Предсказание магнитных свойств наночастиц для биомедицинских применений. Обработка данных презентация
- Предсказание магнитных свойств наночастиц для биомедицинских применений. Обработка данных

Содержание
- 2. Что такое обработка данных в ML проекте? 2 Feature engineering – использование собранных данных для создания
- 3. Feature engineering 3 Алгоритм работает с числовыми векторами Как компьютер поймет химическую формулу? А форму наночастицы?
- 4. Missing data handling 4 Удаление строк (а тем более столбцов) с пропущенными значениями – непозволительная роскошь
- 5. Удаление выбросов 5 Визуально z-score method z имеет нормальное распределение Использование квартилей
- 6. Нормализация данных 6 MinMaxScaler Сохраняем распределение Логарифмирование Позволяет сгладить датасет, особенно если данные различаются на несколько
- 8. Скачать презентацию

Что такое обработка данных в ML проекте?
2
Feature engineering – использование собранных
Что такое обработка данных в ML проекте?
2
Feature engineering – использование собранных
Feature engineering
3
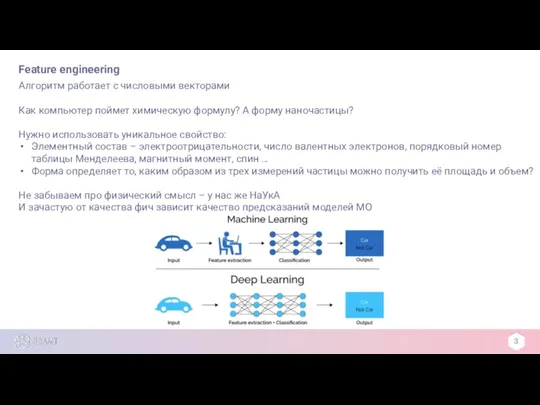
Алгоритм работает с числовыми векторами
Как компьютер поймет химическую формулу? А
Feature engineering
3
Алгоритм работает с числовыми векторами
Как компьютер поймет химическую формулу? А
Missing data handling
4
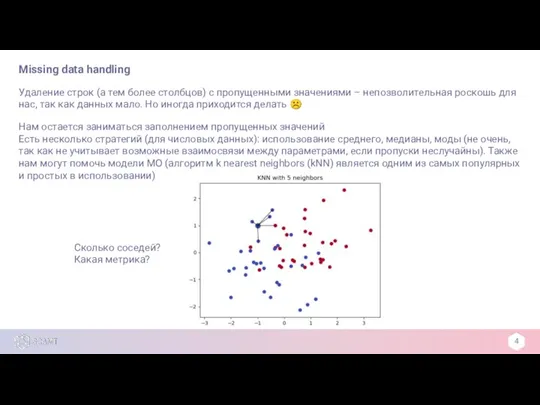
Удаление строк (а тем более столбцов) с пропущенными значениями
Missing data handling
4
Удаление строк (а тем более столбцов) с пропущенными значениями
Удаление выбросов
5
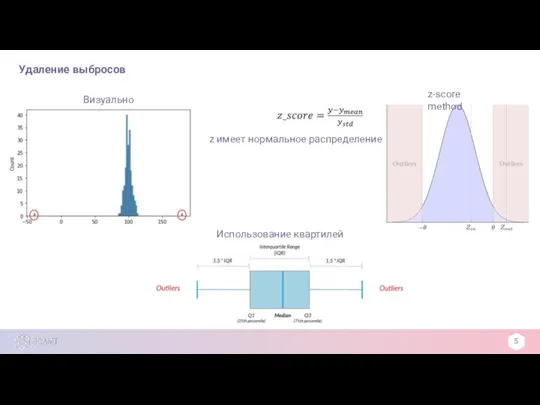
Визуально
z-score method
z имеет нормальное распределение
Использование квартилей
Удаление выбросов
5
Визуально
z-score method
z имеет нормальное распределение
Использование квартилей
Нормализация данных
6
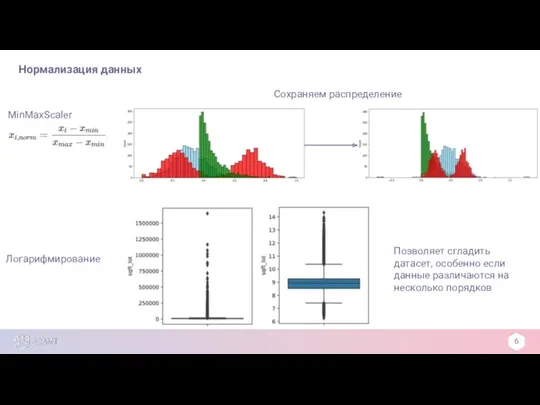
MinMaxScaler
Сохраняем распределение
Логарифмирование
Позволяет сгладить датасет, особенно если данные различаются на несколько
Нормализация данных
6
MinMaxScaler
Сохраняем распределение
Логарифмирование
Позволяет сгладить датасет, особенно если данные различаются на несколько
 Жатыр мойынының рагы және жүктілік
Жатыр мойынының рагы және жүктілік Философия медицины
Философия медицины Что мы знаем о прививках
Что мы знаем о прививках Учение об инфекционном и эпидемическом процессах. (Лекция 3)
Учение об инфекционном и эпидемическом процессах. (Лекция 3) Урологические заболевания
Урологические заболевания Атеросклероз. Этиология
Атеросклероз. Этиология LD
LD Иммунитет. Микробиология
Иммунитет. Микробиология Почечно-клеточный рак
Почечно-клеточный рак Техническое задание на разработку и изготовление образцов одежды из коллекции адаптивной одежды для людей с ОВЗ
Техническое задание на разработку и изготовление образцов одежды из коллекции адаптивной одежды для людей с ОВЗ Болезнь Гамборо, инфекционный бурсит кур, инфекционная бурсальная болезнь
Болезнь Гамборо, инфекционный бурсит кур, инфекционная бурсальная болезнь Периоды детского возраста таблица
Периоды детского возраста таблица Миокардит: современное состояние проблемы
Миокардит: современное состояние проблемы САП (malleus)
САП (malleus) Қабыну.Анықтамасы.Қабынудың мәні мен биологиялық маңызы, даму заңдылықтары. Қабыну мен иммунитет. Пролифериялық қабыну
Қабыну.Анықтамасы.Қабынудың мәні мен биологиялық маңызы, даму заңдылықтары. Қабыну мен иммунитет. Пролифериялық қабыну Клиникалық эпидемиологияның негізгі ережелері
Клиникалық эпидемиологияның негізгі ережелері murmur
murmur Ортопедиялық стоматологиядағы менеджмент пен маркетинг негізі
Ортопедиялық стоматологиядағы менеджмент пен маркетинг негізі Медицинская и санитарная техника
Медицинская и санитарная техника Организация диетического питания в лечебно-профилактических учреждениях
Организация диетического питания в лечебно-профилактических учреждениях Методы исследования мочевыделительной системы и наружных половых органов
Методы исследования мочевыделительной системы и наружных половых органов Фармакотерапия и химиотерапия
Фармакотерапия и химиотерапия Гемолитико-уремический синдром
Гемолитико-уремический синдром Влияние алкоголя на развитие организма
Влияние алкоголя на развитие организма Электрокардиография. История ЭКГ
Электрокардиография. История ЭКГ Современные подходы к антибактериальной терапии
Современные подходы к антибактериальной терапии Биорезонансная терапия сердечно-сосудистых заболеваний
Биорезонансная терапия сердечно-сосудистых заболеваний Глаукома. Актуальность проблемы глаукомы
Глаукома. Актуальность проблемы глаукомы