- Символьные коды. Префиксные коды

Содержание
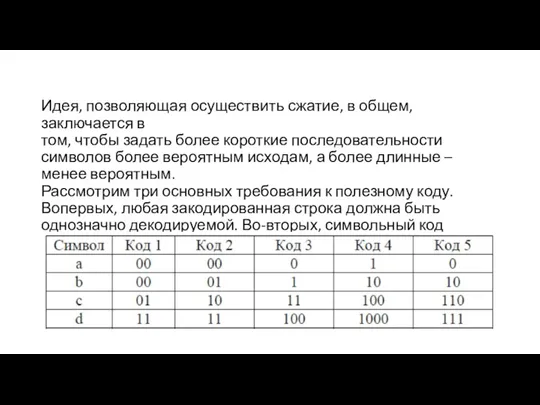
- 2. Идея, позволяющая осуществить сжатие, в общем, заключается в том, чтобы задать более короткие последовательности символов более
- 3. Любая закодированная строка должна быть однозначно декодируемой. Код называется однозначно декодируемым, если любая конечная последовательность кода
- 4. Символьный код, в котором никакое кодовое слово не является префиксом для другого кодового слова, называется префиксным.
- 5. Бинарное дерево для префиксного кода
- 6. Код должен обеспечивать максимально возможное сжатие Средняя длина L(X) символьного для ансамбля X Символьный код с
- 7. Найдём предел кодирования для однозначно декодируемых кодов. Для начала рассмотрим код {00, 01, 10, 11}. •
- 8. Наилучшее достижимое сжатие Ожидаемая длина уникально декодируемого кода ограничена снизу энтропией H(X).
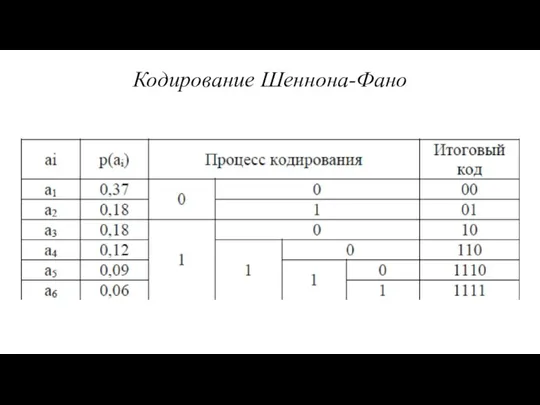
- 9. Оптимальное кодирование Шеннона В кодировании Шеннона символы располагаются в порядке от наиболее вероятных к наименее вероятным.
- 10. Код строится следующим образом. Кодируемые знаки выписывают в таблицу в порядке убывания их вероятностей в сообщениях.
- 11. Кодирование Шеннона-Фано
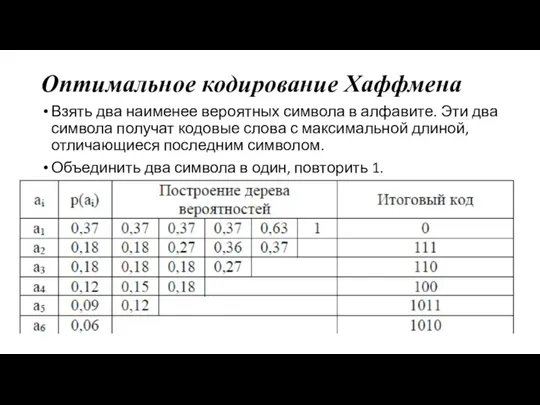
- 12. Оптимальное кодирование Хаффмена Взять два наименее вероятных символа в алфавите. Эти два символа получат кодовые слова
- 13. Кодирование Хаффмена Кодируемые знаки, также как при использовании метода Шеннона-Фано, располагают в порядке убывания их вероятностей.
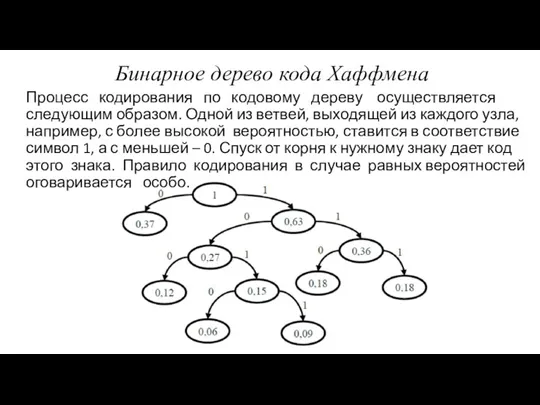
- 14. Бинарное дерево кода Хаффмена Процесс кодирования по кодовому дереву осуществляется следующим образом. Одной из ветвей, выходящей
- 15. Блочное кодирование Если величина среднего числа символов на знак оказывается значительно большей, чем энтропия, то это
- 16. Блочное кодирование Можно проверить, что при кодировании блоками по три символа среднее число символов на знак
