- Lesson 2 and 3. The chemistry of life

Содержание
- 2. Carbohydrates are large biological molecules, or macromolecules, consisting of carbon (C), hydrogen (H), and oxygen (O)
- 4. The difference is based on the fact that there are actually two slightly different ring structures
- 5. Disaccharides consist of two monosaccharides joined by a glycosidic linkage, a covalent bond formed between two
- 6. Polysaccharides are macromolecules, polymers with a few hundred to a few thousand monosaccharides joined by glycosidic
- 7. Organisms build strong materials from structural polysaccharides. For example, the polysaccharide called cellulose is a major
- 8. Lipids are the one class of large biological molecules that does not include true polymers, and
- 9. Phospholipids. A phospholipid is similar to a fat molecule but has only two fatty acids attached
- 10. Steroids are lipids characterized by a carbon skeleton consisting of four fused rings. Different steroids, such
- 11. The chemistry of life: proteins and nucleic acids
- 12. A protein is a biologically functional molecule that consists of one or more polypeptides, each folded
- 13. Рeptide bond. Read the text below, draw the scheme of a polypeptide chain and mark the
- 14. All proteins share three superimposed levels of structure, known as primary, secondary, and tertiary structure. A
- 15. Most proteins have segments of their polypeptide chains repeatedly coiled or folded in patterns that contribute
- 16. Tertiary structure refers to the three-dimensional structure of a single, double, or triple bonded protein molecule.
- 17. Some proteins consist of two or more polypeptide chains aggregated into one functional macromolecule. Quaternary structure
- 18. Levels of protein structure
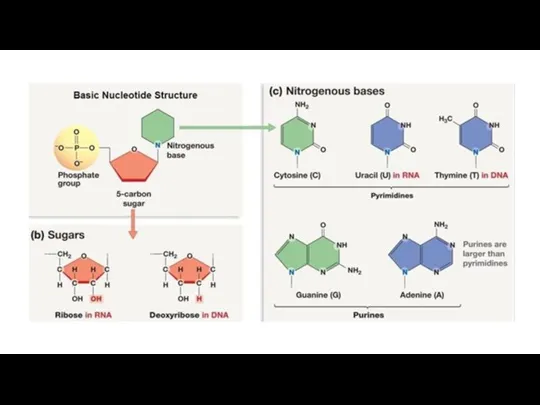
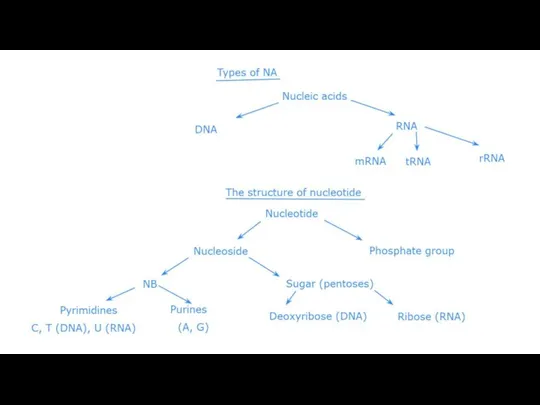
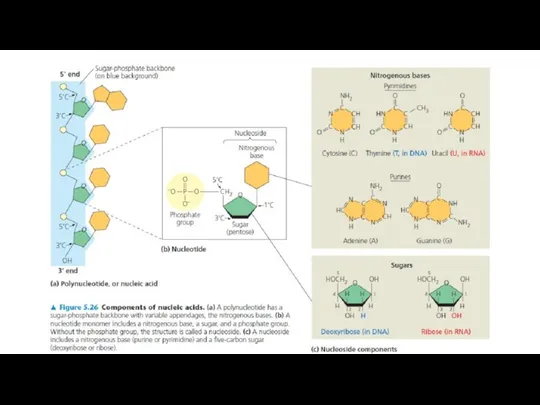
- 23. Read the text below, write down the definition of nucleic acids and nucleotides. Draw the scheme
- 25. deoxyribonucleotide
- 26. Bases attached to a sugar is called nucleoside. Sugar + phosphate + base = nucleotide. DNA
- 28. Adjacent nucleotides are joined by a phosphodiester linkage, which consists of a phosphate group that links
- 29. According to the Watson-Crick model of a DNA molecule consists of two polynucleotide chains forming a
- 30. Base Pairing 3 Hydrogen bonds . . . . . . . . .
- 31. Base Pairing 2 Hydrogen bonds . . . . . .
- 32. A always pairs with T in DNA. C also pairs with G in DNA. The amount
- 35. Скачать презентацию

