameNode: сердце файловой системы HDFS, он поддерживает и управляет метаданными файловой
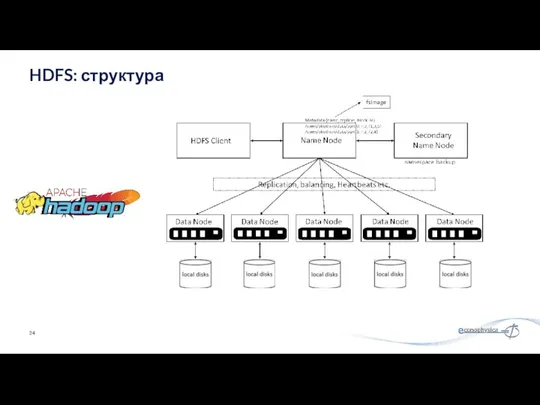
HDFS: структура
HDFS: структура

Отказоустойчивость - данные дублируются на нескольких узлах данных для защиты от
Отказоустойчивость - данные дублируются на нескольких узлах данных для защиты от

Каждый файл, записанный в HDFS, разбивается на блоки данных
Каждый блок хранится
Каждый файл, записанный в HDFS, разбивается на блоки данных
Каждый блок хранится
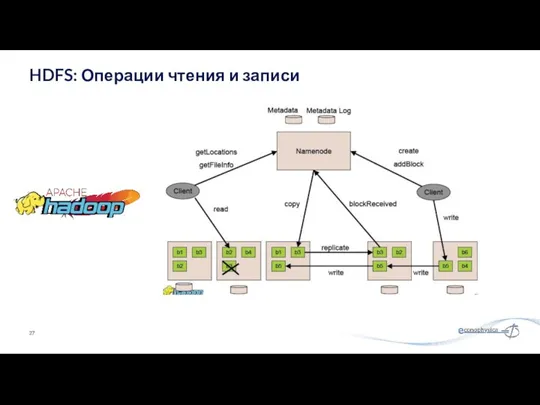
HDFS: Операции чтения и записи
HDFS: Операции чтения и записи
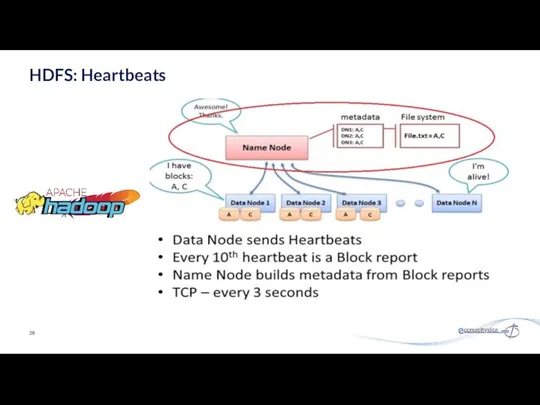
HDFS: Heartbeats
HDFS: Heartbeats
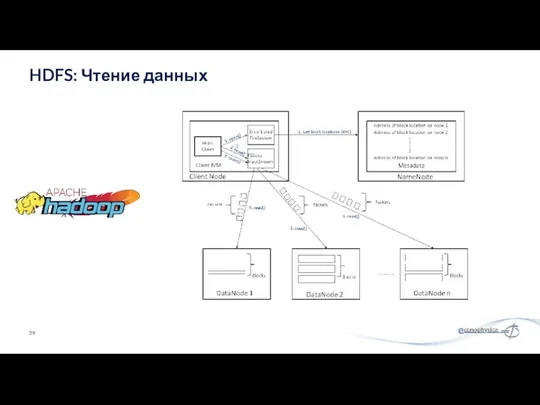
HDFS: Чтение данных
HDFS: Чтение данных
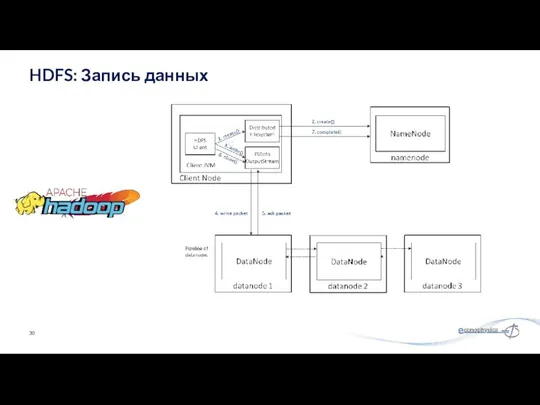
HDFS: Запись данных
HDFS: Запись данных