- 17. Арифметическое кодирование Арифметическое кодирование (англ. Arithmetic coding) — алгоритм сжатия информации без потерь, который при кодировании
- 18. Кодирование На вход алгоритму передаются текст для кодирования и список частот встречаемости символов. 1. Рассмотрим отрезок
- 20. Декодирование Алгоритм по вещественному числу восстанавливает исходный текст. 1. Выберем на отрезке [0; 1), разделенном на
- 21. Гамма-код Гамма-код Элиаса — это универсальный код для кодирования положительных целых чисел, разработанный Питером Элиасом. Он
- 22. Гамма-код Элиаса
- 23. Дельта-код Дельта-код Элиаса — это модификация гамма-кода Элиаса, в котором число разрядов двоичного представления числа, в
- 25. Омега-код (рекурсивный код) Элиаса Так же, как гамма- и дельта-код Элиаса, он приписывает к началу целого
- 26. Алгоритм декодирования омега -кода Элиаса 1. Начать с переменной N, установленной в значение 1. 2. Считать
- 28. Словарные коды Алгоритм LZW Алгоритм Лемпеля — Зива — Велча (Lempel-Ziv-Welch, LZW) — это универсальный алгоритм
- 29. Например, если сжимают байтовые данные (текст), то строк в таблице окажется 256 (от «0» до «255»).
- 30. Псевдокод алгоритма 1. Инициализация словаря всеми возможными односимвольными фразами. Инициализация входной фразы ω первым символом сообщения.
- 31. Пример кодирования Пусть мы сжимаем последовательность «abacabadabacabae». Шаг 1: Тогда, согласно изложенному выше алгоритму, мы добавим
- 32. В поток: ; Шаг 7: “ad” — нет. В таблицу: “ad”. В поток: ; Шаг 8:
- 34. Декодирование Особенность LZW заключается в том, что для декомпрессии нам не надо сохранять таблицу строк в
- 36. + Не требует вычисления вероятностей встречаемости символов или кодов. + Для декомпрессии не надо сохранять таблицу
- 38. Скачать презентацию
Идея, позволяющая осуществить сжатие, в общем, заключается в
том, чтобы задать более
Идея, позволяющая осуществить сжатие, в общем, заключается в
том, чтобы задать более