Carbohydrates are large biological molecules, or macromolecules, consisting of carbon (C),
hydrogen
Carbohydrates are large biological molecules, or macromolecules, consisting of carbon (C),
hydrogen
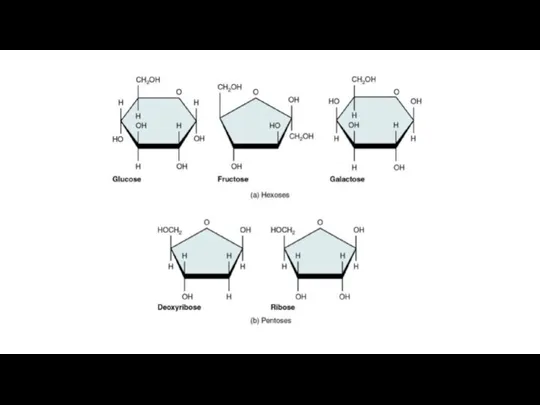

The difference is based on the fact that there are actually
The difference is based on the fact that there are actually
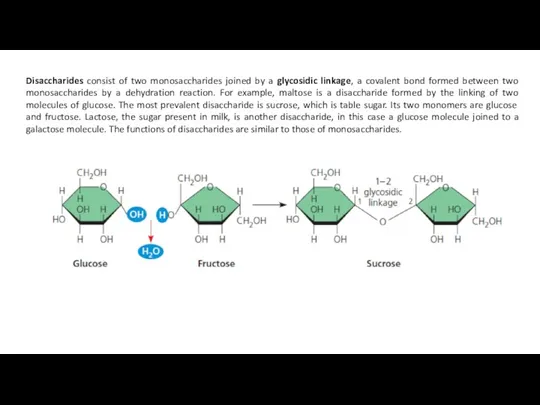
Disaccharides consist of two monosaccharides joined by a glycosidic linkage, a
Disaccharides consist of two monosaccharides joined by a glycosidic linkage, a

Polysaccharides are macromolecules, polymers with a few hundred to a few
Polysaccharides are macromolecules, polymers with a few hundred to a few

Organisms build strong materials from structural polysaccharides. For example, the polysaccharide
Organisms build strong materials from structural polysaccharides. For example, the polysaccharide

Lipids are the one class of large biological molecules that does
Lipids are the one class of large biological molecules that does
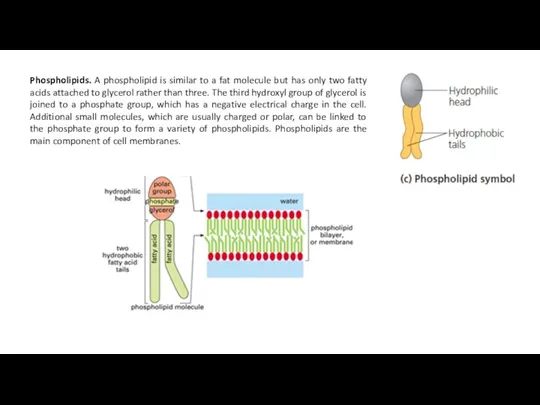
Phospholipids. A phospholipid is similar to a fat molecule but has
Phospholipids. A phospholipid is similar to a fat molecule but has

Steroids are lipids characterized by a carbon skeleton consisting of four
Steroids are lipids characterized by a carbon skeleton consisting of four