Аутентификация в Hadoop
Простой - небезопасный способ использования имени пользователя ОС для
Аутентификация в Hadoop
Простой - небезопасный способ использования имени пользователя ОС для

Java API (DistributedFileSystem)
Обертка на C (libhdfs)
Протокол HTTP
Протокол WebDAV
Командная строка
Командная строка является
Java API (DistributedFileSystem)
Обертка на C (libhdfs)
Протокол HTTP
Протокол WebDAV
Командная строка
Командная строка является

Пользовательские Команды
hdfs dfs - запускает команды файловой системы на HDFS
hdfs fsck
Пользовательские Команды
hdfs dfs - запускает команды файловой системы на HDFS
hdfs fsck

Показать содержимое директории
HDFS: Команды
hdfs dfs –ls
hdfs dfs -ls /
hdfs dfs -ls
Показать содержимое директории
HDFS: Команды
hdfs dfs –ls
hdfs dfs -ls /
hdfs dfs -ls
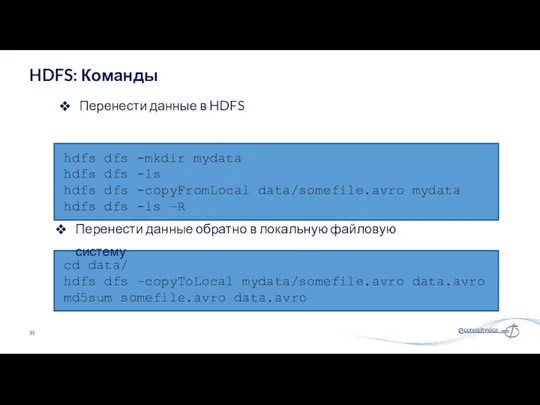
Перенести данные в HDFS
HDFS: Команды
hdfs dfs -mkdir mydata
hdfs dfs -ls
hdfs dfs
Перенести данные в HDFS
HDFS: Команды
hdfs dfs -mkdir mydata
hdfs dfs -ls
hdfs dfs

Посмотреть acl для файла
HDFS: Команды
hdfs dfs -getfacl mydata/somefile.avro
hdfs dfs -stat "%r"
Посмотреть acl для файла
HDFS: Команды
hdfs dfs -getfacl mydata/somefile.avro
hdfs dfs -stat "%r"

Удалить файл
HDFS: Команды (fsck)
hdfs dfs -rm mydata/somefile.avro
hdfs dfs -ls –R
hdfs fsck
Удалить файл
HDFS: Команды (fsck)
hdfs dfs -rm mydata/somefile.avro
hdfs dfs -ls –R
hdfs fsck