Любая закодированная строка должна быть однозначно декодируемой.
Код называется однозначно декодируемым,
Любая закодированная строка должна быть однозначно декодируемой.
Код называется однозначно декодируемым,

Символьный код, в котором никакое кодовое слово не является
префиксом для другого
Символьный код, в котором никакое кодовое слово не является
префиксом для другого

Бинарное дерево для префиксного кода
Бинарное дерево для префиксного кода

Код должен обеспечивать максимально возможное сжатие
Средняя длина L(X) символьного для ансамбля
Код должен обеспечивать максимально возможное сжатие
Средняя длина L(X) символьного для ансамбля

Найдём предел кодирования для однозначно декодируемых
кодов.
Для начала рассмотрим код {00, 01,
Найдём предел кодирования для однозначно декодируемых
кодов.
Для начала рассмотрим код {00, 01,

Наилучшее достижимое сжатие
Ожидаемая длина уникально декодируемого кода ограничена
снизу энтропией H(X).
Наилучшее достижимое сжатие
Ожидаемая длина уникально декодируемого кода ограничена
снизу энтропией H(X).

Оптимальное кодирование Шеннона
В кодировании Шеннона символы располагаются в порядке от
Оптимальное кодирование Шеннона
В кодировании Шеннона символы располагаются в порядке от

Код строится следующим образом. Кодируемые знаки выписывают в таблицу в порядке
Код строится следующим образом. Кодируемые знаки выписывают в таблицу в порядке
Кодирование Шеннона-Фано
Кодирование Шеннона-Фано
Оптимальное кодирование Хаффмена
Взять два наименее вероятных символа в алфавите. Эти
Оптимальное кодирование Хаффмена
Взять два наименее вероятных символа в алфавите. Эти

Кодирование Хаффмена
Кодируемые знаки, также как при использовании метода Шеннона-Фано, располагают
Кодирование Хаффмена
Кодируемые знаки, также как при использовании метода Шеннона-Фано, располагают
Бинарное дерево кода Хаффмена
Процесс кодирования по кодовому дереву осуществляется следующим образом.
Бинарное дерево кода Хаффмена
Процесс кодирования по кодовому дереву осуществляется следующим образом.

Блочное кодирование
Если величина среднего числа символов на знак оказывается значительно
Блочное кодирование
Если величина среднего числа символов на знак оказывается значительно

Блочное кодирование
Можно проверить, что при кодировании блоками по три символа
Блочное кодирование
Можно проверить, что при кодировании блоками по три символа

Арифметическое кодирование
Арифметическое кодирование (англ. Arithmetic coding) — алгоритм сжатия информации
Арифметическое кодирование
Арифметическое кодирование (англ. Arithmetic coding) — алгоритм сжатия информации

Кодирование
На вход алгоритму передаются текст для кодирования и список
частот встречаемости
Кодирование
На вход алгоритму передаются текст для кодирования и список
частот встречаемости


Декодирование
Алгоритм по вещественному числу восстанавливает исходный текст.
1. Выберем на отрезке
Декодирование
Алгоритм по вещественному числу восстанавливает исходный текст.
1. Выберем на отрезке

Гамма-код
Гамма-код Элиаса — это универсальный код для кодирования положительных целых
Гамма-код
Гамма-код Элиаса — это универсальный код для кодирования положительных целых
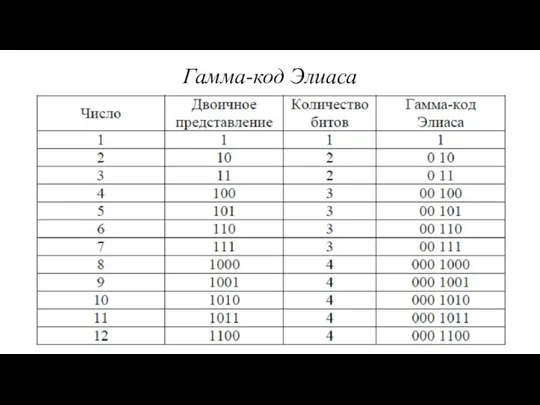
Гамма-код Элиаса
Гамма-код Элиаса

Дельта-код
Дельта-код Элиаса — это модификация гамма-кода Элиаса, в котором число
Дельта-код
Дельта-код Элиаса — это модификация гамма-кода Элиаса, в котором число


Омега-код (рекурсивный код) Элиаса
Так же, как гамма- и дельта-код Элиаса,
Омега-код (рекурсивный код) Элиаса
Так же, как гамма- и дельта-код Элиаса,

Алгоритм декодирования омега -кода Элиаса
1. Начать с переменной N, установленной в
Алгоритм декодирования омега -кода Элиаса
1. Начать с переменной N, установленной в


Словарные коды
Алгоритм LZW
Алгоритм Лемпеля — Зива — Велча (Lempel-Ziv-Welch,
Словарные коды
Алгоритм LZW
Алгоритм Лемпеля — Зива — Велча (Lempel-Ziv-Welch,

Например, если сжимают байтовые данные (текст), то строк в таблице окажется
Например, если сжимают байтовые данные (текст), то строк в таблице окажется

Псевдокод алгоритма
1. Инициализация словаря всеми возможными односимвольными фразами. Инициализация входной фразы
Псевдокод алгоритма
1. Инициализация словаря всеми возможными односимвольными фразами. Инициализация входной фразы

Пример кодирования
Пусть мы сжимаем последовательность «abacabadabacabae».
Шаг 1: Тогда, согласно изложенному выше
Пример кодирования
Пусть мы сжимаем последовательность «abacabadabacabae».
Шаг 1: Тогда, согласно изложенному выше

В поток: <5>;
Шаг 7: “ad” — нет. В таблицу: <10> “ad”.
В поток: <5>;
Шаг 7: “ad” — нет. В таблицу: <10> “ad”.