The chemistry of life: proteins and nucleic acids
The chemistry of life: proteins and nucleic acids
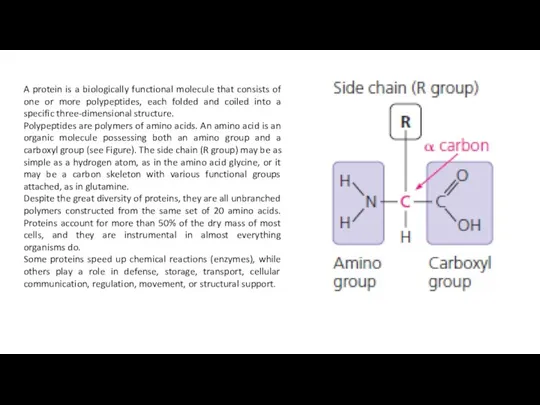
A protein is a biologically functional molecule that consists of one
A protein is a biologically functional molecule that consists of one
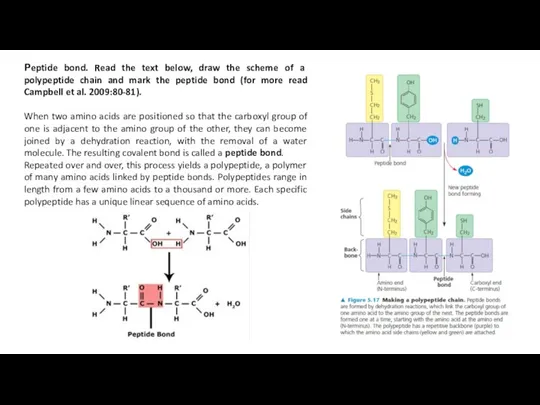
Рeptide bond. Read the text below, draw the scheme of a
Рeptide bond. Read the text below, draw the scheme of a

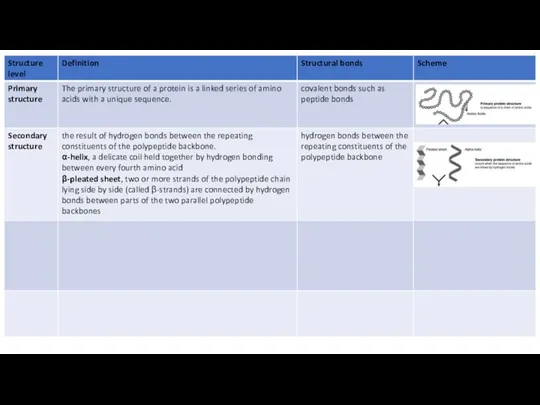
All proteins share three superimposed levels of structure, known as primary,
All proteins share three superimposed levels of structure, known as primary,

Most proteins have segments of their polypeptide chains repeatedly coiled or
Most proteins have segments of their polypeptide chains repeatedly coiled or

Tertiary structure refers to the three-dimensional structure of a single, double,
Tertiary structure refers to the three-dimensional structure of a single, double,

Some proteins consist of two or more polypeptide chains aggregated into
Some proteins consist of two or more polypeptide chains aggregated into
Levels of protein structure
Levels of protein structure



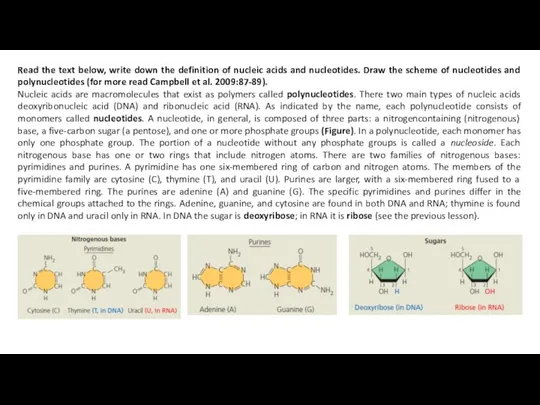
Read the text below, write down the definition of nucleic acids
Read the text below, write down the definition of nucleic acids
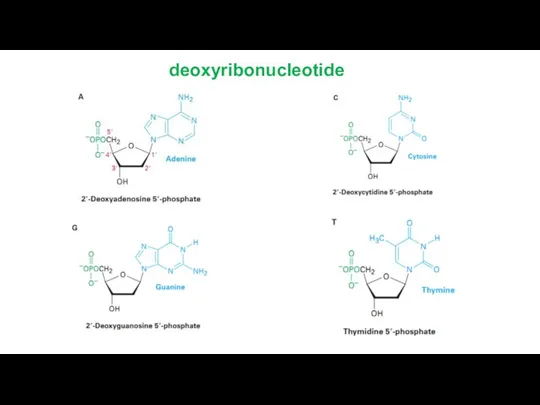
deoxyribonucleotide
deoxyribonucleotide