Запросить отчет об состоянии кластера
HDFS: Команды администрирования
hdfs dfsadmin –report
hdfs dfsadmin
Запросить отчет об состоянии кластера
HDFS: Команды администрирования
hdfs dfsadmin –report
hdfs dfsadmin
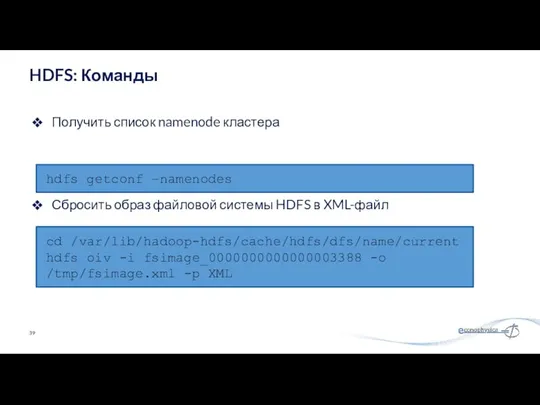
Получить список namenode кластера
HDFS: Команды
hdfs getconf –namenodes
cd /var/lib/hadoop-hdfs/cache/hdfs/dfs/name/current
hdfs oiv -i fsimage_0000000000000003388
Получить список namenode кластера
HDFS: Команды
hdfs getconf –namenodes
cd /var/lib/hadoop-hdfs/cache/hdfs/dfs/name/current
hdfs oiv -i fsimage_0000000000000003388
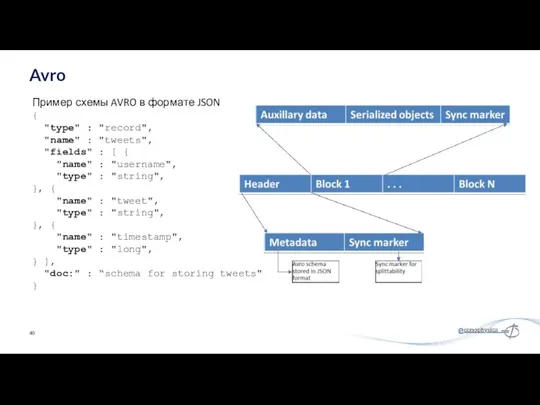
Avro
Пример схемы AVRO в формате JSON
{
"type" : "record",
"name" :
Avro
Пример схемы AVRO в формате JSON
{
"type" : "record",
"name" :
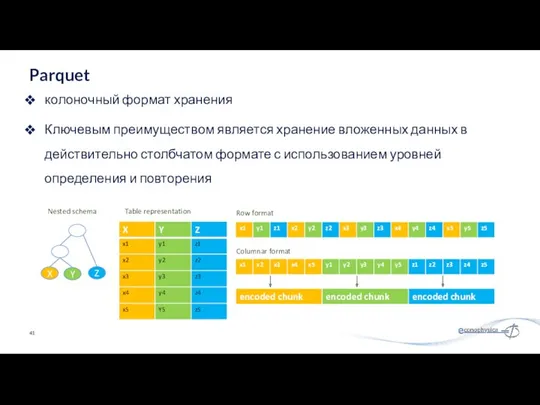
колоночный формат хранения
Ключевым преимуществом является хранение вложенных данных в действительно столбчатом
колоночный формат хранения
Ключевым преимуществом является хранение вложенных данных в действительно столбчатом
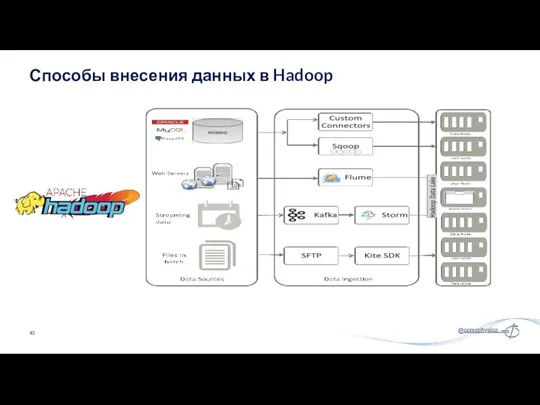
Способы внесения данных в Hadoop
Способы внесения данных в Hadoop

Sqoop сокращает количество запросов для осуществления импорта и экспорта с помощью
Sqoop сокращает количество запросов для осуществления импорта и экспорта с помощью

Среда для анализа больших неструктурированных и полуструктурированных данных поверх Hadoop.
Pig Engine
Среда для анализа больших неструктурированных и полуструктурированных данных поверх Hadoop.
Pig Engine
Ускорение разработки
Меньше строк кода (написание MapReduce, как написание SQL-запросов)
Повторно используйте код
Ускорение разработки
Меньше строк кода (написание MapReduce, как написание SQL-запросов)
Повторно используйте код

Посчет количества слов на MapReduce
Посчет количества слов на MapReduce

То же самое на Pig
Lines=LOAD ‘input/hadoop.log’ AS (line: chararray);
Words =
То же самое на Pig
Lines=LOAD ‘input/hadoop.log’ AS (line: chararray);
Words =
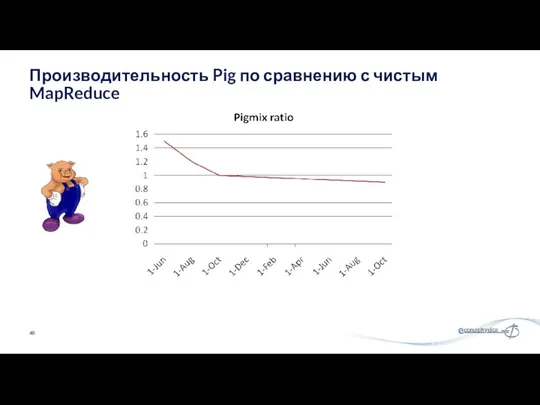
Производительность Pig по сравнению с чистым MapReduce
Производительность Pig по сравнению с чистым MapReduce