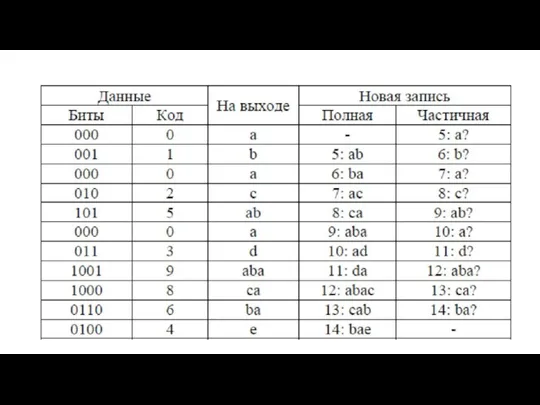
Декодирование
Особенность LZW заключается в том, что для декомпрессии нам не
Декодирование
Особенность LZW заключается в том, что для декомпрессии нам не

+ Не требует вычисления вероятностей встречаемости символов или кодов.
+ Для декомпрессии
+ Не требует вычисления вероятностей встречаемости символов или кодов.
+ Для декомпрессии
 Технология объектно-ориентированного проектирования ИС (разработки программного обеспечения) – Rational Unified Process (RUP)
Технология объектно-ориентированного проектирования ИС (разработки программного обеспечения) – Rational Unified Process (RUP) Объектно-ориентированное программирование. Практические работы Pascal ABC
Объектно-ориентированное программирование. Практические работы Pascal ABC Программа Figma
Программа Figma Руководство пользователя для онлайн-курса ГПА
Руководство пользователя для онлайн-курса ГПА Интерактивная презентация для цикла уроков в 10 классе Создание Веб-сайта. Язык HTML. ;2.
Интерактивная презентация для цикла уроков в 10 классе Создание Веб-сайта. Язык HTML. ;2. Экскурсия по виртуальному музею Компьютерной графики (Office 2007)
Экскурсия по виртуальному музею Компьютерной графики (Office 2007) Линии связи
Линии связи Компьютерные технологии интеллектуальной поддержки управленческих решений
Компьютерные технологии интеллектуальной поддержки управленческих решений Управление ремонтами и обслуживанием оборудования. Решение на основе 1С:Предприятие 8
Управление ремонтами и обслуживанием оборудования. Решение на основе 1С:Предприятие 8 Functions are objects. Main concepts behind Python functions
Functions are objects. Main concepts behind Python functions Training Manual
Training Manual Стиснення та архівування даних
Стиснення та архівування даних Розробка клієнтського програмного забезпечення для корпоративних додатків на платформі Java
Розробка клієнтського програмного забезпечення для корпоративних додатків на платформі Java Welcome. Anti-virus
Welcome. Anti-virus Системы счисления. Позиционные и непозиционные системы
Системы счисления. Позиционные и непозиционные системы Стандартизация программного обеспечения
Стандартизация программного обеспечения Решения для электронного правительства и электронизация государственных услуг — БАРС Груп
Решения для электронного правительства и электронизация государственных услуг — БАРС Груп Моделирование и формализация
Моделирование и формализация Управление в логистических информационных системах (Информационные системы планирования и управления ресурсами предприятия)
Управление в логистических информационных системах (Информационные системы планирования и управления ресурсами предприятия) Работа с VirtualBox, установка рабочих станций и подготовка для включения в одноранговую сеть
Работа с VirtualBox, установка рабочих станций и подготовка для включения в одноранговую сеть Lazarus. Порядок создания приложения
Lazarus. Порядок создания приложения Школьная газета АстраWork
Школьная газета АстраWork Робототехніка на основі Arduino
Робототехніка на основі Arduino Programming logic and design seventh edition. Chapter 5. Looping
Programming logic and design seventh edition. Chapter 5. Looping Инструкция по заполнению регистрационной формы конференции
Инструкция по заполнению регистрационной формы конференции Метод PERT и управление проектами
Метод PERT и управление проектами Модели данных
Модели данных Технічні і програмні засоби КС реального часу. (Тема 10)
Технічні і програмні засоби КС реального часу. (Тема 10)