Bases attached to a sugar is called nucleoside.
Sugar + phosphate
Sugar + phosphate
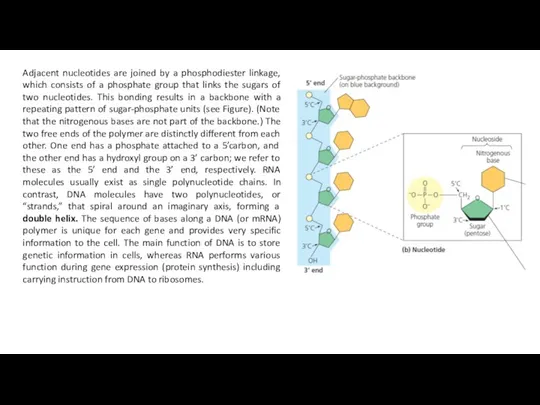
Adjacent nucleotides are joined by a phosphodiester linkage, which consists of
Adjacent nucleotides are joined by a phosphodiester linkage, which consists of

According to the Watson-Crick model of a DNA molecule consists of
According to the Watson-Crick model of a DNA molecule consists of
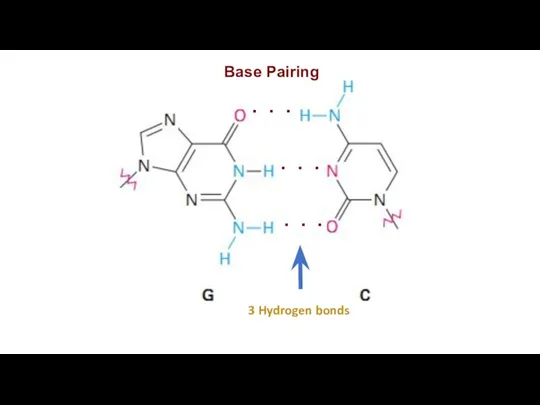
Base Pairing
3 Hydrogen bonds
. . .
. . .
. . .
Base Pairing
3 Hydrogen bonds
. . .
. . .
. . .
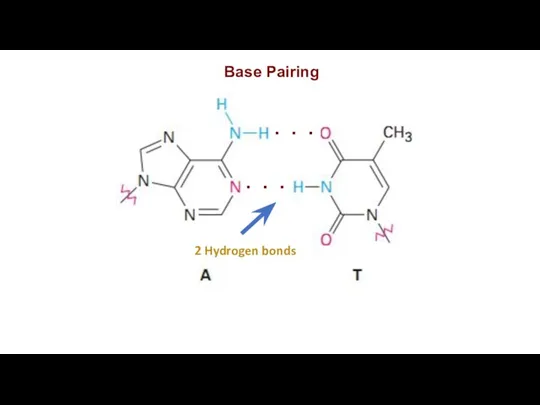
Base Pairing
2 Hydrogen bonds
. . .
. . .
Base Pairing
2 Hydrogen bonds
. . .
. . .
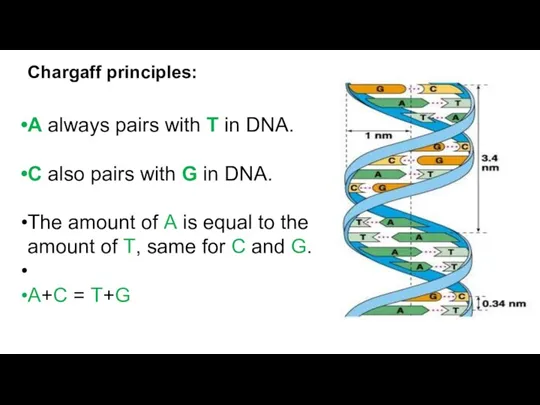
A always pairs with T in DNA.
C also pairs with
C also pairs with
 Отчет по исследовательской работе Образование АСПО
Отчет по исследовательской работе Образование АСПО Газовые законы для идеальных и реальных газов. Лекция 1
Газовые законы для идеальных и реальных газов. Лекция 1 Виявлення в розчині гідроксид-іонів та йонів Гідрогену. Якісні реакції на деякі йони. Застосування якісних реакцій
Виявлення в розчині гідроксид-іонів та йонів Гідрогену. Якісні реакції на деякі йони. Застосування якісних реакцій Обмен жиров в организме
Обмен жиров в организме Анализ проб воды
Анализ проб воды Алканы. Получение, свойства и применение
Алканы. Получение, свойства и применение Минералы и горные породы
Минералы и горные породы Строение и переваривание липидов. Классификация и роль жирных кислот. Нутриомика. Липофильных соединений
Строение и переваривание липидов. Классификация и роль жирных кислот. Нутриомика. Липофильных соединений Химическое равновесие