UDF могут быть написаны, чтобы воспользоваться преимуществом combiner;
Четыре реализации join
Написание функций
UDF могут быть написаны, чтобы воспользоваться преимуществом combiner;
Четыре реализации join
Написание функций

70% вычислений в Yahoo (10ks в день)
Twitter, LinkedIn, Ebay, AOL,… используют
70% вычислений в Yahoo (10ks в день)
Twitter, LinkedIn, Ebay, AOL,… используют

Варианты:
Пакетный режим: отправить скрипт напрямую
Интерактивный режим: Grunt, командная строка
Java-класс PigServer, JDBC-подобный
Варианты:
Пакетный режим: отправить скрипт напрямую
Интерактивный режим: Grunt, командная строка
Java-класс PigServer, JDBC-подобный

Скалярные типы:
Int, long, float, double, boolean, null, chararray, bytearry;
Сложные типы: field,
Скалярные типы:
Int, long, float, double, boolean, null, chararray, bytearry;
Сложные типы: field,

Загрузка данных
LOAD loads input data
Lines=LOAD ‘input/access.log’ AS (line: chararray);
Проекция
FOREACH …
Загрузка данных
LOAD loads input data
Lines=LOAD ‘input/access.log’ AS (line: chararray);
Проекция
FOREACH …

PigStorage: загружает / сохраняет отношения, используя текстовый формат с разделителями полей
TextLoader:
PigStorage: загружает / сохраняет отношения, используя текстовый формат с разделителями полей
TextLoader:

The Foreach … перебирает элементы bag и преобразует их.
В результате Foreach
The Foreach … перебирает элементы bag и преобразует их.
В результате Foreach

Поля можно адресовать по их позиции.
Позиционная нотация в Pig
students = LOAD
Поля можно адресовать по их позиции.
Позиционная нотация в Pig
students = LOAD

Группирует данные в одно или несколько отношений
Операторы GROUP и COGROUP идентичны.
Оба
Группирует данные в одно или несколько отношений
Операторы GROUP и COGROUP идентичны.
Оба

Pig: Dump&Store
A = LOAD ‘input/pig/multiquery/A’;
B = FILTER A by $1 ==
Pig: Dump&Store
A = LOAD ‘input/pig/multiquery/A’;
B = FILTER A by $1 ==

Вычислить количество элементов в сумке
Используйте функцию COUNT для вычисления количества элементов
Вычислить количество элементов в сумке
Используйте функцию COUNT для вычисления количества элементов

Сортирует отношение на основе одного или нескольких полей
В Pig отношения неупорядочены.
Сортирует отношение на основе одного или нескольких полей
В Pig отношения неупорядочены.

Локальный режим
Используется локальный хост и локальная файловая система
Ни Hadoop, ни
Локальный режим
Используется локальный хост и локальная файловая система
Ни Hadoop, ни

Быстрая, выразительная кластерная вычислительная система, совместимая с Apache Hadoop
Работает с любой
Быстрая, выразительная кластерная вычислительная система, совместимая с Apache Hadoop
Работает с любой

Локальный многоядерный режим: просто библиотека в вашей программе
EC2: скрипты для запуска
Локальный многоядерный режим: просто библиотека в вашей программе
EC2: скрипты для запуска

API в Java, Scala и Python
Интерактивные оболочки в Scala и Python
Поддержка
API в Java, Scala и Python
Интерактивные оболочки в Scala и Python
Поддержка

Работайте с распределенными коллекциями, как с локальными.
Концепция: устойчивые распределенные наборы данных
Работайте с распределенными коллекциями, как с локальными.
Концепция: устойчивые распределенные наборы данных

Transformations (e.g. map, filter, groupBy, join)
Ленивые операции, которые строят RDD из
Transformations (e.g. map, filter, groupBy, join)
Ленивые операции, которые строят RDD из

Автономные программы могут быть написаны на любом из трех языков, но
Автономные программы могут быть написаны на любом из трех языков, но

Главная точка входа в функциональность Spark
Создан для вас в Spark shell
Главная точка входа в функциональность Spark
Создан для вас в Spark shell
![# Превратить локальную коллекцию в RDD sc.parallelize ([1, 2, 3])](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/379293/slide-68.jpg)
# Превратить локальную коллекцию в RDD
sc.parallelize ([1, 2, 3])
# Загрузить текстовый
# Превратить локальную коллекцию в RDD sc.parallelize ([1, 2, 3]) # Загрузить текстовый
![nums = sc.parallelize ([1, 2, 3]) # Пропустить каждый элемент](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/379293/slide-69.jpg)
nums = sc.parallelize ([1, 2, 3])
# Пропустить каждый элемент через функцию
squares
nums = sc.parallelize ([1, 2, 3]) # Пропустить каждый элемент через функцию squares
![nums = sc.parallelize([1, 2, 3]) # Взять значение RDD в](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/379293/slide-70.jpg)
nums = sc.parallelize([1, 2, 3])
# Взять значение RDD в локальную переменную
nums.collect()
nums = sc.parallelize([1, 2, 3])
# Взять значение RDD в локальную переменную
nums.collect()

Быстрая, выразительная кластерная вычислительная система, совместимая с Apache Hadoop
Работает с любой
Быстрая, выразительная кластерная вычислительная система, совместимая с Apache Hadoop
Работает с любой

Заключение
Экосистема Hadoop огромна, и содержит элементы для практически любых нужд;
Hadoop ориентирован
Заключение
Экосистема Hadoop огромна, и содержит элементы для практически любых нужд;
Hadoop ориентирован
 Склеивание цепочек
Склеивание цепочек Модели систем
Модели систем Mail Systems and Business Collaboration. (Week 2)
Mail Systems and Business Collaboration. (Week 2) Представление опыта работы по теме: Использование групповых форм работы на уроке информатики
Представление опыта работы по теме: Использование групповых форм работы на уроке информатики Компьютерные СЕТИ (NETWORKS)
Компьютерные СЕТИ (NETWORKS) Целевая аудитория
Целевая аудитория Технологии создания графических изображений
Технологии создания графических изображений Презентация к уроку Электронная почта
Презентация к уроку Электронная почта Многомерные массивы. Структуры и классы. Лекция 4
Многомерные массивы. Структуры и классы. Лекция 4 Операционные системы и сети. (Лекция 1)
Операционные системы и сети. (Лекция 1) Ветвление. Сравнение чисел, переменных
Ветвление. Сравнение чисел, переменных Weekendagency. Live Fest 2020
Weekendagency. Live Fest 2020 Что такое алгоритм. Последовательность действий
Что такое алгоритм. Последовательность действий Игровые методы в преподавании информатики
Игровые методы в преподавании информатики Моделирование составных документов
Моделирование составных документов Арифметические операции в позиционных системах счисления (4). 8 класс
Арифметические операции в позиционных системах счисления (4). 8 класс 20231229_9kl_tablitsa
20231229_9kl_tablitsa Думай глобально, действуй локально: экологическое сотрудничество библиотеки
Думай глобально, действуй локально: экологическое сотрудничество библиотеки Створення форм за допомогою конструктора форм
Створення форм за допомогою конструктора форм Табличнный процессор
Табличнный процессор Адресация в сетях TCP IP. Доменные имена
Адресация в сетях TCP IP. Доменные имена Автоматизация делопроизводства
Автоматизация делопроизводства Роль информационной деятельности в современном обществе
Роль информационной деятельности в современном обществе Деректерді ұсыну. Мәтіндік ақпараттарды кодтау принциптері
Деректерді ұсыну. Мәтіндік ақпараттарды кодтау принциптері Различные технологии в 3D-печати
Различные технологии в 3D-печати Способы создания таблиц в AutoCAD
Способы создания таблиц в AutoCAD Автоматизация тестирования ДБО
Автоматизация тестирования ДБО Разработка тренажерно - обучающей системы для изучения иностранных языков
Разработка тренажерно - обучающей системы для изучения иностранных языков