Химическое равновесие Классификация химических элементов в географической оболочке
Классификация химических элементов в географической оболочке История развития органической химии. Теория Бутлерова
История развития органической химии. Теория Бутлерова Хімічна кінетика
Хімічна кінетика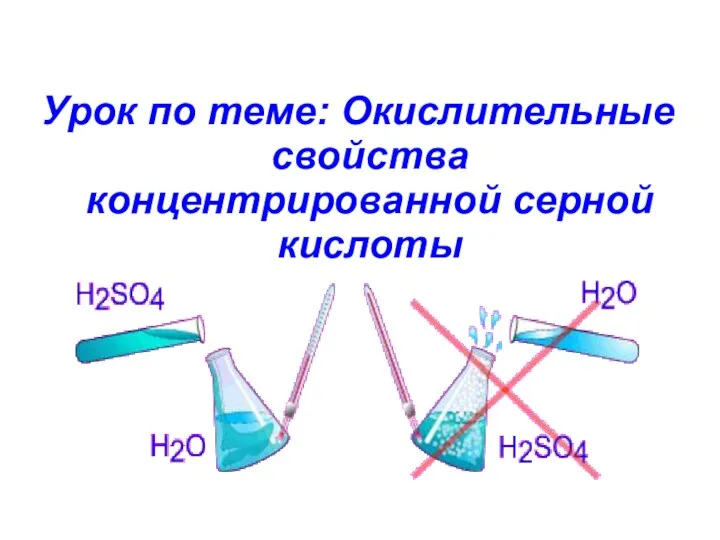 Окислительные свойства концентрированной серной кислоты
Окислительные свойства концентрированной серной кислоты Бейорганикалық химия туралы
Бейорганикалық химия туралы Аміни
Аміни Витамины
Витамины Теория электролитической диссоциации (ТЭД)
Теория электролитической диссоциации (ТЭД) Горные породы и минералы
Горные породы и минералы Химическая связь
Химическая связь Процессы и технологическая схема производства сегодня. АО Газпромнефть-ОНПЗ
Процессы и технологическая схема производства сегодня. АО Газпромнефть-ОНПЗ Общая химия
Общая химия Углерод и его свойства
Углерод и его свойства Кислород. Строение молекулы кислорода. Получение кислорода. Взаимодействие с кислородом простых и сложных веществ
Кислород. Строение молекулы кислорода. Получение кислорода. Взаимодействие с кислородом простых и сложных веществ Химия и сельское хозяйство
Химия и сельское хозяйство Положение тугоплавких металлов в Периодической системе элементов
Положение тугоплавких металлов в Периодической системе элементов Обмен жиров
Обмен жиров Особенности сжигания газообразного топлива и топливосжигающие устройства
Особенности сжигания газообразного топлива и топливосжигающие устройства Фунгициды. Достоинства и недостати
Фунгициды. Достоинства и недостати